

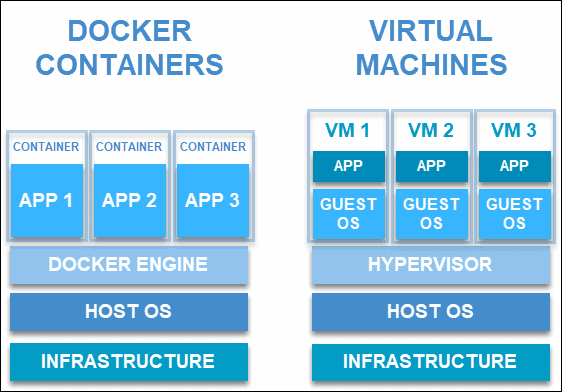
Se non hai ancora letto questo articolo, ti consiglio vivamente di farlo perché la sua comprensione precede lo studio del presente articolo.
Introduzione
Un Dockerfile è uno script con le istruzioni su come creare un’immagine Docker. Queste istruzioni sono, infatti, un gruppo di comandi eseguiti automaticamente in ambiente Docker per costruire un’immagine Docker specifica.
In questo tutorial, scopri come creare un’immagine Docker con un Dockerfile.
Salto la parte relativa all’installazione di Docker già trattata altrove nel blog.
Creare un Dockerfile
La prima cosa che devi fare è creare una directory in cui puoi archiviare tutte le immagini Docker che crei.
Ad esempio, creeremo una directory denominata ~/docker/images , e un file Dockerfile al suo interno con il comando:
$ mkdir -p ~/docker/images && cd ~/docker/images && touch Dockerfile
Ora occorre editare il Dockerfile e questo apre un grande capitolo sulla sintassi dei Dockerfile: i Dockerfile sono degli script che servono ad allestire l’immagine (che programmi usare? ad esempio Python, PostgreSQL… che librerie/dipendenze mi servono? ad ese GDAL, … che software devo fare girare? ad esempio quello che ho sviluppato io che dovrà trovarsi nella cartella /app/ del container). Un semplice esempio tratto dal blog di Sofija è questo che dà un primo esempio di template che delinea alcune funzionalità (mutatis mutandis):
FROM ubuntu # <--- 1 MAINTAINER Marco Barbato <marco@betaingegneria.it> # <--- 2 RUN apt-get update # <--- 3 CMD ["echo", "Ciao, Mondo!"] # <--- 4
- FROM: Definisce le fondamenta dell’immagine che stai creando. Puoi iniziare da un’immagine padre (come nell’esempio sopra) o da un’immagine base.
Quando si utilizza un’immagine padre, si utilizza un’immagine esistente su cui ne basi una nuova.
Usare un’immagine base significa invece che stai partendo da zero (che è esattamente come la definiresti: FROM scratch). - MANTAINER: Specifica l’autore dell’immagine. Qui puoi digitare il tuo nome e/o cognome (o anche aggiungere un indirizzo email). Puoi anche utilizzare l’istruzione LABEL per aggiungere metadati a un’immagine.
- RUN: istruzioni per eseguire un comando mentre si costruisce un’immagine in un livello sopra di essa. In questo esempio, il sistema cerca gli aggiornamenti del repository una volta iniziata la creazione dell’immagine Docker. Puoi avere più di un’istruzione RUN in un Dockerfile.
- CMD: Può esserci solo un’istruzione CMD all’interno di un Dockerfile. Il suo scopo è fornire i valori predefiniti per un container in esecuzione. Con esso, imposti un comando predefinito. Il sistema lo eseguirà se si esegue un container senza specificare un comando.
Creare una immagine da un Dockerfile
La sintassi generale per costruire (build) una immagine a partire da un file Dockerfile è questa:
$ docker build [OPTIONS] PATH | URL | -
Pertanto fondamentalmente dovrai lanciare questo comando
$ docker build /path/to/dockerfile
Se sei già nella direcotry del Dockerfile, semplicemente scriverai:
$ docker build .
Siccome ogni immagine che viene creata viene battezzata con uno stringone esadecimale, che è poco mnemonico, si può associare un tag all’immagine per aiutarsi ad organizzare le immagini:
$ docker build -t my_image . Sending build context to Docker daemon 2.048kB Step 1/4 : FROM ubuntu ---> 27941809078c Step 2/4 : MAINTAINER marco Barbato <marco@betaingegneria.it> ---> Running in 7cd4f42b5e84 Removing intermediate container 7cd4f42b5e84 ---> d0377afa0d1b Step 3/4 : RUN apt-get update ---> Running in b223682b3e0f Get:1 http://security.ubuntu.com/ubuntu jammy-security InRelease [110 kB] Get:2 http://archive.ubuntu.com/ubuntu jammy InRelease [270 kB] Get:3 http://security.ubuntu.com/ubuntu jammy-security/restricted amd64 Packages [313 kB] Get:4 http://security.ubuntu.com/ubuntu jammy-security/main amd64 Packages [332 kB] Get:5 http://security.ubuntu.com/ubuntu jammy-security/multiverse amd64 Packages [4644 B] Get:6 http://security.ubuntu.com/ubuntu jammy-security/universe amd64 Packages [131 kB] Get:7 http://archive.ubuntu.com/ubuntu jammy-updates InRelease [114 kB] Get:8 http://archive.ubuntu.com/ubuntu jammy-backports InRelease [99.8 kB] Get:9 http://archive.ubuntu.com/ubuntu jammy/restricted amd64 Packages [164 kB] Get:10 http://archive.ubuntu.com/ubuntu jammy/universe amd64 Packages [17.5 MB] Get:11 http://archive.ubuntu.com/ubuntu jammy/multiverse amd64 Packages [266 kB] Get:12 http://archive.ubuntu.com/ubuntu jammy/main amd64 Packages [1792 kB] Get:13 http://archive.ubuntu.com/ubuntu jammy-updates/universe amd64 Packages [258 kB] Get:14 http://archive.ubuntu.com/ubuntu jammy-updates/multiverse amd64 Packages [7791 B] Get:15 http://archive.ubuntu.com/ubuntu jammy-updates/restricted amd64 Packages [354 kB] Get:16 http://archive.ubuntu.com/ubuntu jammy-updates/main amd64 Packages [631 kB] Get:17 http://archive.ubuntu.com/ubuntu jammy-backports/universe amd64 Packages [5814 B] Fetched 22.3 MB in 6s (4013 kB/s) Reading package lists... Removing intermediate container b223682b3e0f ---> 719d25fccd26 Step 4/4 : CMD ["echo", "Ciao, Mondo!"] ---> Running in aa4e9ccb74e0 Removing intermediate container aa4e9ccb74e0 ---> ade2f7ecc592 Successfully built ade2f7ecc592 Successfully tagged my_image:latest
Ora si possono vedere tutte le immagini create con il comando docker image ls (oppure docker images):
$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> e7a5d4ae5d10 4 days ago 1.44GB sent_crunch latest 6dcb0bbb67c7 4 days ago 1.27GB
Creare un container da una immagine
Il passo successivo è avviare un nuovo contenitore Docker in base all’immagine che hai creato nei passaggi precedenti. Chiameremo il contenitore “test” e lo creeremo con il comando:
$ sudo docker run --name test my_image Ciao, Mondo!
Il messaggio Ciao, Mondo! dovrebbe apparire come output nella shell, come effetto dell’ultimo comando del Dockerfile:
CMD ["echo", "Ciao, Mondo!"]
Conclusione
L’utilizzo di Dockerfile è il modo più semplice e veloce per creare un’immagine Docker. Automatizza il processo passando attraverso lo script con tutti i comandi per assemblare un’immagine.
Quando crei un’immagine Docker, assicurati anche di mantenere le dimensioni dell’immagine Docker contenute. Evitare immagini di grandi dimensioni velocizza la creazione e la distribuzione dei container. Pertanto, è fondamentale ridurre al minimo le dimensioni dell’immagine.
Riferimenti
- Creare immagini Docker con Dockerfile, di Sofija Simic su Phoenixnap.com
- Terminologia di base Docker (betaingegneria.it)






Commenti recenti