
Una veloce incursione nella sfera dei databse NoSQL.

NoSQL è un movimento che promuove sistemi software dove la persistenza dei dati è in generale caratterizzata dal fatto di non utilizzare il modello relazionale, di solito usato dalle basi di dati tradizionali (RDBMS).
L’espressione fa infatti riferimento al linguaggio SQL, che è il più comune linguaggio di interrogazione dei dati nei database relazionali, qui preso a simbolo dell’intero paradigma relazionale.
Questi archivi di dati il più delle volte non richiedono uno schema fisso (schemeless), evitano spesso le operazioni di giunzione (join) e puntano a scalare in modo orizzontale. Gli accademici e gli articoli si riferiscono a queste basi di dati come memorizzazione strutturata (structured storage).
I creatori di MongoDB, il database non relazionale più popolare, individuano queste cause nell’affermarsi di database NoSQL:
- Le richieste di maggiore produttività e tempi di commercializzazione più rapidi sono frenate da rigidi modelli di dati relazionali che non corrispondono al codice moderno e impongono complesse interdipendenze tra i team di progettazione.
- Le organizzazioni non sono in grado di lavorare ed estrarre informazioni dai massicci aumenti dei nuovi dati strutturati, semistrutturati e polimorfici in rapida evoluzione generati dalle applicazioni odierne.
- I vecchi (legacy) database monolitici e fragili inibiscono il passaggio estensivo a sistemi distribuiti e cloud computing che forniscono la resilienza e la scalabilità di cui le aziende hanno bisogno, rendendo più difficile soddisfare i nuovi requisiti normativi per la privacy dei dati.
- I carichi di lavoro transazionali, analitici, di ricerca e mobili precedentemente separati stanno convergendo per creare applicazioni ricche e basate sui dati e sulle esperienze degli utilizzatori. Tuttavia, ogni carico di lavoro è stato tradizionalmente alimentato dal proprio database, creando silos di dati duplicati connessi con fragili pipeline ETL a cui si accede da diverse API di sviluppatori.
Processi ETL di esempio possono essere:
- Migrazione dei dati da un’applicazione a un’altra
- Replica dei dati per l’esecuzione di backup o analisi della ridondanza
- Processi operativi quali il trasferimento di dati da un sistema CRM in un ODS (Operational Data Store) per l’ottimizzazione e l’arricchimento, per poi restituire i dati al sistema CRM
- Inserimento dei dati in un Data Warehouse per l’assimilazione, l’ordinamento e la trasformazione in business intelligence
- Migrazione delle applicazioni locali in infrastrutture Cloud, Cloud ibride o multi-Cloud
- Sincronizzazione di sistemi chiave
Vengono formulate anche considerazioni critiche basate su alcune dimensioni che definiscono questi sistemi:
- modello di dati;
- modello di interrogazione;
- consistenza e modello transazionale;
- API;
- dati mobili;
- piattaforma dati e supporto commerciale,
- forza della comunità e
- libertà dal lock-in (abilità di non chiudersi dentro ad una soluzione che non cresce).
Sommario
Modello di dati per database NoSQL
Il modo principale in cui i database non tabulari differiscono dai database relazionali è il modello di dati. Sebbene ci siano dozzine di database non tabulari, essi generalmente rientrano in tre categorie:
- database di documenti,
- database di grafi e
- database chiave-valore o archivi a colonne larghe.
Modello documentale
Mentre i database relazionali archiviano i dati in righe e colonne, i database di documenti archiviano i dati in documenti utilizzando JavaScript Object Notation (JSON), un formato di scambio dati basato su testo popolare tra gli sviluppatori. I documenti forniscono un modo intuitivo e naturale per modellare i dati che è strettamente allineato con la programmazione orientata agli oggetti: ogni documento è effettivamente un oggetto che corrisponde agli oggetti con cui gli sviluppatori lavorano nel codice.
I documenti contengono uno o più campi e ogni campo contiene un valore digitato come una stringa, una data, un valore binario, decimale o una matrice. Anziché distribuire un record su più colonne e tabelle collegate a chiavi esterne, ogni record viene archiviato insieme ai dati associati (ovvero correlati) in un unico documento gerarchico.
Questo modello accelera la produttività degli sviluppatori, semplifica l’accesso ai dati e, in molti casi, elimina la necessità di costose operazioni di join e livelli di astrazione complessi come il mapping relazionale degli oggetti (ORM).
Lo schema di un database relazionale è definito da tabelle; in un database di documenti, la nozione di schema è dinamica: ogni documento può contenere campi diversi. Questa flessibilità può essere particolarmente utile per la modellazione dei dati in cui le strutture possono cambiare da un record all’altro, ad esempio dati polimorfici.
Inoltre, diventa più semplice l’evoluzione di un’applicazione durante il suo ciclo di vita, ad esempio se si devono aggiungere nuovi campi. Inoltre, alcuni database di documenti forniscono l’espressività delle query che gli sviluppatori si aspettano dai database relazionali.
In particolare, i dati possono essere interrogati in base a qualsiasi combinazione di campi in un documento, con ricchi indici secondari che forniscono percorsi di accesso efficienti per supportare quasi tutti i modelli di query. Alcuni database di documenti offrono anche la possibilità di applicare uno schema ai documenti.
Applicazioni
I database di documenti sono utili per un’ampia varietà di applicazioni grazie alla flessibilità del modello di dati, alla capacità di eseguire query su qualsiasi campo e alla mappatura naturale del modello di dati del documento agli oggetti nei moderni linguaggi di programmazione.
Esempi
MongoDB, Azure CosmosDB, Apache CouchDB
Nella sostanza, per visualizzare un database i tipo documentale, l’unico modo è stampare i file JSON contente gli archivi. Questo esempio è tratto da miaplatfrom.eu:


Modello a grafi
I database di grafi utilizzano strutture di grafi con nodi, bordi e proprietà per rappresentare i dati. In sostanza, i dati sono modellati come una rete di relazioni tra elementi specifici. Sebbene il modello a grafi possa essere controintuitivo, può essere utile per una classe specifica di query. Il suo principale vantaggio è che semplifica la modellazione e la navigazione delle relazioni tra le entità in un’applicazione.
Applicazioni
I database di grafi sono utili nei casi in cui l’attraversamento delle relazioni è fondamentale per l’applicazione, come la navigazione nelle connessioni di social network, nelle topologie di rete o nelle catene di approvvigionamento.
Esempi
Neo4j, Amazon Neptune
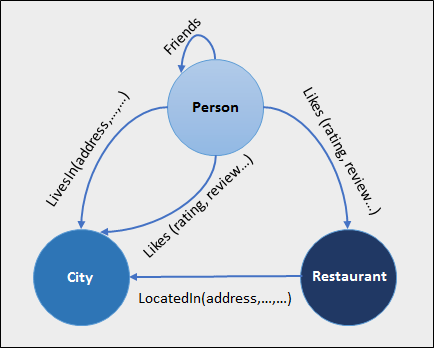
In sostanza i nodi sono tabelle normali dichiarate come node (AS NODE), le relazioni sono anch’esse tabelle (come le tabelle di join) dichiarate come edge (AS EDGE). Si chiamano anche tabelle di bordo, o tabelle perimetrali.
Il seguente esempio è tratto da Microsoft:
Database chiave-valore e modelli a colonna larga
Dal punto di vista del modello dati, i database chiave-valore sono il tipo più elementare di database non tabulare. Ogni elemento nel database viene memorizzato come nome di attributo o chiave, insieme al suo valore. Il valore, tuttavia, è completamente opaco per il sistema: i dati possono essere interrogati solo dalla chiave. Questo modello può essere utile per rappresentare dati polimorfici e non strutturati, perché il database non impone uno schema impostato tra coppie chiave-valore.
Gli archivi a colonne larghe, o archivi di famiglie di colonne, utilizzano una mappa ordinata sparsa, distribuita e multidimensionale per archiviare i dati. Ogni record può variare nel numero di colonne memorizzate. Le colonne possono essere raggruppate in famiglie di colonne o distribuite su più famiglie. I dati vengono recuperati dalla chiave primaria per famiglia di colonne.
Applicazioni
I database a chiave-valore e gli archivi a colonne larghe sono utili per un set specializzato di applicazioni che eseguono query sui dati utilizzando un singolo valore di chiave. L’attrattiva di questi sistemi è la loro prestazione e scalabilità, che possono essere altamente ottimizzate grazie alla semplicità dei modelli di accesso ai dati e all’opacità dei dati stessi.
Esempi
Redis, Amazon DynamoDB (key-value); Apache HBase, Apache Cassandra (wide-column)
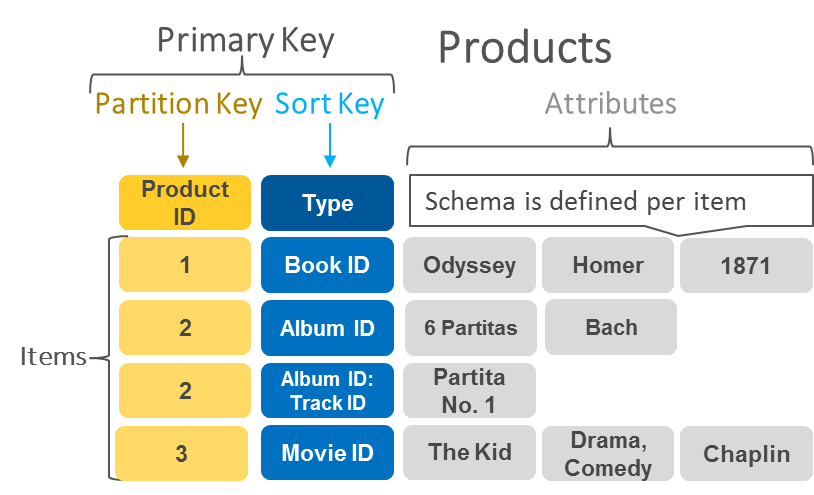
Per esempio il seguente database chiave-valore è tratto AmazonWS:
Punti chiave
- I modelli di dati chiave-valore e a colonna ampia sono opachi nel sistema: è possibile eseguire query solo sulla chiave primaria (ad esempio non si può cercare nel testo).
- Il modello dati documentale ha la più ampia applicabilità.
- Il modello a colonne larghe fornisce un accesso più granulare ai dati rispetto al modello chiave-valore, ma è meno flessibile rispetto al modello documento.
- Il modello dati documentale è il più naturale e produttivo perché mappa direttamente gli oggetti nei linguaggi OO.
Bibliografia
- NoSQL su Wikipedia
- MongoDB: Top 7 Considerations When Evaluating NoSQL Databases
- Talend.com
- Esempio di progetto di database documentale (html.it)
- Esempio di modello documentale (miaplatform.eu)
- Esempio di progetto di database e grafi (microsoft.com)
- Esempio di progetto di database chiave-valore (amazon.com)
Commenti recenti