Quando si esegue uno script Bash ci sono due modalità principali da impiegare, che hanno conseguenze diverse sull’ambiente della shell. 1. Esecuzione diretta (./script.sh) Quindi può solo leggere le variabili di ambiente della shell madre …
Preso dalla curiosità di ripassare l’assembly (tanti anni fa studiai il Motorola 68000) ho scritto una guida ordinata che illustra passo per passo come scrivere un semplice programma Assembly in real-mode (16 bit), confezionarlo come …
GeoGebra è un software open‑source per la didattica della matematica e della geometria dinamica. Quello che intendiamo qui con “geometria dinamica” è un approccio all’insegnamento e alla sperimentazione della geometria in cui le costruzioni non …
Negli ambienti desktop basati su GNOME, come Ubuntu, è possibile impostare uno sfondo che cambia automaticamente nel tempo, come una presentazione. Quello che molti non sanno è che GNOME supporta nativamente gli slideshow tramite file …
Negli ultimi giorni ho condotto una piccola sperimentazione con Whisper, il modello di riconoscimento vocale automatico (ASR) open source sviluppato da OpenAI. L’obiettivo era duplice: Cos’è Whisper Whisper è un sistema di riconoscimento vocale automatico …
marcob@jsbach:~/IdeaProjects/grails/bootstrap-italia-playground$ yarn start
yarn run v1.22.19
$ yarn prepare && http-server .
$ mkdir -p ./deps && cp -R ./node_modules/bootstrap-italia/dist/ ./deps/bootstrap-italia && cp -R ./node_modules/jquery/dist/ ./deps/jquery && cp -R ./node_modules/popper.js/dist/ ./deps/popper.js
Starting up http-server, serving .
http-server version: 14.1.0
http-server settings:
CORS: disabled
Cache: 3600 seconds
Connection Timeout: 120 seconds
Directory Listings: visible
AutoIndex: visible
Serve GZIP Files: false
Serve Brotli Files: false
Default File Extension: none
Available on:
http://127.0.0.1:8080
http://10.1.23.54:8080
http://10.251.0.32:8080
Hit CTRL-C to stop the server
....
[seguono il log di accesso a localhost:8080]
Ora punto il browser a http://127.0.0.1:8080/ e vedo questo:
bootstrap-italia playground
Personalizzazione
Adesso, come dice l’how-to, posso continuare a leggere [1]. Non manca molto in realtà!
Ah nota bene: avventurarsi a modificare a mano i CSS è come entrare in un roveto ardente: Bootstrap usa una forte parametrizzazione, quindi i valori RGB vengono calcolati (dal colore primario a tutte le sue declinazioni): per cui è più conveniente guardare come funziona.
Per personalizzare i colori di Bootstrap Italia, esamino il file scss/bootstrap-italia-custom.scss, dove il colore $primary è descritto nelle sue componenti HSB (Hue, Saturation, Brightness = Tonalità, saturazione, Luminosità. vedi [5]).
Occorre quindi modificare questi tre parametri a piacimento (questo è il cuore del funzionamento).
Per esempio devo mutare lo schema da blu a verde. Vado quindi, per esempio, in questo sito [4] (ma va bene una qualunque ruota dei colori che si trova in rete) dove scelgo il verde che mi piace, ad esempio quello RBG = #67E098 corrispondente a (H,S,B)=(144,54,88)
Per ottenere una versione personalizzata della libreria quindi:
Compilare la libreria Bootstrap Italia personalizzata con: yarn build
La compilazione crea dei file nella cartella css/compiled che vanno referenziati nel file index.html (posso mantenere il vecchio file bootstrap-italia.min.css rinominandolo con .old – oppure mi affido a Git).
Docker è un gestore di container, un sistema che consente di gestire degli ambienti di lavoro isolati per sviluppare applicazioni.
Ciò che mi ha spinto ad utilizzare Docker è l’urgenza di confinare un’applicazione che sto scrivendo in un ambiente stabile immune dagli avanzamenti di versione a cui devo sottoporre regolarmente il sistema operativo (Ubuntu Linux) della mia macchina (HP ProBook 440G).
Ho bisogno di una sandbox che rimanga stabile per tutto lo sviluppo dell’applicazione.
Questa prassi avrà poi un altro risvolto positivo, quello di poter trasferire (“deployare”) la sandbox così com’è nell’ambiente di collaudo o di produzione, e rendere così le operazioni CI/CD molto rapide e indolori.
Istruzioni per installare Docker su una macchina Ubuntu.
Passo 1: installazione
Seguo la guida del sito [1]; non funziona il comando com’è scritto, ma il suggerimento che danno poco prima, quello di studiarsi prima lo script, è illuminante: lo eseguo da root una riga alla volta:
[sudo] password di marcob:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:13e367d31ae85359f42d637adf6da428f76d75dc9afeb3c21faea0d976f5c651
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
Utilizzando il package Manager di Ubuntu
Provo anche a installare con il gestore di pacchetti APT.
$ sudo docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
Un po’ più complicato: una installazione Ubuntu intera
Ho bisognno di un container con una versione di Ubuntu precedeente a quella della mia macchina.
L’esempio seguente fa al caso mio. Ovviamente dovrò approfondire, ma mi pare di essere sulla buona strada.
$ sudo docker run -it ubuntu bash
Unable to find image 'ubuntu:latest' locally
latest: Pulling from library/ubuntu
405f018f9d1d: Pull complete
Digest: sha256:b6b83d3c331794420340093eb706a6f152d9c1fa51b262d9bf34594887c2c7ac
Status: Downloaded newer image for ubuntu:latest
root@9d0779c49ba7:/# whoami
root
root@9d0779c49ba7:/# hostname
9d0779c49ba7
root@9d0779c49ba7:/# pwd
/
root@9d0779c49ba7:/# cd home
root@9d0779c49ba7:/home# ll
total 8
drwxr-xr-x 2 root root 4096 Apr 18 10:28 ./
drwxr-xr-x 1 root root 4096 Jun 17 13:16 ../
La prossima sfida è installare una release di Ubuntu leggermente più vecchia (la 21.04 Hirsute Hippo), Python, GDAL, QGIS e PostgrSQL.
Problema di conflitto degli indirizzi di rete
Per impostazione predefinita, il sistema di virtualizzazione Docker utilizza le reti 172.17.0.0/12 per il suo funzionamento. Se queste impostazioni creano conflitti nelle reti a cui dobbiamo connetterci, occorre cambiare questo indirizzo e per fare questo si possono modificare le impostazioni.
Per vedere quale rete sta usando il tuo demone, lista la confgurazione delle interfacce di rete:
Io sto lavorando in una rete aziendale che ha una sottorete esattamente all’indirizzo 172.17.0. Non riesco più a raggiungere le macchine di questa sottorete…
Quindi devo poter cambiare la configurazione di docker.
Dovevo cercare una determinata stringa in una colonna TESTO di una tabella Oracle definita come LONG (contiene informazioni di testo, XML nel mio caso). Un’operazione semplice, pensavo.
Ho utilizzato l’operatore LIKE:
SELECT ID, TESTO
FROM TEMPLATE
WHERE UPPER(TESTO) LIKE '%LOREM%'
ma con scarso successo, infatti l’errore che si è verificato è il seguente:
ORA-00932: tipi di dati incoerenti: previsto CHAR, ottenuto LONG
00932. 00000 - "inconsistent datatypes: expected %s got %s"
*Cause:
*Action:
Errore alla riga: 2, colonna: 13
Infatti non posso utilizzare l’operatore LIKE su campi LONG (in genere lo uso con i campi VARCHAR2).
Da [1] apprendo che addirittura i campi LONG non possono nemmeno comparire nelle clausole di filtro (WHERE) delle query.
Non solo.
Le colonne di tipo LONG non possono comparire in vincoli di integrità (fatta eccezione per NULL/NOT NULL).
Le colonne di tipo LONG non possono comparire in una espressione regolare.
Ogni tabella può avere al più una colonna di tipo LONG.
Eccetera.
Insomma una serie di condizioni molto vincolanti. Ma soprattutto non posso cercare il testo che voglio.
Il tipo LONG è tuttavia un tipo di dato deprecato in favore del tipo CLOB, atto a contenere testo che eccede i 4000 byte
Sempre in [1] trovo la soluzione: occorre trasformare il dato in un Large Object (LOB). Creo quindi una nuova tabella così:
CREATE TABLE ZZZ_TEMPLATE AS
SELECT ID, TO_LOB(TESTO) AS TESTO
FROM TEMPLATE;
-- Creato table ZZZ_TEMPLATE.
Dunque posso eseguire la query:
SELECT * FROM zzz_template
WHERE UPPER(TESTO) LIKE '%LOREM%';
--
137 "<?xml version="1.0" encoding="ISO-8859-1"?>..."
312 "<?xml version="1.0" encoding="ISO-8859-1"?>..."
311 "<?xml version="1.0" encoding="ISO-8859-1"?>..."
310 "<?xml version="1.0" encoding="ISO-8859-1"?>..."
Questo post verte soltanto su un aspetto se volete marginale – ma molto utile – della IDE che uso per progetti PHP / Python / Groovy: IntelliJ IDEA di JetBrains: come la IDE ci aiuta a non commettere errori del tipo “leggere valori di variabili private”.
Il codice è suo e qui lo analizzo soltanto (faccio solo piccole, innocue personalizzazioni). Precisamente: descrivo un po’ più in dettaglio un comportamento della IDE che mi aiuta a scrivere meglio il software.
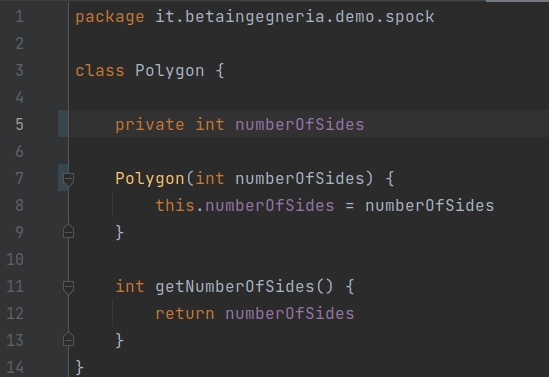
Sto scrivendo (più precisamente: analizzando il funzionamento di) una classe di test con Spock che riguarda una classe Groovy Polygon (posto gli screenshot perché risulta evidente il comportamento della IDE di cui voglio parlare): la classe ha una sola proprietà che si chiama numberOfSides, il numero di lati del poligono, che è un attributo privato:
Spock for Groovy – private variable
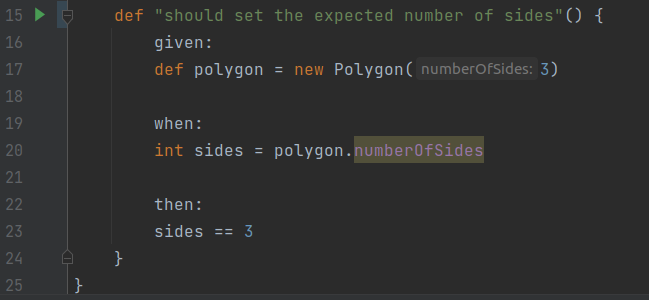
Ora scriviamo un test (nel gergo di Spock i test si chiamano Specifications) che controlla se l’attribuzione del numero di lati del poligono funziona come ci aspettiamo; utilizziamo il costrutto given – when – then (che è l’oggetto di questa parte del tutorial di Trisha):
Spock: scrivere un test di tipo given-when-then
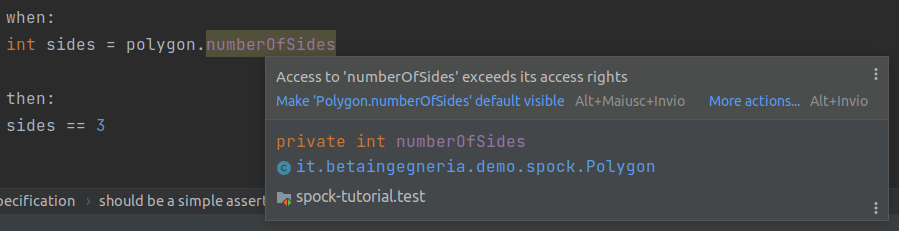
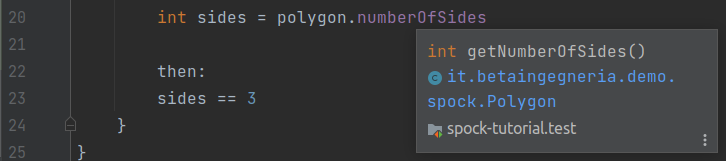
Notiamo che la proprietà numberOfSides dell’oggetto è evidenziata; passando con il mouse sopra la parte messa in risalto, la IDE ci informa sul perché di questa evidenziazione (Access to ‘numberOfSides’ exceedes its access rights):
Spock: tentativo di assegnare direttamente il valore di una variabile privata
Stiamo infatti tentando di accedere ad un valore di una variabile privata da un’istanza della classe e non dall’interno della classe stessa.
Potremmo correggere questa cosa in due modi: o attribuendo il qualificatore public alla variabile oppure definendo un getter. Percorro questa seconda via; aggiungo quindi il metodo getNumberOfSides() alla classe – è una costruzione standard: get + nome della variabile (con la regola CamelCase):
int getNumberOfSides() {
return numberOfSides
}
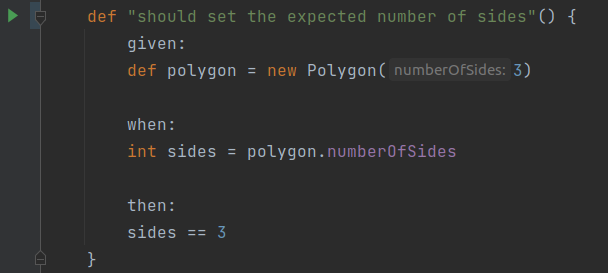
Ecco che la IDE non mette più in evidenza la proprietà numberOfSides:
Spock: l’uso della variabile privata non è più segnalato come scorretto.
Si noti che la IDE riconosce la presenza di un getter secondo la convenzione espressa sopra – se non seguo la convenzione la IDE tornerà a segnalare il problema. Nota che non ho cambiato la scrittura (non ho utilizzato esplicitamente il getter nell’assegnazione, ma l’ho lasciata così com’è) ma Groovy lo farà durante il build, sostituendo all’assegnazione diretta l’invocazione del getter come risulta dal tooltip che viene visualizzato quando passiamo con il mouse sopra l’istruzione:
Spock: assegnare di una variabile privata con getter
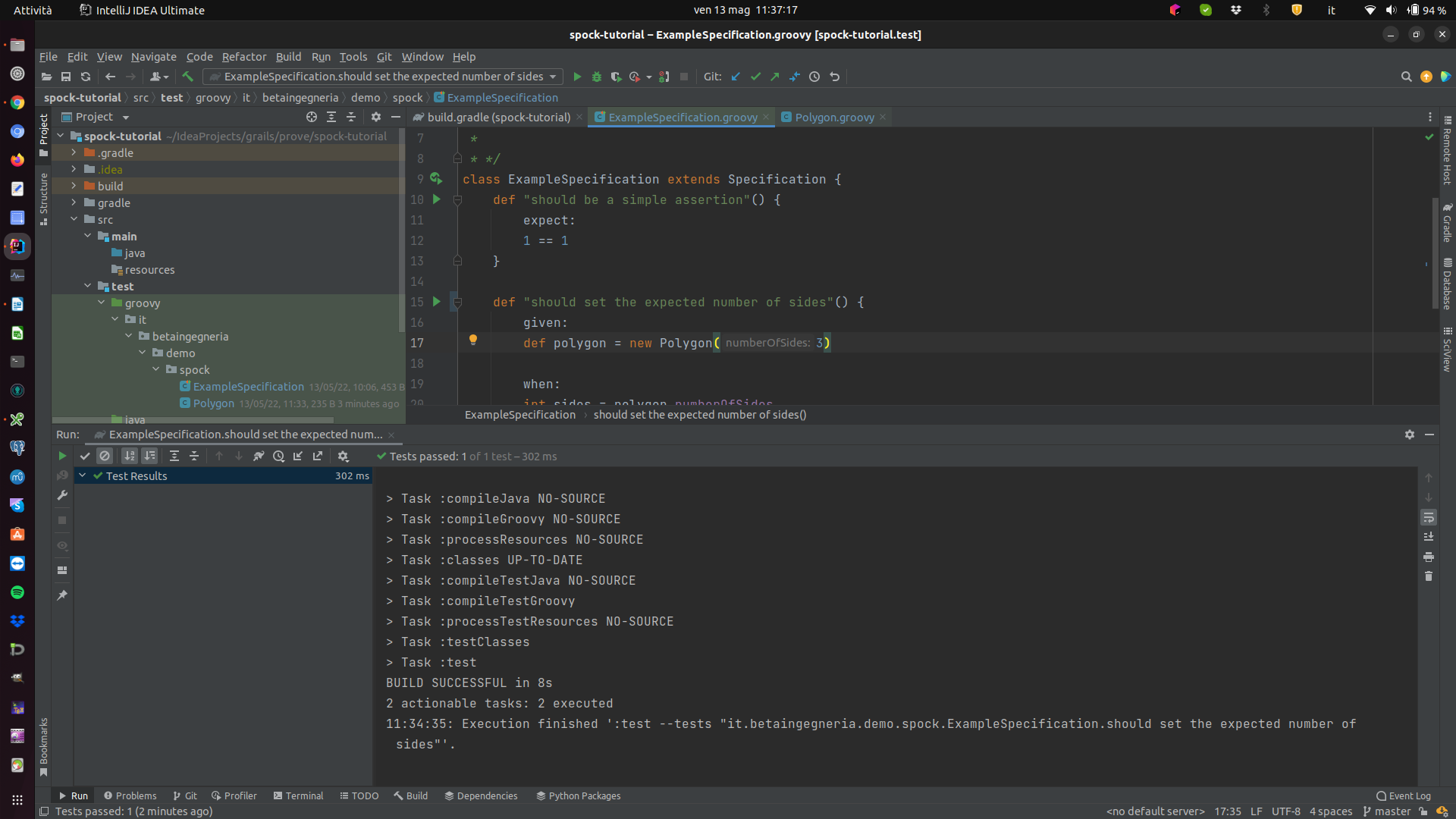
Non ci resta che lanciare il test cliccando sulla freccetta verde accanto alla definizione del metodo (notare come sia possibile utilizzare stringhe custom per definire il nome dei metodi, una caratteristica molto utile per documentare ciò che il test vuole fare):
Come partire da una situazione incasinata con molte versioni di Java e diversi JDK e fare ordine con SDKMAN.
Prendo spunto dall’articolo di Gunter Rosaert di DZone.
Situazione di partenza
Ecco quello che ho a bordo della mia macchina Linux:
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 21.10
Release: 21.10
Codename: impish
$ update-alternatives --list java
/usr/lib/jvm/java-11-openjd-amd64/bin/java
/usr/lib/jvm/java-8-openjd-amd64/jre/bin/java
/usr/lib/jvm/jd1.8.0_202/bin/java
/usr/local/java/jre1.8.0_73/bin/java
Premetto che mi servono tutte queste versioni per fare girare diversi client di epoca diversa come:
Mirth Connect, versioni 2.8, 3.2, 3.5
Oracle SqlDeveloper
Poi ho la IDE, Intellij IDEA, che si porta appresso un’altra versione
$ ls .jdks/
openjdk-17
SDK
Ho già una versione di sdk a bordo ma deve essere aggiornata:
$ sdk version
==== BROADCAST =================================================================
* 2022-04-12: quarkus 2.8.0.Final available on SDKMAN! https://github.com/quarkusio/quarkus/releases/tag/2.8.0.Final
* 2022-04-11: neo4jmigrations 1.5.4 available on SDKMAN! https://github.com/michael-simons/neo4j-migrations/releases/tag/1.5.4
* 2022-04-10: jreleaser 1.0.0 available on SDKMAN! https://github.com/jreleaser/jreleaser/releases/tag/v1.0.0
================================================================================
SDKMAN 5.14.3
ATTENTION: A new version of SDKMAN is available...
The current version is 5.15.0, but you have 5.14.3.
Would you like to upgrade now? (Y/n):
Scelgo di fare l’update, che risulta velocissimo:
Updating SDKMAN...
######################################################################## 100,0%
Install scripts...
sdkman_auto_answer=false
......
Successfully upgraded SDKMAN!
Open a new terminal to start using SDKMAN 5.15.0.
To join our BETA channel, simply follow the instructions on:
http://sdkman.io/install
Enjoy!!!
Lista dei JDK
Una lista completa di tutte versioni di Java esistenti si ottiene con il comando sdk list. In particolare si possono vedere tutti i tool installabili, da Ant a Tomcat a Grails e a Groovy; l’output è rediretto a less così da poter navigare e accedere anche al menu (stampato in alto):
$ sdk list
================================================================================
Available Candidates
================================================================================
q-quit /-search down
j-down ?-search up
k-up h-help
--------------------------------------------------------------------------------
Apache ActiveMQ (Classic) (5.16.2) https://activemq.apache.org/
Apache ActiveMQ® is a popular open source, multi-protocol, Java-based message
.....
$ sdk install activemq
--------------------------------------------------------------------------------
Ant (1.10.12) https://ant.apache.org/
Apache Ant is a Java library and command-line tool whose mission is to drive
...
$ sdk install ant
--------------------------------------------------------------------------------
eccetera. Vengono listati tutti i tool con descrizione e relativo comando di installazione. Aggiungendo il parametro java invece vengono listate tutte le versioni di Java installabili (da Java.net, a Oracle, a Amazon, a versioni Unclassified) e vengono rilevate quelle installate nel sistema:
================================================================================
Available Java Versions for Linux 64bit
================================================================================
Vendor | Use | Version | Dist | Status | Identifier
--------------------------------------------------------------------------------
Corretto | | 18 | amzn | | 18-amzn
| | 17.0.2.8.1 | amzn | | 17.0.2.8.1-amzn
................................................................................
Temurin | | 18 | tem | | 18-tem
| | 17.0.2 | tem | | 17.0.2-tem
| >>> | 11.0.14 | tem | installed | 11.0.14-tem
Unclassified | | openjdk11 | none | local only | openjdk11
| | jdk1.8.0_202 | none | local only | jdk1.8.0_202
================================================================================
Ho limitato la lunga lista alle prime righe e alle versioni che ho effettivamente installato.
Se si vuole installare una versione si digita sdk install java [TAB] e compare la lista
Ora si potrebbe fare pulizia delle versioni non in uso. Però, attenzione, ho altro software da far funzionare.
Ad esempio mi collego ad un server Mirth di un cliente con il client MirthConnect 3.2.0 che usa Java WebStart 11.202.2, il quale insiste su JRE 1.8.0_73-b02 Java HotSpot(TM) 64-Bit Server VM, che è l’ultima indicata nelle alternatives.
Anche il client MirthConnect Administrator 3.5.2 utilizza lo stesso JRE.
Configurare il JDK da usare per il build in Intellij
Ora il passaggio fondamentale è questo: configurare il kit da usare con l’IDE (per me Intellij IDEA). Può essere fatto a livello globale (per tutti i progetti) o per progetto (si può derogare dallo standard e prenderne una specifica per un progetto). Il build non presenta particolari problemi. Il problema bloccante si manifesta invece all’avvio dell’applicazione (run app).
Ottengo infatti questo un errore bloccante:
/home/marcob/.jdks/openjdk-17/bin/java
...
Failed to compile intellij-command-proxy.groovy: BUG! exception in phase 'semantic analysis' in source unit 'intellij-command-proxy.groovy' Unsupported class file major version 61 (Use --stacktrace to see the full trace)
Ma come si vede in realtà il kit utilizzato per esegue l’applicazione non è quello che abbiamo installato.
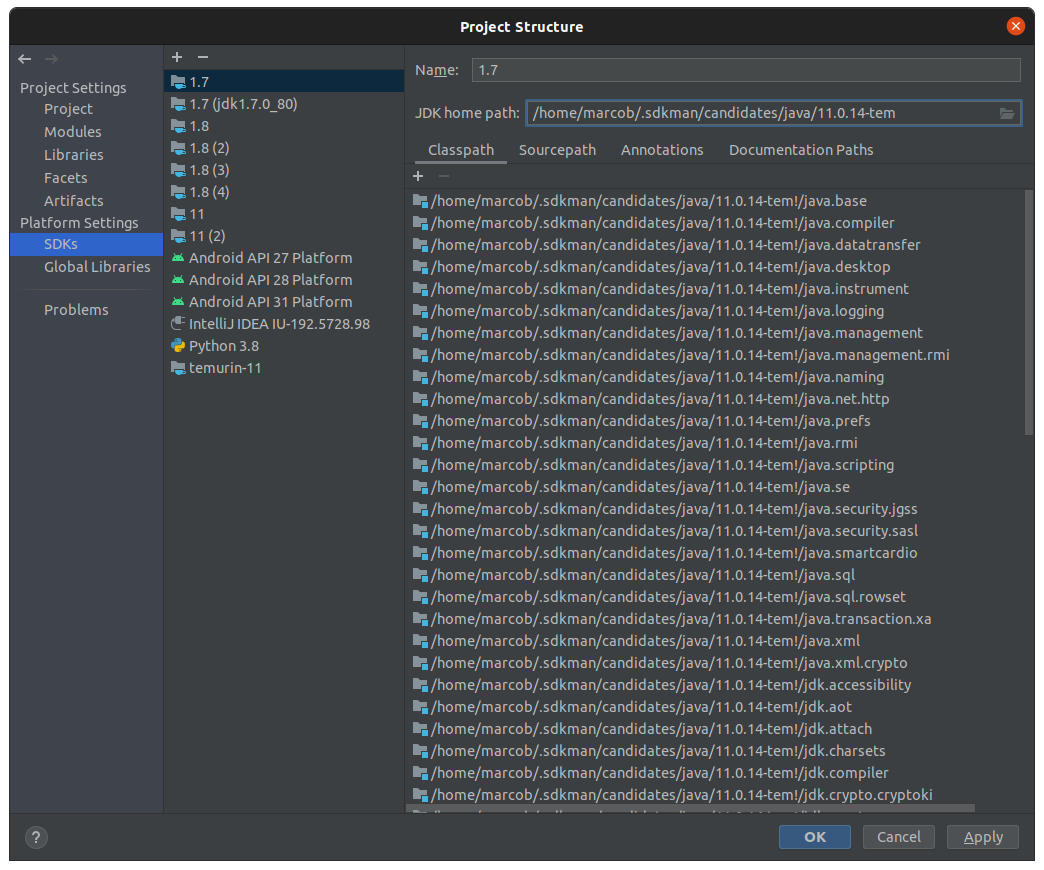
Si può definire un kit di default per tutti i progetti Java creati cona IDE raggiungendo questa voce dal menu: File > Project Structure e selezionare la voce SDKs sotto “Platform Settings” nel menu di sinistra:
Selezionare il SDK di default per i nuovi progetti Grails
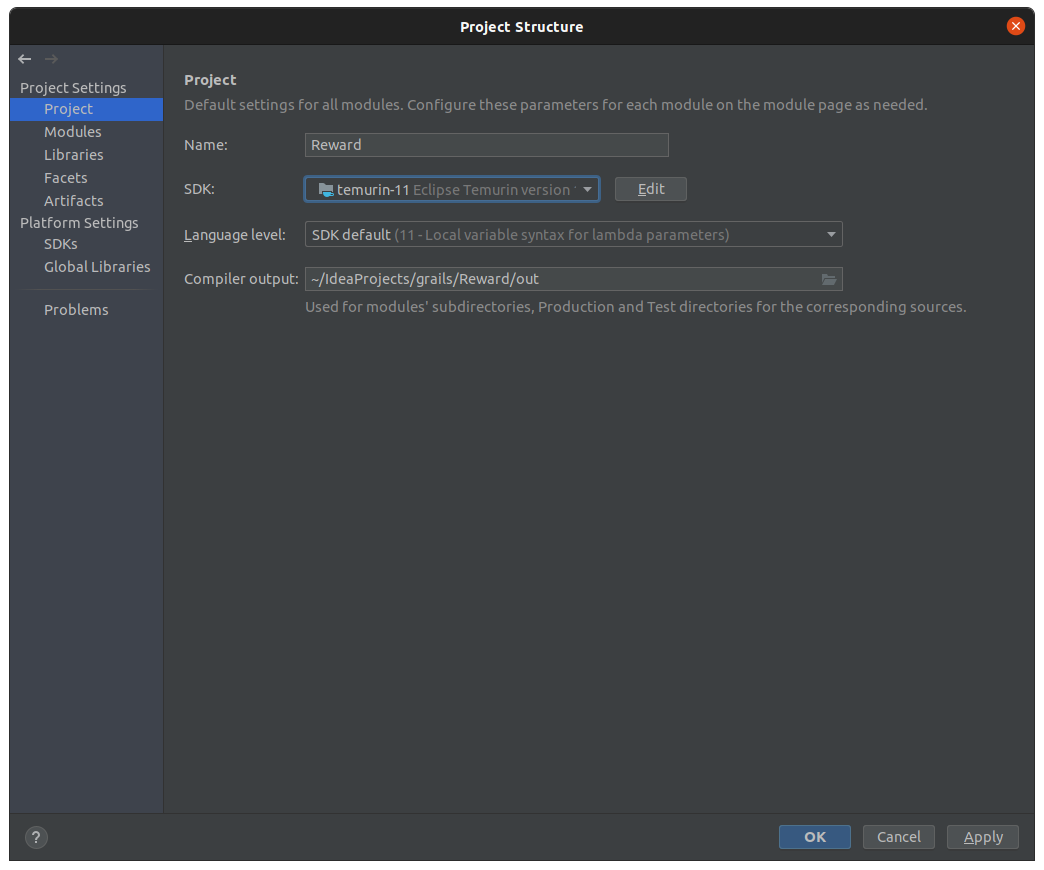
Quindi devo recarmi nelle impostazioni del progetto IntelliJ e compiere queste due oprazioni: File > Project Structure e selezionare la voce Project sotto “Project Settings” nel menu di sinistra:
SDK di progetto
Nella selezione SDK seleziono temurin-11.
La SDK di solito va impostata quando si crea il progetto:
Impostazione generale della SDK per l’intera IDE
Se si vuole usare la Temurin per tutti i progetti, bisogna impostare il SDK Globale con la voce Platform Settings > SDKs nel menu di sinistra (nota: se vedete differenze in queste schermate rispetto alla vostra IDE, la mia versione è IntelliJ IDEA 2021.3.3 (Ultimate Edition)):
Andare alle origini della programmazione web è sempre affascinante. Questo articolo aiuta a capire come funziona il web attraverso azioni sui socket.
Questo post è la traduzione pressoché letterale dell’articolo del blogIximiuz di Ivan Velichko. Sue anche le illustrazioni e gli esempi di codice funzionante. Lo ringrazio tantissimo per la gentilezza e l’entusiasmo che ha dimostrato per il mio interesse.
In coda trovate i suoi riferimenti. Io ho solamente integrato con qualche esempio applicativo e qualche commento qua e la, sempre segnalato.
Cos’è un web server?
Iniziamo rispondendo alla domanda: che cos’è un server web?
Prima di tutto, è un server (nessun gioco di parole). Un server è un processo [sic] che serve i client.
Frequentemente pensiamo al server come ad una macchina, ma in realtà è solo un processo che gira in una certa macchina – assieme a molti altri processi.
Quindi, che ci sorprendiamo o no, un server non ha nulla a che fare con l’hardware. È solo un normale software eseguito da un sistema operativo. Come la maggior parte degli altri programmi in circolazione, un server acquisisce alcuni dati dal proprio input, trasforma i dati in base ad alcune logiche di business e quindi produce alcuni dati di output. Nel caso di un server web, l’input e l’output avvengono sulla rete tramite Hypertext Transfer Protocol (HTTP). Per un server Web, l’input è costituito da richieste HTTP dai suoi client: browser Web, applicazioni mobili, dispositivi IoT o persino altri servizi Web. E l’output è costituito da risposte HTTP, spesso sotto forma di pagine HTML, ma sono supportati anche altri formati.
client-server-opt
Cos’è questo protocollo di trasferimento ipertestuale (HTTP)? Bene, a questo punto, basterebbe pensarlo come un protocollo di scambio dati basato su testo (cioè leggibile dall’uomo). E la parola protocollo può essere spiegata come una sorta di convenzione tra due o più parti sul formato e sulle regole di trasferimento dei dati. Nessun problema, ci sarà un articolo che coprirà i dettagli di HTTP in seguito, mentre il resto di questo articolo sarà incentrato su come i computer inviano dati arbitrari sulla rete.
Che aspetto ha la programmazione di rete?
Nei sistemi operativi simili a Unix, è abbastanza comune trattare i dispositivi I/O come file. Proprio come avviene per i normali file su disco, i mouse, le stampanti, i modem, ecc. possono essere aperti, letti/scritti e quindi chiusi.
dev-files-opt
Per ogni file aperto, il sistema operativo crea un cosiddetto descrittore di file. Semplificando un po’, un descrittore di file è solo un identificatore intero univoco di un file all’interno di un processo. Il sistema operativo fornisce una serie di funzionichiamate di sistema per manipolare file che accettano un descrittore di file come argomento. Ecco un esempio canonico con le operazioni read() e write():
Poiché anche la comunicazione di rete è una forma di I/O, sarebbe ragionevole aspettarsi anche che si riduca a manipolazione di file. E in effetti, esiste un tipo speciale di file per questo tipo di I/O, chiamato socket.
Un socket è un altro pezzo di astrazione fornito dal sistema operativo. Come spesso accade con le astrazioni del computer, il concetto è stato preso in prestito dal mondo reale, in particolare dalle prese di alimentazione CA, quelle attaccate al muro in cui inseriamo la spina del frigo o della TV. Una coppia di socket consente a due processi di dialogare tra loro. In particolare, in rete. Un socket può essere aperto, i dati possono essere scritti sul socket o letti da esso. E, naturalmente, quando la presa non è più necessaria, ci si dovrebbe scollegare.
ac-power-socket-opt
Di socket ce ne sono di parecchi tipi diversi e ci sono molti modi per usarli per la comunicazione tra processi. Ad esempio, i socket di rete possono essere utilizzati quando due processi risiedono su macchine diverse. Per i processi locali, i socket di dominio Unix possono essere una scelta migliore. Ma anche questi due tipi di socket possono essere di tipo diverso: datagram (o UDP), stream (o TCP), raw socket, ecc. Questa varietà può sembrare complicata all’inizio, ma fortunatamente esiste un approccio più o meno generico su come utilizzare socket di qualsiasi tipo nel codice. Imparare a programmare uno di questi tipi di socket ti darà la possibilità di estendere la conoscenza ad altri tipi.
Se conforntiamo i due pseudocodici ci accorgiamo che facciamo delle operazioni simili: nel primo caso (I/O su disco) apriamo un file, nel secondo (I/O su rete) ci connettiamo ad un socket (“infiliamo una spina”).
Più avanti in questo articolo, ci concentreremo su una forma di comunicazione client-server tramite socket di rete utilizzando lo stack di protocolli TCP/IP. Apparentemente, questa è la forma più utilizzata al giorno d’oggi, in particolare perché i browser la utilizzano per accedere ai siti web.
Come i programmi comunicano in rete
Immagina che ci sia un’applicazione che vuole inviare un pezzo di testo relativamente lungo sulla rete. Supponiamo che il socket sia già stato aperto e che il programma stia per scrivere – write – (o, nel gergo della rete, inviare – send) questi dati al socket. Come verranno trasmessi questi dati?
I computer vivono in un mondo discreto. Le schede di interfaccia di rete (NIC) trasmettono i dati in piccole porzioni, poche centinaia di byte contemporaneamente. Allo stesso tempo, in generale, la dimensione dei dati che un programma può voler inviare non è comunque limitata e può superare le centinaia di gigabyte. Per trasmettere un pezzo di dati arbitrario di grandi dimensioni sulla rete, è necessario che venga suddiviso in blocchi (chunked) e ogni blocco deve essere inviato separatamente. Logicamente, la dimensione massima del blocco non deve superare la limitazione della scheda di rete.
chunking-opt
Ogni blocco è composto da due parti: le informazioni di controllo e l’informazione vera e propria (payload). Le informazioni di controllo includono gli indirizzi di origine e di destinazione, la dimensione del blocco, un checksum, ecc. Mentre il payload è… be’, i dati effettivi che il programma vuole inviare. È la vera merce che i computer si scambiano, ad esempio il contenuto di un singolo post di Twitter o di una intera pagina web.
Il più delle volte, per indirizzare i computer nella rete, vengono assegnati i cosiddetti indirizzi IP. L’acronimo IP sta per Internet Protocol, un famoso protocollo che ha reso possibile l’interconnessione delle reti (networks) dando vita a Internet. Il protocollo Internet è principalmente responsabile di 3 cose:
indirizzare le interfacce degli host (dei computer);
incapsulare i dati del payload in pacchetti (cioè il suddetto chunking);
instradare i pacchetti da una sorgente a una destinazione attraverso una o più reti IP.
Sul problema del chuncking: la semplificazione che adotto è non ortodossa ma ai fini della comprensione non è fuorviante (disclaimer).
IP è un cosiddetto protocollo Layer 3 della suite di protocolli Internet. I protocolli della suite formano uno stack (una pila) in cui ogni protocollo di livello superiore si basa su quello sottostante. Cioè, nel caso di IP, dovrebbe esserci un protocollo Layer ad un livello inferiore 2, o Link layer o livello collegamento (es. Ethernet o, in parole povere, Wi-Fi). I protocolli di livello collegamento si concentrano sui dettagli di trasmissione dei dati di livello inferiore e il loro ambito è limitato dalla comunicazione della rete locale (LAN) (ovvero nessuna consapevolezza del routing). La verità è che il chunking, (o framing nel gergo di rete), avviene anche a quel livello. Poiché IP è consapevole di tale limitazione, rende i suoi pacchetti abbastanza piccoli da poter essere inseriti nei frame di livello 2 perché, alla fine, l’unità di trasmissione sarà un frame, non tutto il pacchetto IP stesso. Sebbene importanti, questi dettagli sono comunque piuttosto irrilevanti per questo articolo.
Nel suo percorso dall’origine alla destinazione, un pacchetto IP di solito passa una manciata di host intermedi. Questa serie di host costituisce un percorso. Potrebbe esserci (e di solito c’è) più di un percorso per una coppia arbitraria (origine, destinazione). E poiché sono possibili più percorsi contemporaneamente, va benissimo che i pacchetti IP con la stessa coppia (origine, destinazione) prendano percorsi diversi. Tornando al problema dell’invio di un lungo pezzo di testo sulla rete, può succedere che i blocchi, ovvero i pacchetti IP su cui il testo è stato suddiviso, impiegheranno percorsi diversi verso l’host di destinazione. Tuttavia, percorsi diversi possono avere ritardi diversi. Inoltre, c’è sempre una probabilità di perdita di pacchetti perché né gli host intermedi né i collegamenti sono completamente affidabili. Pertanto, i pacchetti IP possono arrivare alla destinazione in un ordine alterato.
reassembly-opt
In generale, non tutti i casi d’uso richiedono un ordinamento rigoroso dei pacchetti. Ad esempio, il traffico voce e video è progettato per tollerare una certa quantità di perdita di pacchetti (perché la loro mancanza rappresenta un difetto pressoché inintelligibile dal fruitore: è probabile che non se ne accorga nemmeno o il disturbo sia piccolo e di brevissima durata: un burst o una fugace pixellatura anomala, per esempio) mentre la ritrasmissione dei pacchetti comporterebbe un aumento inaccettabile della latenza (e rappresenterebbe un disturbo ben più importante).
Tuttavia, quando un browser carica una pagina Web utilizzando HTTP (si osservi che parliamo di file di dimensioni molto inferiori rispetto ad uno stream audio/video), ci aspettiamo che le lettere e le parole su di essa vengano ordinate esattamente nello stesso modo in cui sono state pensate dal creatore della pagina. È così che nasce la necessità di un meccanismo di consegna dei pacchetti affidabile, ordinato e controllato dagli errori.
Come probabilmente avrai già notato, i problemi nel dominio di rete tendono a essere risolti introducendo sempre più protocolli. E in effetti, esiste un altro famoso protocollo Internet chiamato Transmission Control Protocol o semplicemente TCP.
TCP si basa sul suo protocollo sottostante, IP. L’obiettivo principale di TCP è fornire la consegna affidabile e ordinata di un flusso di byte tra le applicazioni. Pertanto, se inviamo il nostro testo (codificato) a un socket TCP su una macchina, può essere letto inalterato dal socket sulla macchina di destinazione. Per non preoccuparsi dei problemi di consegna dei pacchetti, HTTP si basa sulle capacità di TCP.
ip-tcp-payload-opt
Per ottenere una consegna in ordine e affidabile, TCP aumenta le informazioni di controllo di ogni blocco con il numero di sequenza di incremento automatico e il checksum. Dal lato ricevente, il riassemblaggio dei dati avviene in base non all’ordine di arrivo dei pacchetti, ma al numero di sequenza TCP. Inoltre, il checksum viene utilizzato per convalidare il contenuto dei blocchi in arrivo. I blocchi non corretti vengono semplicemente rifiutati e non riconosciuti. Il lato mittente dovrebbe ritrasmettere i blocchi che non sono stati riconosciuti. Ovviamente, per implementarlo è necessaria una sorta di buffering da entrambe le parti.
Su una singola macchina alla volta possono esserci molti processi che comunicano tramite socket TCP. Pertanto, dovrebbero esserci tanti numeri di sequenza e buffer indipendenti quante sono le sessioni di comunicazione. Per risolvere questo problema, TCP introduce il concetto di connessione. Semplificando un po’, una connessione TCP è una sorta di accordo tra la parte trasmittente e ricevente sui numeri di sequenza iniziali e lo stato corrente della trasmissione. È necessario stabilire una connessione (scambiando alcuni pacchetti di controllo all’inizio, il cosiddetto handshake), mantenerla viva (alcuni pacchetti devono essere inviati in entrambe le direzioni, altrimenti la connessione potrebbe scadere, il cosiddetto keepalive) e quando la connessione non serve più, va chiusa (scambiando qualche altro pacchetto di controllo).
Ultimo ma non meno importante… Un indirizzo IP definisce un host di rete nel suo insieme. Tuttavia, tra due host qualsiasi, potrebbero esserci molte connessioni TCP simultanee. Se le uniche informazioni di indirizzamento nei nostri blocchi fossero gli indirizzi IP, sarebbe praticamente impossibile determinare l’affiliazione dei blocchi con le connessioni. Pertanto, sono necessarie alcune informazioni di indirizzamento aggiuntive. Per questo, TCP introduce il concetto di porte. Ogni connessione ottiene una coppia di numeri di porta (uno per il mittente, uno per il destinatario) che identifica in modo univoco la connessione TCP tra coppie di IP. Quindi, qualsiasi connessione TCP può essere completamente identificata dalla seguente tupla: (IP di origine, porta di origine, IP di destinazione, porta di destinazione).
Implementazione di un semplice server TCP
È ora di esercitarsi! Proviamo a creare il nostro piccolo server TCP in Python. Per questo, avremo bisogno del modulo socket dalla libreria standard.
Per un novizio, la principale complicazione con i socket è l’esistenza di un rituale apparentemente magico di preparare i socket per funzionare. Tuttavia, combinare il background teorico dall’inizio di questo articolo con la parte pratica di questa sezione dovrebbe trasformare la magia in una sequenza di azioni significative.
Nel caso di TCP, i flussi di lavoro del socket lato server e lato client sono diversi. Un server attende passivamente la connessione dei client. A priori, l’indirizzo IP e la porta TCP del server sono noti a tutti i suoi potenziali client. Al contrario, il server non conosce gli indirizzi dei suoi client fino al momento in cui questi si connettono. Vale a dire, i client svolgono il ruolo di iniziatori della comunicazione connettendosi attivamente ai server.
Tuttavia, c’è di più oltre a questo. Sul lato server, ci sono in realtà due tipi di socket coinvolti: il suddetto socket del server in attesa di connessioni e, sorpresa, sorpresa – i socket client! Per ogni connessione stabilita, c’è un altro socket creato sul lato server, simmetrico alla sua controparte lato client. Pertanto, per N client connessi, ci saranno sempre N+1 socket sul lato server.
Creare i socket TCP del server
Quindi, creiamo un socket del server:
# python3
import socket
serv_sock = socket.socket(
socket.AF_INET, # set protocol family to 'Internet' (INET)
socket.SOCK_STREAM, # set socket type to 'stream' (i.e. TCP)
proto=0 # set the default protocol (for TCP it's IP)
)
print(type(serv_sock)) # <class 'socket.socket'>
— “Aspetta un attimo, ma… dov’è l’ int fd = open("/path/to/my/socket") che mi avevi promesso?”
La verità è che la chiamata di sistema open() è troppo limitata per il caso d’uso del socket perché non consente di passare tutti i parametri necessari, come famiglia di protocollo, tipo di socket, ecc. Pertanto, per i socket, è stato introdotta una chiamata di sistema dedicata socket(). Analogamente a open(), dopo aver creato un terminale per la comunicazione, socket() restituisce un descrittore di file che fa riferimento a tale endpoint. Per quanto riguarda parte mancante fd = ..., Python è un linguaggio orientato agli oggetti. Invece di funzioni, tende a utilizzare classi e metodi. Il modulo socket della libreria standard di Python (che abbiamo usato nel primo esempio sopra) è in realtà un OO-wrapper leggero attorno all’insieme di chiamate relative ai socket. Semplificando drasticamente, può essere pensata come qualcosa del genere:
class socket: # Yep, the name of the class starts from a lowercase letter...
# NDR: implementazione-fantoccio della libreria di sistsma.
def __init__(self, sock_family, sock_type, proto):
self._fd = system_socket(sock_family, sock_type, proto)
def write(self, data):
system_write(self._fd, data)
def fileno(self):
return self._fd
Cioè, se qualcuno ne avesse davvero bisogno, può ottenere il descrittore del file (un numero intero) come segue:
print(serv_sock.fileno()) # 3 or some other small integer
Associare il socket del server all’interfaccia di rete
Poiché, in generale, una singola macchina server può avere più di una scheda di rete, dovrebbe esserci un modo per associare il socket del server a una particolare interfaccia assegnando un indirizzo locale di questa interfaccia al socket:
# Use '127.0.0.1' to bind to localhost
# Use '0.0.0.0' or '' to bind to ALL network interfaces simultaneously
# Use an actual IP of an interface to bind to a specific address.
serv_sock.bind(('127.0.0.1', 6543))
Inoltre, bind() richiede che venga specificata una porta. Il server attenderà o, nel gergo della rete, ascolterà le connessioni client su quella porta.
Dopo questa chiamata, il sistema operativo rende il socket del server pronto per accettare le connessioni in entrata. Tuttavia, il nostro codice non è ancora pronto per questo. Ma prima, tocchiamo brevemente la parte del backlog.
Quando più client si connettono al server, il server conserva le richieste in arrivo in una coda, una struttura dati di tipo FIFO. In parole semplici, il parametro backlog specifica il numero di connessioni in sospeso che la coda di connessioni conterrà.
Come già sappiamo, la comunicazione di rete avviene tramite l’invio di pacchetti. Allo stesso tempo, TCP chiede di stabilire delle connessioni. Quindi, per stabilire una connessione TCP, un client e un server devono scambiare alcuni pacchetti di controllo (cioè senza dati effettivi) (il cosiddetto handshake). E a causa dei ritardi della rete, non è una procedura istantanea.
Di solito, TCP è implementato a livello di sistema operativo e nei nostri programmi non ci occupiamo dei dettagli di livello inferiore, come l’handshake. I parametri di backlog definiscono la dimensione della coda delle connessioni stabilite. Fino a quando il numero di client connessi non eccederà la dimensione del backlog, il sistema operativo stabilirà nuove connessioni e le metterà in coda. Tuttavia, quando il numero della connessione stabilita raggiunge la dimensione del backlog, qualsiasi nuova connessione verrà esplicitamente rifiutata o implicitamente ignorata (dipende dalle configurazioni del sistema operativo). Un sito sotto attacco dDOS di solito è congegnato per portare la coda di connessioni a questo stato.
L’accettazione di connessioni client
Per prelevare una connessione dalla coda del backlog, dobbiamo fare quanto segue:
client_sock, client_addr = serv_sock.accept()
Tuttavia, la coda delle connessioni stabilite potrebbe essere vuota. In tal caso, la chiamata accept() bloccherà l’esecuzione del programma fino a quando il client successivo non si connette (o il programma viene interrotto da un segnale, ma è fuori tema per questo articolo).
Dopo aver accettato la prima connessione client, ci saranno due socket lato server: il già familiare serv_sock nello stato LISTEN e il nuovo client_sock nello stato ESTABLISHED. È interessante notare che il client_sock sul lato server e il socket corrispondente sul lato client sono i cosiddetti endpoint peer (terminali accoppiati). Cioè sono dello stesso tipo, i dati possono essere scritti o letti da ognuno di essi ed entrambi possono essere chiusi usando la chiamata close() che termina in modo efficiente la connessione. Nessuna di queste azioni influenzerà comunque il serv_socket in ascolto.
Ottenere l’indirizzo IP e la porta del socket client
Diamo un’occhiata agli indirizzi degli endpoint peer del server e del client. Ogni socket TCP può essere identificato da due coppie di numeri: (IP locale, porta locale) e (IP remoto, porta remota).
Per conoscere l’IP remoto e la porta del client appena connesso, il server può ispezionare la variabile client_addr restituita dalla chiamata (qualora sia effettuata con successo) accept():
print(client_addr) # E.g. ('127.0.0.1', 54614)
In alternativa, il metodo socket.getpeername() dell’endpoint lato server client_sock può essere utilizzato per apprendere l’indirizzo remoto del client connesso. E per conoscere l’indirizzo locale assegnato dal sistema operativo del server per l’endpoint peer lato server, è possibile utilizzare il metodo socket.getsockname().
Nel caso del nostro server potrebbe assomigliare a questo:
serv_sock:
laddr (ip=<server_ip>, port=6543)
raddr (ip=0.0.0.0, port=*)
client_sock: # peer
laddr (ip=<client_ip>, port=51573) # 51573 is a random port assigned by the OS
raddr (ip=<server_ip>, port=6543) # it's a server's listening port
Inviare e ricevere dati tramite socket
Ecco un semplice esempio di ricezione di alcuni dati dal client e poi di invio (il cosiddetto echo-server):
# echo-server
data = client_sock.recv(2048)
client_sock.send(data)
Bene, dove sono le chiamate read() e write() promesse? Sebbene sia possibile utilizzare queste due chiamate con descrittori di file socket, come con la chiamata di sistema socket(), esse non consentono di specificare tutte le potenziali opzioni necessarie. Pertanto, per i socket, sono state introdotte le chiamate di sistema send() e recv(). Nel manale Unix man 2 send si legge:
The only difference between send() and write() is the presence of flags. With a zero flags argument, send() is equivalent to write().
e su man 2 recv si legge
The only difference between recv() and read() is the presence of flags. With a zero flags argument, recv() is generally equivalent to read().
Dietro l’apparente semplicità del frammento di cui sopra c’è un problema serio. Entrambe le chiamate recv() e send() funzionano effettivamente attraverso i cosiddetti buffer di rete. La chiamata a recv() ritorna non appena alcuni dati appaiono nel buffer sul lato ricevente. E, naturalmente, alcuni raramente significa tutti. Pertanto, se il client desidera trasmettere, diciamo 1800 byte di dati, recv() può restituire non appena vengono ricevuti i primi 1500 byte (i numeri sono arbitrari in questo esempio) perché la trasmissione è stata suddivisa in due parti.
Lo stesso vale per il metodo send(). Restituisce il numero effettivo di byte che sono stati scritti nel buffer. Tuttavia, se il buffer ha meno spazio disponibile rispetto al dato tentato, ne verrà scritta solo una parte. Quindi, spetta al mittente assicurarsi che il resto dei dati venga eventualmente trasmesso. Fortunatamente, Python fornisce un pratico helper socket.sendall() che fa il ciclo di invio per te sotto il cofano.
i messaggi devono essere di lunghezza fissa (yuck) o essere delimitati (shrug) o indicare quanto sono lunghi (molto meglio) o terminare interrompendo la connessione.
Rilevare quando il client ha terminato di inviare (shutdown)
Si noti che le prime tre opzioni possono comunque portare a una situazione in cui il socket sul lato server attenderà che la chiamata a recv() restituisca il suo valore per un tempo indefinito. Può succedere se il server desidera ricevere K messaggi dal client mentre il client desidera inviare solo M messaggi, dove M < K. Pertanto, spetta ai progettisti di protocollo di livello superiore decidere le regole di comunicazione.
Tuttavia, esiste un modo semplice per indicare che il client ha terminato l’invio. Il socket client può eseguire uno shutdown(how) della connessione specificando per il parametro how il valore SHUT_WR. Ciò porterà a una chiamata recv() sul lato server che restituisce 0 byte. Pertanto, possiamo riscrivere il codice ricevente come segue:
chunks = []
while True:
data = client_sock.recv(2048)
if not data:
break
chunks.append(data)
Chiudere i socket
Quando si è finito con un socket, bisogna chiuderlo:
socket.close()
La chiusura esplicita di un socket comporterà lo svuotamento dei suoi buffer e la chiusura regolare della connessione.
Semplice esempio di server TCP
Infine, ecco il codice completo dell’echo-server TCP:
# python3
import socket
# Create server socket.
serv_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, proto=0)
# Bind server socket to loopback network interface.
serv_sock.bind(('127.0.0.1', 6543))
# Turn server socket into listening mode.
serv_sock.listen(10)
while True:
# Accept new connections in an infinite loop.
client_sock, client_addr = serv_sock.accept()
print('New connection from ', client_addr)
chunks = []
while True:
# Keep reading while the client is writing.
data = client_sock.recv(2048)
if not data:
# Client is done with sending.
break
chunks.append(data)
print('Received data: ', chunks)
client_sock.sendall(b''.join(chunks))
client_sock.close()
Salvatelo su server.py ed eseguitelo tramite python3 server.py
Nota di traduzione
Ho leggermente modificato i sorgenti per rendere più interattiva la comunicazione client-server.
Semplice implementazione del client TCP.
Le cose sono molto più semplici dal lato client. Non esiste una cosa come un socket di ascolto sul lato client. Dobbiamo solo creare un singolo endpoint socket e collegarlo connect() al server prima di inviare alcuni dati:
# python3
import socket
# Create client socket.
client_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Connect to server (replace 127.0.0.1 with the real server IP).
client_sock.connect(('127.0.0.1', 6543))
# Send some data to server.
str = input('Please, send some message to your mate: ')
client_sock.sendall(str.encode('ascii'))
client_sock.shutdown(socket.SHUT_WR)
# Receive some data back.
chunks = []
while True:
data = client_sock.recv(2048)
if not data:
break
chunks.append(data)
print('Received back ', repr(b''.join(chunks)))
# Disconnect from server.
client_sock.close()
Salvatelo su client.py ed eseguitelo tramite python3 client.py.
Test (aggiunta mia alla traduzione)
Mettiamo il server in ascolto:
$ python3 server.py
<in attesa>
Apriamo una seconda console (Ctrl+T su Ubuntu) e digitiamo
$ python3 client.py
Please, send some message to your mate: Ciao Ivan
Received back b'Ciao Ivan'
Torniamo nella console del server e vedremo:
New connection from ('127.0.0.1', 55484)
[b'Ciao Ivan']
Nota che se spediamo un secondo messaggio con il client, ancorché la porta del client è sempre 6543, la porta del server sarà diversa:
Client
$ python3 client.py
Please, send some message to your mate: Ciao Marco
Received back b'Ciao Marco'
Server:
New connection from ('127.0.0.1', 55488)
[b'Ciao Marco']
Per curiosità mi faccio stampare tutta la struttura dati del socket, ed è molto istruttivo:
$ python3 server.py
New connection from ('127.0.0.1', 55492)
Socket <socket.socket fd=4, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 6543), raddr=('127.0.0.1', 55492)>
Received data: [b'ciao Mamma']
Come si vede, il numero di porta è stato incrementato di 4 unità, en passant il file descriptor è 4 e il left address è il client (‘127.0.0.1’, 6543) ed il right address è il server (‘127.0.0.1’, 55492).
È istruttivo anche vedere con nestat -at che c’è un server TCP in ascolto sulla porta 6543:
$ netstat -at
Connessioni Internet attive (server e stabiliti)
Proto CodaRic CodaInv Indirizzo locale Indirizzo remoto Stato
.........
tcp 0 0 192.168.122.1:domain 0.0.0.0:* LISTEN
tcp 0 0 localhost:6543 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:11211 0.0.0.0:* LISTEN
.........
Socket server vs HTTP server
Il server che abbiamo implementato sopra è chiaramente un semplice server TCP. Tuttavia, non è (ancora) un server web. Mentre (quasi?) ogni server web è un server TCP, ovviamente non tutti i server TCP sono un server web. Per trasformare questo server in un server web, dovremmo insegnargli come gestire HTTP. Cioè. i dati trasmessi tramite socket dovrebbero essere formattati secondo l’insieme di regole definite dall’Hypertext Transfer Protocol e il nostro codice dovrebbe saperli analizzare.
In conclusione
Memorizzare le cose senza capirle è una strategia scadente per uno sviluppatore (per ogni professione, aggiungerei, NdR). La programmazione di socket è un esempio perfetto di quanto leggere il codice senza il background teorico possa essere veramente frustrante. Tuttavia, una volta acquisita la comprensione delle parti mobili e dei vincoli, tutte queste manipolazioni magiche con l’API del socket si trasformano in un insieme di azioni che hanno un senso. E tu, non aver paura di dedicare tempo alle basi. La programmazione di rete è una conoscenza fondamentale che è vitale per lo sviluppo e la risoluzione dei problemi di successo di servizi Web avanzati.
Tra il mondo Unix e il mondo Windows esistono molte barriere che complicano l’interscambio di dati: una di questa barriere è la codifica del carattere di “a capo”.
Nell’epoca del Cloud, della Blockchain e dell’Intelligenza Artificiale sembra assurdo doversi confrontare con problemi come questo, ma succede.
Il carattere di “a capo”, come quello che fa suonare un campanello o il carattere di “spazio”, sono semplicemente caratteri come tutti gli altri, ognuno con la propria codifica. Quando pensiamo ad un file di testo – come ad un video o ad un audio – dovremmo sempre pensarlo come uno stream ininterrotto di bit tutti in fila. In binario non esistono “a capo” ma è solo una nostra rappresentazione perché siamo abitutati a fogli non infiniti. In realtà sarebbe meglio pensare ad un nastro infinito come quello della macchina di Turing.
Nella codifica ASCII (American Standard Code for Information Interchange), che è una delle codifiche più vecchie da cui si sono evolute quelle moderne fino all’onnicomprensivo UTF-16, il carattere di “a capo” o “nuova linea” è codificato con il numero decimale 10, in esadecimale A, in ottale 0x12, in binario a 8 bit 00001100. Il suo simbolo è LF (Line-Feed) e spesso viene visualizzato negli editor di testo con ^M e viene codificato con la sequenza \n nell’ambito delle espressioni regolari.
Per indicare il carattere corrispondente ad un codice x useremo questa notazione: CHR(x)
Sennonché Microsoft ha codificato in modo custom il carattere di a capo come l’unione di due caratteri: nei file prodotti con Windows troveremo che il carattere di a capo è CR + LF (Carriage-Return + Line-Feed), quindi CHR(10) + CHR(12) . Per Linux/Unix e MacOSX (che è un fork di Unix) è semplicemente LF.
Carriage Return sarebbe il movimento di ritorno all’inizio della riga, ma (soprattutto per chi ricorda le macchine per scrivere come la Olivetti Lettera 22) c’è anche l’avanzamento di una riga del foglio dovuto idealmente alla rotazione del rullo che trasporta la carta, che è proprio il Line Feed. Tutte cose che ormai si sono perse nella nebbia.
Il carattere di CR nella tabella ASCII è identificato con il codice 14 = Hex D = 0x14 = 00001110.
Negli editor vediamo sempre prima il carattere ^M e poi la linea va a capo, quindi la sequenza in cui si succedono i caratteri è CR + LF.
Quando importiamo in Linux un file di testo puro proveniente da Windows (a proposito: non sto parlando di cose antiquate e sorpassate: nella scrittura di software utilizzare file di testo puro è la regola perché i sorgenti sono e rimangono scritti così), vedremo alla fine di ogni riga il carattere ^M e poi il resto a capo.
Di solito gli editor possono anche avere l’opzione di ignorare e non mostrare i caratteri di CR (^M) per cui aprendo il file non vediamo niente di strano.
Ma è possibile visualizzarli con questi comandi per esempio:
$ cat -v testo.txt
ciao,^M
come va?
Per rimuovere i caratteri di CR ci sono molti modi, ad esempio utilizzando sed (Stream EDitor, potentissimo) oppure più semplicemente questo:
$ dos2unix testo.txt
$ cat -v testo.txt
ciao,
come va?
Poi c’è anche da dire che utility come FTP operano automaticamente la conversione quando si trasferiscono file tra sistemi eterogenei per cui di solito non ci preoccupiamo di questo aspetto. Di solito.
Con Linux (Ubuntu) ci sono diversi modi di sincerarsi di quali server dns si stanno usando, ma quello migliore mi sembra questo:
$ nmcli dev show | grep DNS
IP4.DNS[1]: 10.1.23.101
IP4.DNS[2]: 10.1.23.102
Anche questo non è male:
$ systemd-resolve --status
Global
Protocols: -LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
resolv.conf mode: foreign
DNS Domain: -- home myCustomer.it
Link 2 (enp1s0)
Current Scopes: DNS
Protocols: +DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Current DNS Server: 10.1.23.101
DNS Servers: 10.1.23.101 10.1.23.102
DNS Domain: myCustomer.it
Link 3 (wlp2s0)
Current Scopes: none
Protocols: -DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Link 4 (virbr0)
Current Scopes: none
Protocols: -DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Lo facciamo per migliorare l'esperienza di navigazione e per mostrare annunci personalizzati. Il consenso a queste tecnologie ci consentirà di elaborare dati quali il comportamento di navigazione o gli ID univoci su questo sito. Il mancato consenso o la revoca del consenso possono influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.














Commenti recenti