Quando si esegue uno script Bash ci sono due modalità principali da impiegare, che hanno conseguenze diverse sull’ambiente della shell. 1. Esecuzione diretta (./script.sh) Quindi può solo leggere le variabili di ambiente della shell madre …
Preso dalla curiosità di ripassare l’assembly (tanti anni fa studiai il Motorola 68000) ho scritto una guida ordinata che illustra passo per passo come scrivere un semplice programma Assembly in real-mode (16 bit), confezionarlo come …
GeoGebra è un software open‑source per la didattica della matematica e della geometria dinamica. Quello che intendiamo qui con “geometria dinamica” è un approccio all’insegnamento e alla sperimentazione della geometria in cui le costruzioni non …
Negli ambienti desktop basati su GNOME, come Ubuntu, è possibile impostare uno sfondo che cambia automaticamente nel tempo, come una presentazione. Quello che molti non sanno è che GNOME supporta nativamente gli slideshow tramite file …
Negli ultimi giorni ho condotto una piccola sperimentazione con Whisper, il modello di riconoscimento vocale automatico (ASR) open source sviluppato da OpenAI. L’obiettivo era duplice: Cos’è Whisper Whisper è un sistema di riconoscimento vocale automatico …
La Java Virtual Machine è un software che fornisce un ambiente operativo virtuale per applicazioni Java.
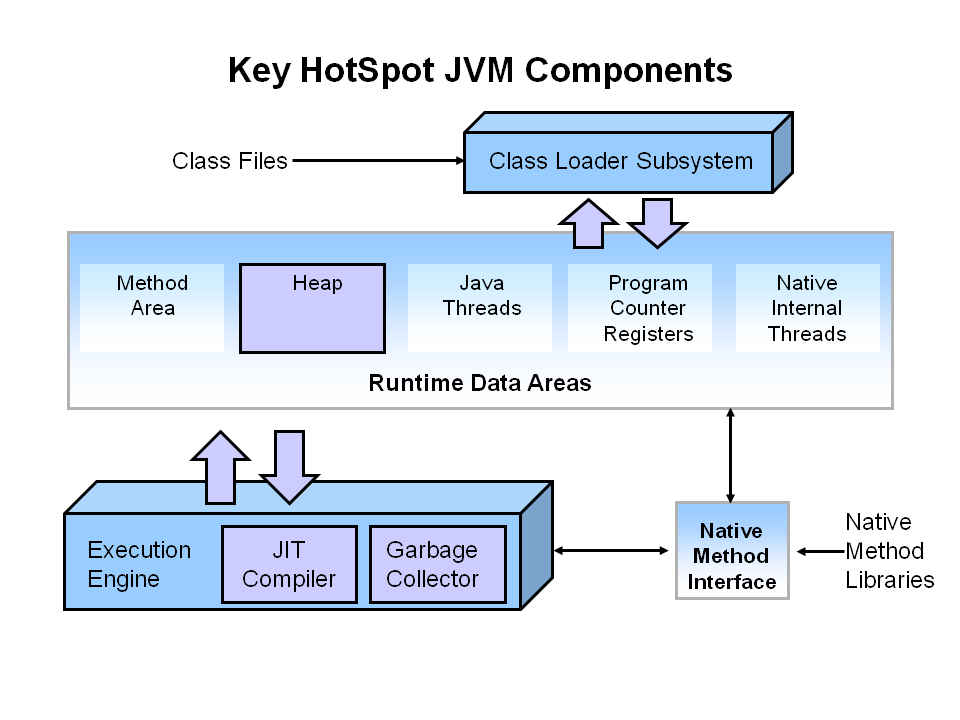
L’architettua Java Hotspot è composta di tre elementi
il motore di esecuzione:
è composto di un compilatore a tempo immediato (just in time o JIT compiler) che traduce il codice in chiaro in bytecode (compilazione) al momento in cui deve essere utilizzato
e di un garbage collector (che è l’aspetto su cui ci focalizziamo in questo articolo), un collettore di spazzatura che fa la raccolta differenziata degli oggetti usati e li rimuove con una specifica politica
l’area dati di esecuzione(runtime data area) che è una memoria organizzata in cui vengono caricati i metodi, i threads, lo heap (che è la zona che ci interessa) e altre zone. In particolare lo heap (mucchio) è la zona riservata ai dati transienti trattati dall’applicazione Java
il class loader che è un regista che istanza in memoria RAM gli oggetti e i metodi quando richiesti
Gestione della memoria in Java: Architettura HotSpot JVM
Lo heap
Lo heap è una zona di memoria RAM nella quale Hotspot gestisce i dati dell’applicazione. In questa zona viene implementata una vera e propria raccolta differenziata degli oggetti in base all’età di occupazione. L’età di occupazione è calcolata con un contatore per ogni oggetto: ogni volta che viene istanziato, incremento il suo contatore. Ogni volta che lo distruggo (imposto la variabile) a null, lo decremento di 1. Quando il contatore raggiunge 0 è tempo di buttare via l’oggetto. Quindi programmaticamente è buona norma impostare a null una variabile se non la si vuole più usare, perché così riesco a raggiungere la condizione che scatena l’evento minor garbage collection che consiste nello spostamento o l’eliminazione fisica dell’area di memoria che contiene la variabile.
I dati vengono diversificati in tre zone “temporali”:
Young Generation
Old Generation
Permanent Generation
Struttura dello Java Heap (Wikipedia)
La zona Young Generation è quella in cui vengono allocati tutti gli oggetti istanziati da poco tempo; è a sua volta suddivisa in Eden (oggetti appena creati) e Survivor. Il raccoglitore differenziato (minor garbage collector) sposta gli oggetti dall’Eden alla zone di Sopravvivenza e da qui alla Old Generation. Uno spostamento da Young a Old è considerato un evento di minor garbage collcection.
Gli oggetti un po’ più datati vivono nella Old generation; vengono spostati da qui dal racccoglitore differenziato maggiore ed eliminati, Questo evento è condierato una major garbage collection.
Nella zona Permament Generation vengono collezionati metodi e classi, che sono considerati metadati. Anche l’eliminazione da parte del GC degli oggetti di questa zona è considerata major.
Quindi gli oggetti vengono spostati gradualmente da una zona all’altra fino alla loro eliminazione completa.
Come si produce garbage?
Consideriamo questo programma
public void factory (int num) {
Die d1 = new Die();
Die d2 = new Die(num);
int numfaces = d1.getFaces();
Die d3 = d2;
}
Questo metodo istanzia due oggetti d1 e d2, poi un terzo d3; e una variabile locale numfaces.
Ci sono due tipi di variabili: le variabili di istanza o campi e le variabili locali o parametri.
Le variabili di istanza sono le aree di variabili dove memorizziamo le proprietà della classe
Le variabili locali sono variabili temporanee definite all’interno del metodo. I parametri sono semplicemente variabili locali di Java con la differenza che esse non vengono inizializzate dal metodo ma dal programma chiamante.
Il tempo di vita delle variabili locali dal tempo di esecuzione del metodo che le contiene, da quando viene chiamato a quando ritorna al programma chiamante.
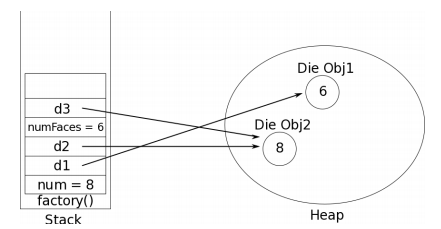
A questo proposito dobbiamo tenere a mente che le variabili locali o i parametri di tipo primitivo vengono memorizzati in un’area di memoria detto stack (pila); ogni metodo ha il suo stack. Mentre le variabili locali e i parametri di tipo oggetto vengono invece memorizzati nello heap. Tuttavia nello stack vengono mantenuti i riferimenti (i puntatori) a questi oggetti dello heap, come illustrato nella figura seguente
Stack e heap per il metodo Java factory
Il tempo di vita dell’oggetto è in sostanza il tempo di esecuzione del metodo. Ora d1, d2 e d3 sono variabili locali del metodo sopra.
Se aggiungiamo una ulteriore riga alla fine
d1 = d3
cosa succede?
Ciò che succede è che ogni riferimento all’oggetto Die 1 viene perso e l’oggetto può essere rimosso dalla RAM dal garbage collector.
L’algoritmo di gestione dello hep consente, soprattutto per programmi di grandi dimensioni, di rendere efficiente la raccolta differenziata.
Un algoritmo più ingenuo potrebbe passare in rassegna tutti gli oggetti istanziati e controllare se il programma in qualche punto li chiama (cioè: se esiste un riferimento). Gli oggetti lasciati fuori da questa scansione possono essere buttati via. Però questo algoritmo diventa rapidamente inefficiente all’aumentare del numero di oggetti istanziati; ovvero, in ultima analisi, dalla complessità del programma.
L’analisi che ha portato a questo tipo di gestione, si rifaceva allo studio della quantità di memoria allocata per oggetti che venivano eliminati quasi subito: ad esempio iterators che duravano per un solo ciclo. Questa statistica ha messo in luce la preponderanza di molti oggetti che durano poco, una specie di mortalità infantile, per cui ci si è concentrati su algoritmi che liberavano prima questa parte di memoria.
Tipi di GC
I garbage collectors di Hotspot sono 4:
serial
parallel
CMS
G1
Questi si comportano sostanzialmente in modo diverso, ma dobbiamo pensare che ci sono processi per così dire “attivi” che portano avanti l’esecuzione del programma principale e processi per così dire “passivi” che invece si occupano di fare pulizia. A volte i secondi devono interrompere i primi e questa modalità è detta “Stop-the-world mode GC”.
Serial è un unico thread che si occupa di eliminare molti garbage uno alla volta.
Parallel si occupa di eventi minori (come lo spostamento da un contentore all’altro) e ogni garbage è spostato da un thread separato, quindi si gestiscono più segmenti alla volta.
CMS (Concurrent Mark-sweep) vengono marcati e cancellati più segmenti tramite thread paralleli per minimizzare l’arresto del programma principale (per minimizzare gli Stop-the-world).
G1 (Garbage First) è un’alternativa concorrente di CMS.
Compattazione
Il modo di gestire la cancellazione degli oggetti non più usati è allo stesso modo critica: si possono adottare diverse tecniche, la più ingenua è cancellare loggetto sic et simpliciter (tecnica Mark-Sweep), ma questo reimpirebbe la memoria di “buchi” e sarebbe diffficile riutilizzae lo spazio reso disponibile.
Mark-sweep
Quindi ci sono dei metodi più evoluti, come il Copy o il Mark-Compact che riallocano i dati da cancellare in modo da renderli contigui e creare delle zone libere più grandi possibili e continue (senza buchi).
Sto lavorando ad una applicazione GIS, per cui mi documento sugli aspetti teorici di base dell’applicazione.
Queste informazioni si trovano sul sito di ArcGIS anche se in questo lavoro sto utilizzando principalmente QGIS.
Faccio una breve premessa.
Raster è sinonimo di reticolo: le informazioni di un file raster sono l’unione di una informazione geometrica (coordinate piane bidimensionali) e del valore scalare di una o più grandezze associate al punto geometrico:
(x, y, g_1, g_2, \ldots)
Più specificatamente, nell’ambito GIS, l’informazione geometrica è in realtà un’informazione geografica, una copia di coordinate piane che in genere sono associate alla rappresentazione di una porzione del geoide secondo un determinato sistema di riferimento locale.
C’è infatti il problema matematico di rappresentare localmente le coordinate curvilinee di una sfera su un piano attraverso una mappatura univoca e che deformi il meno possibile. Ci sono molti modi di mappare una superficie sferica su una piana e questi modi prendono il nome di proiezioni. Queste nozioni fanno parte della disciplina della Matematica che sia chiama Geodesia.
Lo standard di riferimento per i file raster utilizzati in cartografia è il GeoTIFF. Nei riferimenti web c’è un link alle specifiche.
I set di dati raster rappresentano le caratteristiche geografiche ottenute dividendo il terreno in celle discrete quadrate o rettangolari disposte su una griglia. Ogni cella ha un valore che viene utilizzato per rappresentare una grandezza fisica di quella posizione, come la temperatura, l’elevazione o un valore spettrale.
raster 1
I set di dati raster sono comunemente usati per rappresentare e gestire immagini, modelli digitali di elevazione e numerosi altri fenomeni. Spesso i raster vengono utilizzati per rappresentare feature di punti, linee e poligoni. Nell’esempio seguente, puoi vedere come una serie di linee e poligoni (set di dati vettoriali) viene rappresentata come un set di dati raster.
Un diagramma vettoriale rappresentato come un raster
I raster possono essere utilizzati per rappresentare tutte le informazioni geografiche (caratteristiche, immagini e superfici) e dispongono di un ricco set di operatori di geoprocessing analitico. Oltre ad essere un tipo di dati universale per contenere le immagini in GIS, i raster sono anche ampiamente utilizzati per rappresentare le caratteristiche, consentendo a tutti gli oggetti geografici di essere utilizzati nella modellazione e nell’analisi basate su raster.
Raster nel geodatabase
Un raster è un insieme di celle disposte in righe e colonne — una matrice bitmap — ed è un set di dati comunemente usato in GIS. Gli utenti in genere utilizzano molti file raster, tuttavia molti utenti vedono una crescente necessità di gestire i dati raster, insieme alle altre informazioni geografiche, in un DBMS. Il geodatabase fornisce un mezzo molto efficace per la gestione dei dati raster.
Strategie di gestione raster
Sono importanti due strategie di gestione dei dati per i raster:
Approvvigionamento di raster: mettere rapidamente “in gioco” i set di dati raster nel tuo GIS significa che molto probabilmente li utilizzerai così come sono, in genere come una serie di file raster. Può trattarsi di una serie di file indipendenti oppure è possibile utilizzare una tecnologia come l’estensione Image per ArcGIS for Server per gestire e servire questi set di dati esistenti come una raccolta.
Raster nel geodatabase: questa strategia è utile quando si desidera gestire i raster, aggiungere comportamenti e controllare lo schema; gestire un insieme ben definito di set di dati raster come parte del tuo DBMS; necessità di ottenere prestazioni elevate senza perdita di contenuti e informazioni (nessuna compressione); e un’unica architettura dati per la gestione di tutti i tuoi contenuti.
Proprietà geografiche dei dati raster
In genere vengono registrate quattro proprietà geografiche per tutti i set di dati raster. Questi diventano utili per la georeferenziazione e aiutano a spiegare come sono strutturati i file di dati raster. Questo concetto è importante da capire: aiuta a spiegare come vengono archiviati e gestiti i raster nel geodatabase.
I set di dati raster hanno un modo speciale per definire la posizione geografica. Una volta che le celle o i pixel possono essere georeferenziati con precisione, è facile avere un elenco ordinato di tutti i valori delle celle in un raster. Ciò significa che ogni set di dati raster ha in genere
un record di intestazione che ne contiene le proprietà geografiche e
il corpo del contenuto è semplicemente un elenco ordinato di valori di cella.
Le proprietà geografiche per un raster in genere includono
il suo sistema di coordinate
Una coordinata di riferimento o una posizione x,y (in genere l’angolo superiore sinistro o inferiore sinistro del raster)
le dimensioni della cella
Il conteggio di righe e colonne
Queste informazioni possono essere utilizzate per trovare la posizione di una cella specifica. Avendo queste informazioni disponibili, la struttura dei dati raster elenca tutti i valori delle celle in ordine dalla cella in alto a sinistra lungo ogni riga alla cella in basso a destra, come illustrato di seguito.
Diagramma dei valori delle celle
La tabella dei blocchi raster nel geodatabase
I dati raster sono in genere di dimensioni molto maggiori rispetto alle funzionalità e richiedono una tabella laterale per l’archiviazione. Ad esempio, una tipica ortoimmagine può avere fino a 6.700 righe per 7.600 colonne (più di 50 milioni di valori di cella).
Per ottenere prestazioni elevate con questi set di dati raster più grandi, un geodatabase raster viene suddiviso in riquadri più piccoli (denominati blocchi) con una dimensione tipica di circa 128 righe per 128 colonne o 256 x 256. Questi blocchi più piccoli vengono quindi tenuti in un lato tabella per ogni raster. Ogni riquadro separato è contenuto in una riga separata in una tabella a blocchi come mostrato di seguito.
Diagramma di visualizzazione della tabella a blocchi
Questa semplice struttura significa che solo i blocchi per un’estensione devono essere recuperati quando sono necessari, invece dell’intera immagine. Inoltre, i blocchi ricampionati utilizzati per costruire le piramidi raster possono essere archiviati e gestiti nella stessa tabella di blocchi come righe aggiuntive.
Ciò consente di gestire raster di enormi dimensioni in un DBMS; produrre prestazioni molto elevate; e fornire un accesso multiutente e sicuro.
Estensione dei raster
I raster sono molto e sempre più utilizzati nelle applicazioni GIS. Il geodatabase può gestire i raster per molti scopi: come singoli insiemi di dati, raccolte logiche di insiemi di dati e attributi di immagini nelle tabelle.
Una serie di funzionalità del geodatabase consente agli utenti di estendere il modo in cui gestiscono le proprie informazioni raster come segue:
Usa…
… se devi…
Set di dati raster
Gestire set di dati di immagini contigue molto grandi e raster a mosaico.
Set di dati a mosaico
Un mosaico di dati è un modello di dati che è un ibrido di un catalogo raster e un set di dati raster, che rappresenta una vista al volo di un catalogo raster. Consentono di archiviare, gestire, visualizzare ed eseguire query su raccolte di dati di immagini raster.
Cataloghi raster
Gestire un layer raster affiancato, in cui ogni riquadro è un raster separato.
Gestire qualsiasi serie di raster in un DBMS
Gestire una serie temporale raster.
Colonne di attributi raster nelle tabelle
Archivia immagini o documenti scansionati come attributi nelle tabelle.
Premetto che, a quanto ho visto, non c’è un vero e proprio standard in Laravel per gestire chiamate asincrone (AJAX). Quindi il tutto rimane sempre un po’ sporco perché si è costretti a mescolare il codice generando, ad esempio, codice HTML al volo con Javascript. Non ho trovato un modo diverso.
Laravel ci viene incontro con le rotte, i controller, ma il momento topico di AJAX, cioè il momento in cui un singolo brano della pagina web viene aggiornato asincroncamente, è del tutto dirty.
Ma andiamo con ordine. Il mio esempio è una semplice form di ricerca in un tabella che visualizza i risultati mano a mano che si digita nella casella di testo.
Step 1: rotta con la quale invocare il server
La chiamata server to server è definita nel file routes/web.php oppure in route/api.php ed è la seguente
Definisco cioè una nuova rotta che viene invocata con il metodo POST con la quale utilizzerò un nuovo metodo del controller.
Nota: il metodo POST implica che il payload (la stringa di ricerca) sia trasmesso al server nel corpo del messaggio, non nell’URL. Quindi nonsi deve aggiungere la stringa di ricerca nell’url:
Il controller implementa un nuovo metodo, search(), che accetta un parametro di ingresso che è la Request che contiene la stringa che scriveremo nella casella di testo, esegue una query e ritorna il recordset con encoding JSON:
public function search(Request $request)
{
$name = $request->all()['name'];
$companies = Company::where('name', 'LIKE', '%'.$name.'%')->get();
return json_encode($companies);
}
So far so good.
Step 3: il controller per il Frontoffice
Ho creato un secondo controller che ha il ruolo di disegnatore della form del frontoffice: non è strettamente necessario ma ho in mente una serie di funzinalità che non sono soltanto inerenti al modello Company per cui astraggo da quest’ultimo.
<?php
namespace App\Http\Controllers;
use App\Models\Company;
use Illuminate\Http\Request;
class FrontofficeController extends Controller
{
function index()
{
return view('frontoffice.index');
}
}
Nota 1: La casella di testo che servirà da trigger per la chiamata AJAX si chiama #name.
Nota 2: c’è un blocco <tbody/> che andrà popolato asincronicamente
Step 5: jQuery does the magic!
Questo metodo, anche se lo trovate in 10000 forum, ha una sua complessità che spiego un po’ alla volta.
L’ho implementato dentro al file <APP>/resources/layouts/app.blade.php, anche se potrei isolarlo in un file javascript a parte e includerlo nel blocco HTML di head, tra i tag di <script>:
L’evento che scatena il Javascript è keyup, quando rilascio il tasto parte la chiamata asincrona:
Leggo il valore della casella di testo (linea 11); se nella variabile name c’è qualcosa, preparo la ricerca AJAX (linea 15), predisponendo il metodo POST (linea 16), l’url che ho definito nella rotta (linea 17) ed il passaggio dati nel corpo del messaggio HTTP (linea 18).
Se il servizio web risponde con un 200 (linea 19) creo i tag HTML di riga contenenti i risultati provenienti in JSON dal servizio web (il controller infatti li codifica in JSON) . Terminato il ciclo metto tutto il contenuto all’interno dei tag <tbody> (linea 29).
Nota che il tbody viene riscritto ad ogni pressione del tasto sulla tastiera.
Quest’ultimo Step è un po’ messy, si mescolano in un solo file HTML, Blade (e fin qui OK) ma anche Javascript. È una soluzione sporca, che non mi piace. Il problema è che qui affido la generazione dell’HTML ad un programma Javascript anziché a Blade. In sostanza però la logica di generazione del’HTML è in un file blade, quindi a rigore non starei derogando del tutto dal paradigma MVC.
Ultimo step: il csfr_token
Eh, se avete letto con attenzione fin qui, vi sarete chiesti come mai sorvolavo sempre su questo aspetto. Era importante dedicargli una sezione a parte.
Come detto in quest’altro articolo, è importante verificare che l’interrogzione del webservice search sia fatta dal sito stesso e non da qualcun altro, per evitare i problemi anche gravi conseguenti alla non adozione di contromisure.
La tecnica è quella di aggiungere al form html il tag @csfr che fa inviare al server una stringa complessa che poi deve venire controllata lato server. Siccome solo il server conosce questa stringa ci siamo protetti dagli abusi.
Il tag @csfr si può anche definire in un tag meta dellHTML e leggerlo poi in sede di servizo web confrontandolo con quello che ci arriva.
In realtà dobbiamo solo preoccuparci della trasmissione del token in quanto già Laravel controlla per noi la congurenza: se non arriva il token arriva con un valore sbagiato il server Apache emetterà un errore 419 e non funzionerà i servizio.
Il token può essere generato con la direttva @csfr scritta nel Form html , oppure con la funzione di blade {{csrf_token()}}, oppure inserito in un tag meta dell’intestazione html:
Visto che è la stessa pagina posso anche calcolarlo direttamente (come ho fatto in linea 12) per poi essere spedito in più modi al server; o nel payload della richesta (linea 18) oppure nell’intestazione HTTP (linee 2-6). O in entrambe.
L’omissione di questo passaggio provoca un errore 419 (unknown status).
È tutto.
Riferimenti in rete
Sono partito da questo, facendo poi tutte le modifiche e le migliorie per adattarlo al mio caso.
La localizzazione (o internationalization o i18n) di Laravel è già gestita da un apposito middleware. Seguiamo questi pochi passi necessari ad atttivare la funzionalità multilingua per un’applicazione Laravel.
Attivazione e configurazione del middleware i18n
$ php artisan make:middleware Localization
Questo comando crea un nuovo file in app/Http/Middleware/Localization.php che va personalizzato se vogliamo gestire la lingua con le variabili di sessione. L’alternativa sarebbe specificare sempre in ogni rotta la lingua che si vuole usare. Un incubo!
Modifichiamo così il file:
public function handle(Request $request, Closure $next)
{
if (Session::has('locale')) {
App::setLocale(Session::get('locale'));
}
return $next($request);
}
Con il comando setLocale si valorizza la lingua usata in quel momento dall’applicazione con il valore contenuto dalla variabile di sessione.
Configurazione della rotta per lo switch della lingua
Ora occorre un metodo per fare lo switch e lo facciamo in una rotta che scriviamo in routes/web.php:
Route::get('language/{locale}', function ($locale) {
app()->setLocale($locale);
session()->put('locale', $locale);
return redirect()->back();
});
Possiamo anche scegliere di portare il codice che si trova nella funzione anonima dentro al controller HomeController.
Creazione dei file di localizzazione
Poi creiamo due file di lingua dentro a resources/lang/ e li chiamiamo en.json e it.json. Possiamo fare quanti file vogliamo, attenzione che ad ogni rotta deve corrispondere un file!
Per esempio un estratto del file italiano può essere il seguente:
Ora inseriamo i comandi per cambiare lingua nell’header dell’applicazione: lo facciamo in un modo grezzo che può essere migliorato, ma è questione di Blade e Vue:
Sostituire tutte le stringhe cablate con i segnaposto
Qui si può vedere anche come vengono utilizzati i segnaposto definiti in resources/lang: occorre sostituire ad esempio la stringa “Companies” cablata nell’HTML/Blade con il segnaposto {{__('Companies')}}.
La creazione di un model in Laravel può generare contestualmente anche altre classi, come le migrazioni per la tabella associata, il controller, le rotte resource, fino addirittura alle classi Faker/Seeder per riempire di dati di test la tabella.
$ php artisan make:model Role -mcrf
Questo comando oltre a creare il model creerà anche la migrazione (m), il controller (c), le resources (r) o azioni CRUD del controller. Inoltre creerà le classi Faker e Seeder (f) che consentono di specificare il tipo di dati di test con cui riempire le tabelle (Faker) e istruire il Seeder con il numero di record da creare.
Tutto in un solo comando!
Poi però occorre personalizzare ogni classe creata in base a cosa vogliamo fare.
Ho già creato il model, voglio creare le resources
Si possono dare i comandi anche in modo asincrono. In questo esempio:
François Zaninotto è l’autore di questo package veramente formidabile. Egli ha deciso di abbandonare il progetto poiché “has a design problem”. Un difetto di progettazione iniziale ha fatto sì che le varie localizzazioni non potessero sessere scaricate separatamente dal pacchetto ma si dovesse scaricar tutto insieme.
Nel tempo le dimensioni del package con tutte le localizzazioni ha raggiunto dimensioni ragguardevoli e il numero di download è aumentato esponenzialmente (a fine 2020 era a 125 M download) e Zaninotto si è posto il problema dell’impatto ecologico in termini carbon footprint.
Be’ il suo calcolo lo ha impressionato, ha preferito chiudere e abbandonare il progetto, che ora è solo readonly.
Aggiungiamo Auth + Vue.js, il modo più diretto di aggiungere al progetto Laravel una protezione con password. Il plugin Auth è uno scaffold di autenticazione che utilizza Vue.js.
Installazione di Vue/Auth
composer require laravel/ui:^2.4
php artisan ui vue --auth
npm install
npm run dev
php artisan migrate
Il comando ui installa le componenti Vue.js e lo scaffolding necessario per le maschere di autenticazione, recupero password, eccetera e le funzionalità javascript delle interfacce.
npm
Il Node.js Packet Manager va invocato perché il prodotto Auth ha parecchie component javascript da installare.
Infine, il comando di migrazione serve per le tabelle dei recuperi password e dei token (“Ricordami questo accesso”).
Al termine dell’installazione saranno già state impostate tutte le rotte per Auth:
laravel route list con Auth
Vengono già predisposti i comandi di registrazione, recuper passord, login, logout. Però i conenuti rimangono ad accesso libero quidni va gestito cosa vogliamo proteggere con la login e cosa rimane publico.
Per fare questo occorre agire sul controller.
Per prtoteggere l’intera applicazione occorre fare in modo che ogni volta che si invoca la classe controller del modello che si vuole proteggere: avvenga l’interposizone del mìddleware Auth. Per esempio si può deìcidere tabella per tabella se si vuole la protezione oppure no:
class CompanyController extends Controller
{
public function __construct()
{
$this->middleware('auth');
}
in questo caso il CRUD della tabella Company sarà intercettato dal middleware Auth e se si tenta di accedere ad una delle rotte, si presenterà la maschera di login:
Il nome dell’applicazione può essere visualizzato nelle views di Laravel e può essere definito in almeno tre modi
file .env
Il file di configurazione delle variabil di ambiente è situato nella radice dell’albero dell’applicazione e si chiama .env.
Al suo interno si trova una variabile che possiamo personalizzare:
APP_NAME=MyBeautifulAppName
Poi, all’interno della view, ci riferiremo a questa variabile nel modo seguente
{{env('APP_NAME')}}
Tuttavia il file .env non viene normalmente sottoposto a versione perché è caratteristico del singolo deploy su ogni server. Quindi tendo a non utilizzare questa variabile.
file config/app.php
Questo file contiene una variabile predefinita:
'name' => env('APP_NAME', 'MyBeautifulAppName'),
Qui in realtà fa un’override del file .env, infatti utilizza la stessa variabile env, però è a runtime, cioè acquisisco il valore di default e lo metto in un’altra variabile name, eventualmente modificandolo. Per accedere al valore della variabile name in una view si scrive:
{{ config('app.name', 'Default name') }}
il secondo argomento essendo il default.
Condivisione di una variabile tra tutte le view
Il terzo metodo è il più elaborato ma consente una maggiore flessibilità: si definisce una variabile dal nome arbitrario nel file
<APP>/app/Providers/AppServiceProvider.php
e al suo interno, nel metodo boot(), si invoca il metodo statico View::share():
/**
* Bootstrap any application services.
*
* @return void
*/
public function boot()
{
View::share('appTitle', "MyBeautifulAppName - powered by Laravel");
}
La variabile è poi disponibile nelle view: {{$appTitle}}.
Se questi contenuti vi risultano utili, condivideteli. Ciao 🙂
BabelEdit è un programma che ci aiuta a localizzare l’applicazione. Si devono infatti personalizzare i file di localizzazione della lingua che già Laravel mette a disposizione nella cartella resources/lang. Fondamentalmente l’applicazione fa uso di etichette che poi recuperano per associazione il valore esteso del testo da visualizzare.
Per aiutare in questo tipo di attività, soprattuto se il lavoro di traduzione viene svolto da non programmatori, si può utilizzare questo software. Non sto facendo endorsement, voglio solo riportare una possibile soluzione cooperativa.
Download e installazione
Una volta installato, (al solito io uso Linux) lanciarlo con
$ BabelEdit
Dashboard di BabelEdit
Utilizzo di BabelEdit
Ovviamente prima occorre dare l’OK per l’accettazione dei termini di licenza e per l’attivazione della Trial di 7 giorni.
Si carica il file delle etichette originarie (che sono quelle del plugin Auth):
Seleziona la sorgente dei dati
Per il nostro progetto, i file di dizionario sono PHP. Si apre così la maschera per caricare i file da tradurre:
Configurazione dei linguaggi
Si possono aggiungere i file origine e destinazione
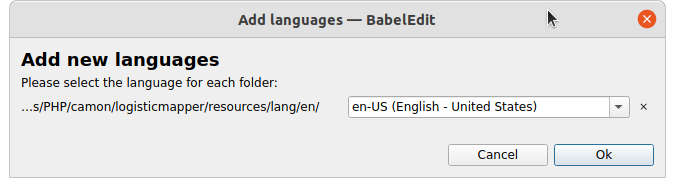
BabelEdit aggiungere le lingue
Si associa il file alla lingua
Aggiunta nuova lingua
Si ripetono questi passaggi per tutte le lingue che vogliamo trattare.
Cliccando su “Primary Language” selezioniamo qual è la lingua di riferimento da cui derivieremo tutte le traduzioni:
BabelEdit selezione lingua primaria
si apre la maschera di selezione del servizio
Babel configurazione del servizio di traduzione online
Apriamo un messaggio, vengono visualizzate le etichette così come sono state configurate nei due file di lingua. Cliccando in basso a destra lo scudo con stellina
Selezione del servizio di traduzione online
si può vedere la traduzione proposta dal servizio online (ad esempio Google)
Babel traduzione automatica
cliccando sulla proposta, il valore dell’etichetta viene modificato con quello proposto da Google. In assenza del servizio si può tradurre in autonomia.
CRUD è l’acronimo per Create, Read, Update, Delete che sono le quattro operazioni fondamentali sui dati.
Laravel non ha molta automazione da questo punto di vista, dobbiamo costruirci le form HTML per creare e modificare i file, così come le viste per visualizzare tutti i dati oppure solo un record e alla fine la funzionalità di cancellazione.
Però ha un sistema di creazione di pagine di Blade che ci permettono il riutilizzo intelligente di molte parti di layout.
In questo aritcolo ci muoveremo su tutti e tre i domini del paradigma MVC.
CRUD 1: creiamo il template
Come prima operazione creiamo un template che riutilizzeremo in tutta l’applicazione. Lo creiamo in resources/views/layouts/app.blade,php:
La direttiva @yield prenderà il contenuto della sezione content della vista chiamata e la metterà qui. Quindi se il controller chiama la view ‘edit.blade’ il suo contenuto verrà calcolato (cioè verranno messi dentro i dati) e poi prenderà posto dentro il tag “container”. È analoga ad una direttiva include. Quindi tutte le view avranno il titolo Logistic Mapper in questo caso.
CRUD 2: rassegna dei metodi da implementare
Create
Cominciamo con la creazione di nuovi records, operazione che nel dominio dei database è una insert.
Attenzione: questa azione consiste nella visualizzazione della form vuota (non stiamo ancora creando alcun record). Il verbo HTTP a cui viene associata è GET e il nome della rotta è company.create. Ciò significa che la pagina web che dobbiamo progettare starà sotto /resources/view/company e si chiamerà create.blade.phpe verrà invocata dal metodo create del controller CompanyController.
La prima direttiva (@extends) indica in quale template deve essere inclusa questa pagina web, ed è layouts/app.blade.php (blade.php è un suffisso standard, il formato in dot notation della vista è layouts.app).
La seconda dichiarazione @section è la sezione content, che è il frammento che dev’essere incluso nel template layouts.app.
Segue la form. Attenzione!
la action dev’essere semplicemente /company: la risorsa da invocare davvero non è decisa qui ma è decisa a livello della tabella di routing, in questo caso è il metodo CompanyController@create
il method dev’essere conguente con il metodo espresso nella tabella di routing , quindi GET.
c’è un’ulteriore direttiva @csrf che serve per evitare che il metodo venga chiamato via HTTP da un’altro sito. Ci siamo già occupati di questo attacco in questo post.
Come si vede ho una serie di campi di tipo testo e una combobox che devo popolare in anticipo. Il controller deve fare tutte queste cose:
public function create()
{
$company_types= CompanyType::all();
return view('company.create', compact('company_types'));
}
La query su CompanyType serve appunto per procurarsi la combo box. Per questo si usa il metodo all() del model. Il risultato questo:
Create company
Store
DOpo aver compilato il modulo, occorre salvare il dato. L’operazion Eloquent equivalente all’insert come detto è store. Quindi per vedere come dobbiamo comprtarci dobbiamo studiarci la riga corrispondente della tabella di routing:
| POST | company | company.store | App\Http\Controllers\CompanyController@store |
In questo caso il form HTML dovrà utlizzare il metodo POST che in questo caso viene preso davvero in consderazionie e non viene riscritto da alcuna direttiva. Inoltre il metodo di controller sarà CompanyController@store . Anche se è prevista la view company.store non si verrà usata perché verrà fatto un redirecto verso l’elenco di tutte le Company (company.index) in caso di successo.
Quindi il metodo store è il seguente:
public function store(Request $request)
{
$company = new Company($request->all());
$company->save();
return redirect(route('company.index'));
}
È semplicissimo: si crea un nuovo oggetto della classe Company inizializzandolo con i valori dell’array $request->all().
Attenzione! se tentiamo di passare come argomento semplcemente $request, Laravel s’incazza perché $request è un oggetto, mentre il costruttore del model vuole un array.
Il metodo save() di Eloquent si trasforma in una insert della tabella companies.
Finalmente, viene inviata al browser una direttiva di redirect verso la view company.index.
Edit
Il terzo metodo ci consente di editare i dati per poi eseguire un update. Quindi questo metodo serve per visualizzare la form di modifica e non per modificare i dati, operazioe che sarò in carico al metodo update.
Al solito ci facciamo guidare dalla tabella di routing
Qui l’URI di accesso alla pagiba di edit era già stato generato nella pagina index dalla funzione
route('company.edit', $v->id)
l’URI generato è proprio del tipo company/{company}/edit come indicato dalla tabella di routing, dove il segnaposto {company} è sostituito dal valore numerico della chiave primaria della company. Il verbo HTTP utilizzato anche in quetso è GET (Apache deve servirci una pagina web).
Il metodo edit del CompanyController deve caricare dal database i dati da inserire nella form di modifica:
il valore $company_type_id che ci serve solo per posizionare correttamente la combo box; non sarebbe necessaria ma la scrittura della view ne risulta così un po’ più chiara.
dobbiamo utillizzare il verbo HTTP PUT e impostare la action su company/{company}.
Il metodo di Controller update sarà
public function update(Request $request, $id)
{
$company = Company::find($id);
$company->update($request->all());
return redirect(route('company.index'));
}
Viene creato l’oggetto $company da una query sul model per ID, viene passato al metodo update l’array $request->all() e alla fine viene rediretto il browser sull’indice.
Perché per operazioni diverse siamo verbi HTTP diversi?
La RFC-2616 (Hyper Text Transfer Protocol HTTP/1.1) stabilisce che il metodo PUT va usato per sostituire una risorsa esistente nel server. Ci si ricordi che all’inizio HTTP era un protocollo che si usava solo per lavorare coi file.
Il metodo POST invece va usato per trasferire dati (nuovi) dal client al srever, quindi il risultato è la creazione di una nuova risorsa.
Per questo il metodo PUT è idempotente: se applicato più volte, produce lo stesso risultato.
Il metodo POST invece non lo è, ogni volta che lo si applica vengono create nuove risorse; questo è proprio il comportamento delle operazioni database di Update (PUT) e Insert (Post), per cui questo è il senso di utilizzare i verbi HTTP in modo appropriato per le varie operazioni.
Questa distinzione va fatta anche quando si progetta l’interfaccia API di un server.
Utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Lo facciamo per migliorare l'esperienza di navigazione e per mostrare annunci personalizzati. Il consenso a queste tecnologie ci consentirà di elaborare dati quali il comportamento di navigazione o gli ID univoci su questo sito. Il mancato consenso o la revoca del consenso possono influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.

























Commenti recenti