
Sommario
Come funziona un router?
Il routing (o instradamento) è il processo di inviare pacchetti IP da una rete ad un altra. Un router è un dispositivo che possiede almeno due schede di rete (NIC o Network Interface Controller), una fisicamente collegata da una rete, e l’altra collegata all’altra rete. Un router può collegare qualsiasi numero di reti, basta che abbia a bordo un egual numero di schede di rete.

Se si hanno due reti basta un router ed è estremamente semplice configurarlo. Quando però ci muoviamo verso reti più grandi, le cose si fanno un po’ più complicate. Per esempio, se volessimo collegare tre reti possiamo collegarle in due modi diversi: il primo è in daisy chain (collana di margherite; in italiano rende di più “in fila indiana”) con due soli router. Un altro modo è collegarle direttamente usando tre router.

Nella configurazione 1, se il router A non funziona più, nessuna macchina della sottorete A riuscirà più a comunicare con la sottorete C (oltre che con la rete B) perché c’è un unico percorso che li collega. Ma se aggiungiamo un altro router tra le sottoreti A e C (configurazione 2), avremo due percorsi tra A e C che rendono la rete pià efficiente.
Metrica
I router non solo smistano il traffico cerso altre sottoreti, ma imparano anche qual è il percorso più veloce e lo usano per primo. Usando per esempio la configurazione 2 sopra , la sottorete A può connettersi alla sottorete C attraverso due percorsi: uno direttamente attraverso il router C (1 hop, cioè 1 salto) e uno attraverso i router A e B (2 salti). Quando si invia traffico dalla sottorete A alla sottorete C, vorremmo ovviamente andare direttamente passando per il router C. Questa è la rotta più veloce e più efficiente, ma come fa a saperlo il router? Lo sa perché usa una informazione chiamata valore metrico, o metrica. Ogni rotta che il router conosce ha un valore di metrica ad essa assegnata. Una metrica è fondamentalmente un indice di preferenza. Se ci sono due strade per la stessa destinazione, allora quella con metrica più bassa verrà ritenuta la più efficiente. I router usano sempre questa rotta finché non fallisce, nel qual caso useranno la rotta con il prossimo indice metrico più basso e così via. I router conservano tutte queste informazioni in una tabella di routing di cui ci occuperemo nella Puntata 3 – La tabella di routing.
Il protocollo di routing
Nella comunicazione tra due punti di una rete comunque complessa, c’è un protocollo che i router seguono per fare comunicare reti adiacenti e far arrivare alla rete di destinazione il pacchetto una sottorete alla volta. I pacchetti vengono cioè consegnati dai router da una rete all’altra finché non giungono alla rete di destinazione. Gli algorimti di instradamento (usiamo instradamento come equivalente di routing) determinano la definizione della rotta, che è l’unione dei passaggi da sottorete e sottorete a partire dall’origine e arrivando alla destnazione. In questa situazione si deve immaginare come ogni router sia a conoscenza soltanto delle reti a lui collegate direttamente. Un protocollo di routing perciò condivide le informazioni di instradamento prima con i vicini immediati e poi attraverso tutta la rete. In questo modo i router acquisiscono una conoscenza globale della rete e accomodano i parametri dinamicamente a seconda del funzionamento della rete per scegliere sempre il percorso ottimale.
I routers devono evitare loop, devono tenere aggiornati i tempi di hop (salto) verso tutte le sottoreti adiacenti, il tempo di convergenza in modo tale che la rete sia sempre funzionante. È un po’ quello che avevano in mente i primi progettisti di ARPANET.
Il funzionamento della spedizione di un datagramma in Internet è spiegato bene dalla RFC 791, una delle prime, scritte da Jon Postel nel 1981, all’epoca già esisteva TCP/IP che era stato inventato da Vinton Cerf e Bob Kahn nel 1974.
2.2 Modello di funzionamento
Il modello di funzionamento della trasmissione di un datagramma da un’applicazione ad un altre è illustrata nello scenario seguente:
Supponiamo che questa trasmissione riguardi un gateway intermedio.
Il software applicativo mittente prepara i suoi dati e invoca il suo modulo internet locale [le funzioni TCP/IP del sistema operativo] per inviare questi dati come datagramma e passa alla chiamata anche l’indirizzo di destinazione e altri parametri.
Il modulo internet prepara l’intestazione del datagramma e ci attacca di seguito i dati. Il modulo internet individua un indirizzo di rete locale verso questo indirizzo internet, in questo caso è l’indirizzo del gateway.
Quindi consegna questo datagramma e l’indirizzo di rete locale all’interfaccia di rete locale.
L’interfaccia di rete locale crea una seconda intestazione di rete locale e ci attaccca il datagramma ricevuto, quindi invia il risultato lungo la rete locale.
Il datagramma arriva al gateway contenuto nell’intestazione: l’interfaccia di rete locale [del gateway] stacca questa intestazione e gira il datagramma così ottenuto al modulo internet [le funzionalità TCP/IP del gateway]. Il modulo internet capisce dall’indirizzo internet che il datagramma è destinato ad un altro host in una seconda rete. Quindi determina un indirizzo di rete locale verso l’host di destinazione, e finalmente chiama l’interfaccia di questa rete locale per inoltrare il datagramma.
Questa interfaccia di rete locale crea una intestazione di rete locale e ci attacca il datagramma ricevuto e invia il risultato all’host di destinazione [che stavolta si trova proprio in quest’ultima rete].
Una volta giunto all’host di dsetinazione, l’interfaccia di rete rimuove l’intestazione e consegna il datagramma al modulo internet. Il modulo internet capisce che il datagramma è destinato al programma applicativo [individuato dal numero di porta] di questo host. Quindi passa il datagramma al programma applicativo attraverso una chamata di sistema, assieme all’indirizzo sorgente e tutti gli eventuali parametri.
Application Application
Program Program
\ /
Internet Module Internet Module Internet Module
\ / \ /
LNI-1 LNI-1 LNI-2 LNI-2
\ / \ /
Local Network 1 Local Network 2
Funzionamento di ping
ping è una utility che si trova in tutti i sistemi operativi che implementa il protocollo ICMP per effettuare in linea di massima un test di presenza di un host in internet. In linea di massima significa che l’host può esserci in internet ma non rispondere al comando ping. Quello che ci interessa di questa implemetazione di ping è vedere cosa vuol dire che un livello OSI ne chiama un altro.
Il sorgente è tratto dal sito GeeksForGeeks e mi limito a mettere il focus sugli aspetti salienti per quello che sto trattando qui.
La prima operazione che il programma fa è recuperare da un servizio di nomi (DNS) l’indirizzo IP dell’host da “pingare”; dopo di questo può chiamare la funzione send_ping(). Riportiamo anche le dichiarazioni delle variabili utilizzate
int main(int argc, char *argv[])
{
int sockfd;
char *ip_addr, *reverse_hostname;
struct sockaddr_in addr_con;
int addrlen = sizeof(addr_con);
ip_addr = dns_lookup(argv[1], &addr_con);
reverse_hostname = reverse_dns_lookup(ip_addr);
// apro il socket
sockfd = socket(AF_INET, SOCK_RAW, IPPROTO_ICMP);
//send pings continuously
send_ping(sockfd, &addr_con, reverse_hostname, ip_addr, argv[1]);
return 0;
}
Eccco, in questo scenario il nostro programma ping si colloca al livello applicazione mentre le utilities dns_lookup(), reverse_dns_lookup() e socket() si situano sul livello Internet (sono implementate dal sistema operativo). Ma vediamo l’implementazione della funzione send_ping(), commenti ulteriormente presenti in italiano:
// make a ping request
void send_ping(int ping_sockfd, struct sockaddr_in *ping_addr,
char *ping_dom, char *ping_ip, char *rev_host)
{
int ttl_val=64, msg_count=0, i, addr_len, flag=1,
msg_received_count=0;
// struttura contenente il pacchetto ICMP
struct ping_pkt pckt;
// struttura contenente l'indirizzo IP
struct sockaddr_in r_addr;
...
clock_gettime(CLOCK_MONOTONIC, &tfs);
// send icmp packet in an infinite loop
while(pingloop)
{
//filling packet
// inizializzo il pacchetto con tutti zeri dentro
bzero(&pckt, sizeof(pckt));
//... e poi inizializzo i campi del pacchetto ICMP
pckt.hdr.type = ICMP_ECHO;
pckt.hdr.un.echo.id = getpid();
for ( i = 0; i < sizeof(pckt.msg)-1; i++ )
pckt.msg[i] = i+'0';
pckt.msg[i] = 0;
pckt.hdr.un.echo.sequence = msg_count++;
pckt.hdr.checksum = checksum(&pckt, sizeof(pckt));
//send packet
clock_gettime(CLOCK_MONOTONIC, &time_start);
if ( sendto(ping_sockfd, &pckt, sizeof(pckt), 0,
(struct sockaddr*) ping_addr,
sizeof(*ping_addr)) <= 0)
{
printf("\nPacket Sending Failed!\n");
flag=0;
}
//receive packet
addr_len=sizeof(r_addr);
if ( recvfrom(ping_sockfd, &pckt, sizeof(pckt), 0,
(struct sockaddr*)&r_addr, &addr_len) <= 0
&& msg_count>1)
{
printf("\nPacket receive failed!\n");
}
else
{
clock_gettime(CLOCK_MONOTONIC, &time_end);
// calcolo del round trip time
double timeElapsed = ((double)(time_end.tv_nsec -
time_start.tv_nsec))/1000000.0 ;
rtt_msec = (time_end.tv_sec-
time_start.tv_sec) * 1000.0
+ timeElapsed;
// if packet was not sent, don't receive
if(flag)
{
if(!(pckt.hdr.type ==69 && pckt.hdr.code==0))
{
printf("Error..Packet received with ICMP \
type %d code %d\n",
pckt.hdr.type, pckt.hdr.code);
}
else
{
printf("%d bytes from %s (h: %s) \
(%s) msg_seq=%d ttl=%d \
rtt = %Lf ms.\n",
PING_PKT_S, ping_dom, rev_host,
ping_ip, msg_count,
ttl_val, rtt_msec);
msg_received_count++;
}
}
}
}
Anche qui, la funzione send_ping() fa sempre parte del livello applicazione (perché è definita dentro lo stesso programma ping1.c!) mentre le funzioni sendto() (che invia il pacchetto alla destinazione) e recvfrom() (che riceve la risposta dalla destinazione) sono definite nel livello internet e sono implementate dal sistema operativo. L’ouput di questa implementazione di ping è la seguente:
marcob@jsbach[15:08:52]:c$ sudo ./ping1 www.google.com
[sudo] password di marcob:
Resolving DNS..
Trying to connect to 'www.google.com' IP: 216.58.206.68
Reverse Lookup domain: mil07s08-in-f4.1e100.net
Socket file descriptor 3 received
Socket set to TTL..
64 bytes from mil07s08-in-f4.1e100.net (h: www.google.com)
(216.58.206.68) msg_seq=1 ttl=64 rtt = 14.009616 ms.
64 bytes from mil07s08-in-f4.1e100.net (h: www.google.com)
(216.58.206.68) msg_seq=2 ttl=64 rtt = 13.609196 ms.
64 bytes from mil07s08-in-f4.1e100.net (h: www.google.com)
(216.58.206.68) msg_seq=3 ttl=64 rtt = 13.357553 ms.
^C
64 bytes from mil07s08-in-f4.1e100.net (h: www.google.com)
(216.58.206.68) msg_seq=4 ttl=64 rtt = 14.134478 ms.
===216.58.206.68 ping statistics===
4 packets sent, 4 packets received, 0.000000 percent packet loss. Total time: 3177.355177 ms.
Una vista approfondita del traffico dati su Linux
Questo schema spiega un po’ più in dettaglio come i pacchetti (o datagrammi: c’è una differenza sostanziale ma per ora usiamo i termini in modo indifferenziato) che traggo da http://www.cs.unh.edu/
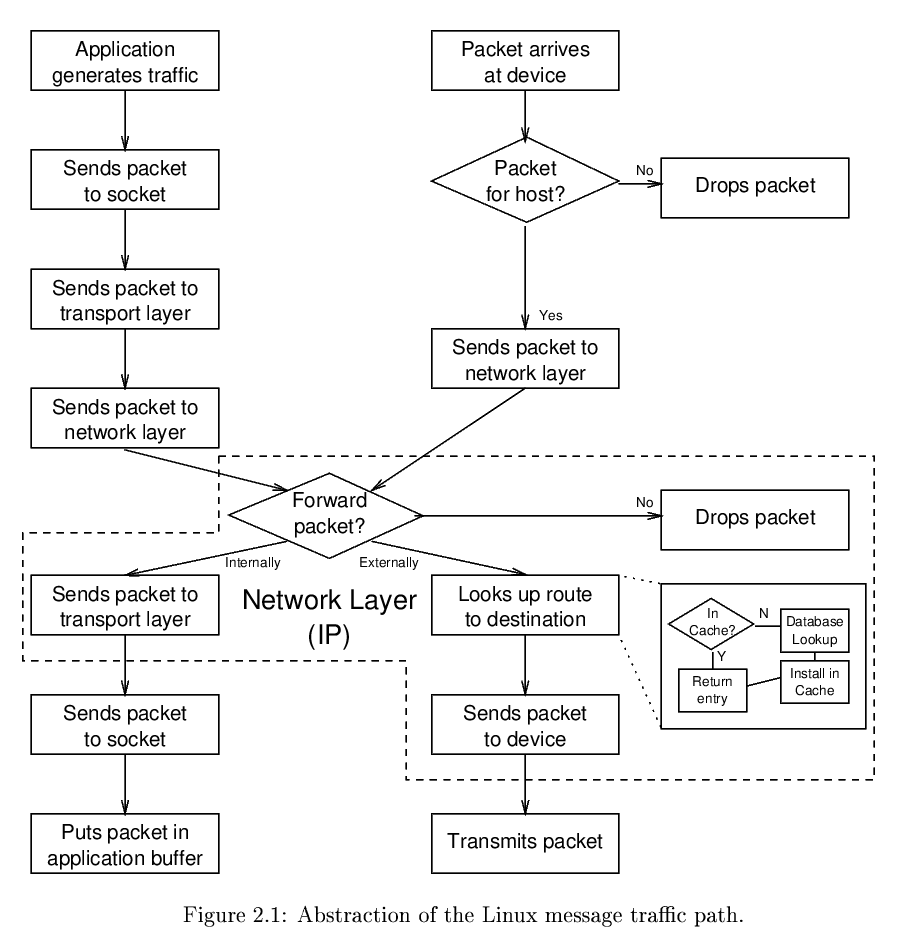
Un applicazione che vuole spedire un pacchetto (ad esempio un browser che invia una ricerca su Google) scrive il pacchetto su un socket, il quale lo passa al livello trasporto, da qui al livello network. Una volta giunto qui dobbiamo decidere se il pacchetto rimane nella stessa rete in cui si trova il PC in cui gira il browser (ad esempio un server web di test interno all’azienda), nel qual caso semplicemente il protocollo invierà il pacchetto al socket dell’host in cui si trova il web server e, tramite il numero di porta, il pacchetto raggiungerà il web server.
Se invece il web server è esterno alla rete aziendale (e lo è perché il sito si trova all’url https://www.google.com), il pacchetto dovrà essere dirottato all’esterno per cui chederò al DNS locale se esiste in cache l’indirizzo IP di Google: se c’è, invio al gateway/router (con cui mi collego ad Internet) il pacchetto con il nuovo indirizzo attaccato (quello di Google), altrimenti il protocollo esegue prima un lookup al DNS del provider per farsi dare l’indirizzo IP di Google (e poi lo mette in cache).
A questo punto appiccico al pacchetto l’indirizo di Google e lo invio al router il quale lo instraderà verso Google (e ci arriverà attraversando una sottorete alla volta e saltando da un router all’altro).
Jon Postel e la necessità di distinguere TCP e IP
Qui è utile ricordare una vecchia RFC, anzi non si chiamavano ancora così – si chiamavano IEN: Internet Experiment Notes-, scritta da John Postel nel 1977, è la IEN #2 nella quale egli spiega come sia necessario operare la distinzione tra livello TCP e IP:
La posizione che si vuole prendere in questa sede è che la comunicazione tra reti dovrebbe essere vista come avente due componenti: [1] la trasmissione salto a salto del messaggio e [2] il controllo agli estremi della conversazione. Questo conduce alla proposta di un protocollo internet orientato al salto a salto, di un protocollo a livello di host [TCP] e all’interfaccia tra questi.
Commenti recenti