Quando si esegue uno script Bash ci sono due modalità principali da impiegare, che hanno conseguenze diverse sull’ambiente della shell. 1. Esecuzione diretta (./script.sh) Quindi può solo leggere le variabili di ambiente della shell madre …
Preso dalla curiosità di ripassare l’assembly (tanti anni fa studiai il Motorola 68000) ho scritto una guida ordinata che illustra passo per passo come scrivere un semplice programma Assembly in real-mode (16 bit), confezionarlo come …
GeoGebra è un software open‑source per la didattica della matematica e della geometria dinamica. Quello che intendiamo qui con “geometria dinamica” è un approccio all’insegnamento e alla sperimentazione della geometria in cui le costruzioni non …
Negli ambienti desktop basati su GNOME, come Ubuntu, è possibile impostare uno sfondo che cambia automaticamente nel tempo, come una presentazione. Quello che molti non sanno è che GNOME supporta nativamente gli slideshow tramite file …
Negli ultimi giorni ho condotto una piccola sperimentazione con Whisper, il modello di riconoscimento vocale automatico (ASR) open source sviluppato da OpenAI. L’obiettivo era duplice: Cos’è Whisper Whisper è un sistema di riconoscimento vocale automatico …
Quando viene fatta una nuova scoperta sulla fisica delle particelle, potresti aver sentito usare il termine “sigma”. Cosa significa? Perché è così importante parlare di sigma quando si avanza una richiesta per la scoperta di una nuova particella? E perché “Five Sigma” in particolare è così importante?
Perché la fisica delle particelle si basa sulla statistica?
Le particelle prodotte nelle collisioni nel Large Hadron Collider (LHC) sono minuscole e hanno una vita estremamente breve. Poiché decadono quasi immediatamente in altre particelle, è impossibile per i fisici “vederle” direttamente. Invece, esaminano le proprietà delle particelle finali, come la loro carica, massa, spin e momento. SI comportano come investigatori: i prodotti finali forniscono indizi sulle possibili trasformazioni che le particelle hanno subito durante il loro decadimento. Le probabilità di questi cosiddetti “canali di decadimento” sono previste dalla teoria.
Nell’LHC, milioni di collisioni di particelle al secondo vengono tracciate dai rilevatori e filtrate attraverso sistemi di trigger per identificare i decadimenti di particelle rare. Gli scienziati quindi analizzano i dati filtrati per cercare anomalie, che possono indicare nuova fisica.
Come in ogni esperimento, c’è sempre la possibilità di errore. Il rumore di fondo può causare fluttuazioni naturali nei dati con conseguenti errori statistici. Esiste anche il rischio di errori se non ci sono dati sufficienti o di errori sistematici causati da apparecchiature difettose o piccoli errori nei calcoli. Gli scienziati cercano modi per ridurre l’impatto di questi errori per garantire che le affermazioni che fanno siano il più accurate possibile.
Qual è la significatività statistica?
Immagina di lanciare un dado standard. C’è una probabilità su sei di ottenere un numero. Ora immagina di lanciare due dadi: la probabilità di ottenere un certo numero totale varia: c’è solo un modo per ottenere un due e sei modi diversi per ottenere un sette. Se lanciassi due dadi molte, molte volte e registrassi i risultati, la forma del grafico seguirebbe una curva a campana nota come distribuzione normale.
La distribuzione normale ha alcune proprietà interessanti. È simmetrica, il suo picco è chiamato media e la dispersione dei dati viene misurata utilizzando la deviazione standard. Per i dati che seguono una distribuzione normale, la probabilità che un punto dati si trovi all’interno di una distanza dal valore medio pari a una deviazione standard è del 68%, entro due deviaizioni standard è del 95%, entro tre è ancora più alta.
La deviazione standard è rappresentata dalla lettera greca σ, o sigma. Misurata in base al numero di deviazioni standard dalla media, la significatività statistica è la distanza di un determinato punto dati dal suo valore atteso.
Per i dati che seguono una distribuzione normale, la probabilità che un punto dati si trovi all’interno di una deviazione standard o di un sigma (σ) del valore medio è del 68%, entro due σ è del 95%, entro tre σ è ancora più alta (Immagine: MW Toews )
Cosa c’entra questo con la fisica?
LHC 5 sigma significance
Quando gli scienziati registrano i dati dell’LHC, è naturale che si verifichino piccole irregolarità e fluttuazioni statistiche, ma queste sono generalmente vicine al valore atteso. C’è un’indicazione di un nuovo risultato quando c’è un’anomalia più grande. A che punto questa anomalia può essere classificata come un fenomeno nuovo? Gli scienziati usano la statistica per scoprirlo.
Immagina di nuovo la metafora dei dadi. Solo che questa volta stai lanciando un dado, ma non sai se è truccato. Lo lanci una volta e ottieni un tre. Non c’è nulla di particolarmente significativo in questo – c’era una possibilità su sei del tuo risultato – hai bisogno di più dati per determinare se è ponderato. Lo lanci due, tre o anche di più e ogni volta esce un tre. A che punto puoi confermare che è truccato?
Non esiste una regola particolare per questo, ma dopo circa otto volte in cui hai ottenuto lo stesso numero, sarai abbastanza certo che lo sia. La probabilità che ciò accada per caso è solo (1/6) 8 = 0,00006%.
Allo stesso modo, è così che i fisici determinano se un’anomalia è effettivamente un risultato. Con un numero sempre maggiore di dati, la probabilità di una fluttuazione statistica in un punto specifico diventa sempre più piccola. Nel caso del bosone di Higgs , i fisici avevano bisogno di dati sufficienti affinché la significatività statistica superasse la soglia di cinque sigma. Solo allora avrebbero potuto annunciare la scoperta di “una particella simile a Higgs”.
Cosa significa quando i fisici affermano che i dati hanno un significato statistico di cinque sigma?
Un risultato che ha una significatività statistica di cinque sigma indica la probabilità quasi certa che un aumento nei dati sia causato da un nuovo fenomeno, piuttosto che da una fluttuazione statistica. Gli scienziati lo calcolano misurando il segnale rispetto alle fluttuazioni previste nel rumore di fondo su tutta la gamma. Per alcuni risultati, le cui anomalie potrebbero trovarsi in entrambe le direzioni al di sopra o al di sotto del valore atteso, una significatività di cinque sigma è la probabilità dello 0,00006% che i dati siano fluttuanti. Per altri risultati, come la scoperta del bosone di Higgs, una significatività di cinque sigma è la probabilità dello 0,00003% di una fluttuazione statistica, poiché gli scienziati cercano dati che superano il valore di cinque sigma su metà del grafico della distribuzione normale.
Perché il cinque sigma è particolarmente importante per la fisica delle particelle?
Nella maggior parte delle aree scientifiche che utilizzano l’analisi statistica, la soglia di cinque sigma sembra eccessiva. In uno studio sulla popolazione, come i sondaggi su come voteranno le persone, di solito sarebbe sufficiente un risultato con una significatività statistica di tre sigma. Tuttavia, quando si parla della struttura stessa dell’Universo, gli scienziati mirano ad essere il più precisi possibile. I risultati della natura fondamentale della materia sono di grande impatto e hanno ripercussioni significative se sono sbagliati.
In passato, i fisici hanno notato risultati che potevano indicare nuove scoperte, con i dati che avevano solo una significatività statistica da tre a quattro sigma. Questi sono stati spesso smentiti man mano che venivano raccolti più dati.
Se si verifica un errore sistematico, ad esempio un errore di calcolo, l’elevato significato iniziale di cinque sigma può significare che i risultati non sono completamente nulli. Tuttavia, ciò significa che il risultato non sia definitivo e non possa essere utilizzato per rivendicare una nuova scoperta.
Five Sigma è considerato il “gold standard” nella fisica delle particelle perché garantisce una probabilità estremamente bassa che un’affermazione sia falsa.
Ma non tutti e cinque i sigma sono uguali…
Cinque sigma è generalmente il valore accettato per la significatività statistica per la ricerca di nuove particelle all’interno del Modello Standard – quelle particelle che sono previste dalla teoria e si trovano nella nostra attuale comprensione della natura. La significatività cinque sigma è accettata anche quando si ricercano proprietà specifiche del comportamento delle particelle, poiché ci sono meno possibilità di trovare fluttuazioni altrove nell’intervallo.
Se cinque sigma siano una significatività statistica sufficiente può essere determinato confrontando la probabilità della nuova ipotesi con la possibilità che si tratti di una fluttuazione statistica, tenendo conto della teoria.
Per la fisica oltre il Modello Standard, o per i dati che contraddicono la fisica generalmente accettata, è richiesto un valore di significatività statistica molto più elevato – abbastanza efficace da “confutare” la fisica precedente. Nel suo articolo “ Il significato di cinque sigma ”, il fisico Louis Lyons suggerisce che i risultati per fenomeni più improbabili dovrebbero avere un significato statistico più elevato, come il sette sigma per il rilevamento delle onde gravitazionali o la scoperta dei pentaquark.
In questo articolo, Lyons ritiene anche che la significatività statistica di cinque sigma sia sufficiente per la scoperta del bosone di Higgs. Questo perché la teoria del bosone di Higgs era stata prevista, testata matematicamente e generalmente accettata dalla comunità dei fisici delle particelle ben prima che LHC potesse generare le condizioni per poterlo osservare. Ma una volta raggiunto questo obiettivo, era ancora necessaria un’elevata significatività statistica per determinare se il segnale rilevato fosse effettivamente una scoperta.
Una significatività statistica di cinque sigma è rigorosa, ma in realtà è minima. Un valore più elevato per la significatività statistica conferma che i dati sono più affidabili. Tuttavia, ottenere risultati con significatività statistica di sei, sette o addirittura otto sigma richiede molti più dati, molto più tempo e molta più energia. In altre parole, una probabilità pari al massimo allo 0,00006% che un nuovo fenomeno non sia un colpo di fortuna statistico è abbastanza buona.
Mi sono trovato a dover studiare meglio l’argomento del routing IP in seguito a problemi di configurazione nel nuovo pc della VPN di un cliente.
routing IP
Una delle cose che mi sono ritrovato a fare è stampare la tabella di routing dalla quale posso vedere gli indirizzi raggiungibili dal mio host (ho un computer nuovo e l’ho chiamato poleni in onore di Giovanni Poleni, fisico veneziano, 1683-1761):
Routing IP: stampa della tabella di routing
Questo articolo estende e chiarisce alcune informazioni che ho già trattato nell’area del blog dedicata al Networking.
Questo argomento mi ricorda Ricerca Operativa, in cui ho studiato la teoria dei grafi che qui entra prepotentemente in gioco.
Cos’è il routing IP: panoramica
Routing IP è un termine generico per l’insieme di protocolli che determinano il percorso seguito dai dati per viaggiare su più reti dalla sorgente alla destinazione. I dati vengono instradati dall’origine alla destinazione attraverso una serie di router e su più reti.
Il compito del router è collegare due reti.
I protocolli di routing IP consentono ai router di creare una tabella di inoltro che correla le destinazioni finali con gli indirizzi dell’hop successivo.
Questi protocolli includono:
BGP ( Border Gateway Protocol)
IS-IS (Intermediate System – Intermediate System)
OSPF (Open Shortest path First)
RIP (Routing Information Protocol)
che verranno descritti più avanti.
Quando un pacchetto IP deve essere inoltrato ad un’altra rete, un router utilizza la propria tabella di inoltro per determinare l’hop successivo per la destinazione del pacchetto (in base all’indirizzo IP di destinazione che si trova nell’intestazione del pacchetto IP) e inoltra il pacchetto in modo appropriato. Il router successivo ripete quindi questo processo utilizzando la propria tabella di inoltro e così via finché il pacchetto non raggiunge la sua destinazione. In ogni fase, l’indirizzo IP nell’intestazione del pacchetto è un’informazione sufficiente per determinare l’hop successivo; non sono necessarie intestazioni di protocollo aggiuntive.
Dunque, in qualche modo, ogni router cerca di “indovinare” la prossima rete che più probabilmente porterà a destinazione il pacchetto IP.
Quindi è chiaro che il nodo della questione è: come funziona un router? dal suo funzionamento infatti dipende il successo della consegna di un pacchetto TCP/IP alla destinazione.
Panoramica sul funzionamento di un algoritmo di routing
Un algoritmo di routing è progettato per determinare il percorso ottimale o più appropriato attraverso una rete di comunicazione da una sorgente a una destinazione. Questo processo è fondamentale nelle reti di computer e nei sistemi di comunicazione per garantire che i dati vengano instradati in modo efficiente e affidabile da un punto all’altro. Ecco una panoramica generale di come funziona un algoritmo di routing:
Rilevamento della topologia di rete: l’algoritmo deve avere informazioni sulla topologia della rete, cioè la configurazione dei dispositivi di rete e i collegamenti tra di essi.
Scelta del percorso: l’algoritmo valuta i vari percorsi possibili dalla sorgente alla destinazione sulla base di criteri specifici, come la larghezza di banda disponibile, la congestione della rete, la qualità del collegamento e altre metriche.
Costruzione della tabella di routing: l’algoritmo utilizza le informazioni raccolte per costruire una tabella di routing, che associa destinazioni specifiche ai percorsi ottimali o alle interfacce dei dispositivi di rete successivi.
Aggiornamento della tabella di routing: la tabella di routing viene continuamente aggiornata per riflettere eventuali cambiamenti nella topologia di rete o nelle condizioni operative. Ciò può avvenire automaticamente o essere gestito manualmente.
Instradamento dei pacchetti: quando un pacchetto dati viene inviato dalla sorgente, l’algoritmo di routing utilizza la tabella di routing per determinare il percorso ottimale. Il pacchetto viene quindi inoltrato da un dispositivo di rete all’altro lungo il percorso stabilito fino a raggiungere la destinazione.
Ci sono diversi algoritmi di routing, ognuno con i propri vantaggi e svantaggi. Alcuni esempi includono l’algoritmo di routing a vettore delle distanze (distance vector), l’algoritmo di stato del collegamento (link state), e BGP (Border Gateway Protocol) nell’ambito di Internet (vedi più avanti).
L’efficienza di un algoritmo di routing dipende dalla sua capacità di adattarsi a cambiamenti nella rete, di gestire la congestione e di ottimizzare le prestazioni complessive del sistema di comunicazione.
Una trattazione sistematica di questo argomento utilizza l’astrazione dei Sistemi Autonomi.
Sistemi autonomi
Internet è una rete di reti e i sistemi autonomi sono le grandi reti che compongono Internet. Più specificamente, un sistema autonomo (AS) è una rete di grandi dimensioni o un gruppo di reti che dispone di una politica di routing unificata. Ogni computer o dispositivo che si connette a Internet è connesso in prima istanza a un AS.
Proviamo a immaginare un AS come l’ufficio postale di una città o come gli hub di un’azienda di trasporti. La posta va da un ufficio postale all’altro finché non raggiunge la città giusta, e l’ufficio postale di quella città consegnerà poi la posta all’interno di quella città. Allo stesso modo, i pacchetti di dati attraversano Internet saltando da un AS all’altro fino a raggiungere l’AS che contiene l’indirizzo IP di destinazione: a questo punto i router all’interno di quest’ultimo AS invieranno il pacchetto all’indirizzo IP di destinazione finale.
Routing IP: Internet come rete di Sistemi Autonomi
Ogni AS controlla un insieme specifico di indirizzi IP, proprio come l’ufficio postale di ogni città è responsabile della consegna della posta a tutti gli indirizzi all’interno di quella città. L’intervallo di indirizzi IP su cui un determinato AS ha il controllo è chiamato spazio degli indirizzi IP.
I sistemi autonomi sono dunque stati introdotti per regolamentare le organizzazioni di rete come i fornitori di servizi Internet (ISP), gli istituti scolastici e le agenzie governative.
Da un punto di vista pratico, un AS è un insieme di prefissi IP assegnato a un organizzazione (entità) che sono instradabili su Internet appartenenti alla rete o all’insieme di reti che sono tutte gestite, controllate e supervisionate dall’entità o organizzazione.
Un AS utilizza un’unica politica di routing controllata dall’organizzazione. All’AS viene assegnato un numero identificativo di 16 cifre univoco a livello globale, noto come numero di sistema autonomo o ASN, dall’Internet Assigned Numbers Authority (IANA).
I sistemi autonomi numerati da 1 a 64511 sono disponibili da IANA per l’uso globale. La serie da 64512 a 65535 è riservata ad usi privati e riservati.
Topologia dei sistemi autonomi [Cloudflare]
Per esempio l’AS a cui è connessa la rete da cui sto scrivendo questo articolo è AS3269 che è Telecom Italia S.p.A. Per trovare qual è il vostro è sufficiente individuare con quale indirizzo IP la vostra rete è connessa a Internet (lo sa il vostro router, se avete accesso alla consolle, oppure potete usare un servizio web come whatismyip.com), poi interrogare il database whois con l’argomento l’IP che avete trovato:
whois for IP routing
L’AS3269 a cui questa rete è connessa è quella di Telecom Italia. Il protocollo whois restituisce informazioni diverse a seconda che lo si interroghi con un indirizzo IP o con un nome di dominio. L’informazione sull’ASN viene esposta solo interrogando con l’indirizzo IP.
Se poi l’AS è di transito (vedi poco oltre, Telecom Italia è un caso di questi), il comando whois espone una pletora di dettagli (che sono pubblici) come tutte le direttive per l’importazione e l’esportazione delle tabelle di routing da e verso gli altri AS.
Internet, ai fini del routing, è dunque una collezione di Sistemi Autonomi (AS).
Fisicamente, un AS è un gruppo di router che sono sotto il controllo di un’unica amministrazione e scambiano informazioni di routing utilizzando un protocollo di routing comune. Ad esempio, una intranet aziendale o una rete ISP possono solitamente essere considerate come un singolo AS.
Un AS può essere classificato come uno dei tre tipi seguenti.
Un Sistema Autonomo Stub ha una singola connessione con un altro AS. Tutti i dati inviati o ricevuti da una destinazione esterna all’AS devono viaggiare su tale connessione. Una piccola rete universitaria è un esempio di AS stub.
Un Sistema Autonomo di transito ha più connessioni a uno o più AS, il che consente ai dati che non sono destinati a un nodo all’interno di quell’AS di attraversarlo. Una rete ISP è un esempio di AS di transito.
Un Sistema Autonomo Multihomed ha anche più collegamenti con uno o più AS, ma non consente che i dati ricevuti su uno di questi collegamenti vengano nuovamente inoltrati dall’AS. In altre parole, non fornisce un servizio di transito ad altri AS. Un AS Multihomed è simile a un AS Stub, tranne per il fatto che i punti di ingresso e di uscita per i dati che viaggiano da o verso l’AS possono essere scelti da una serie di connessioni, a seconda di quale connessione offre il percorso più breve verso la destinazione finale. Una rete aziendale di grandi dimensioni sarebbe normalmente un AS multihomed.
Il calcolo delle rotte: Interior ed Exterior Protocols
Il termine “Interior Gateway Protocol” (IGP) si riferisce a un protocollo di routing utilizzato all’interno di una rete autonoma per determinare il percorso ottimale per la trasmissione dei dati tra i suoi nodi. Gli IGPs sono progettati per gestire il routing all’interno di una singola rete e sono complementari con gli “Exterior Gateway Protocol” (EGP), che gestiscono il routing tra reti autonome separate.
Teoria dei grafi
I protocolli di routing si basano fortemente sulla teoria dei grafi per determinare i percorsi ottimali attraverso una rete. La teoria dei grafi fornisce un framework matematico per rappresentare e analizzare le relazioni tra gli elementi di una rete, come i nodi e i collegamenti.
La teoria dei grafi sistematizza questo tipo di oggetti e studia le possibili soluzioni (e ne determina la complessità computazionale) per problemi classici come quello dei ponti di Koenigsberg o del Postino Cinese. I problemi in sostanza sono questi: come posso visitare (se possibile) tutti i nodi di un grafo? oppure tutti gli archi? qual è il percorso più conveniente da un nodo all’altro? In quest’ultimo caso la “convenienza” si traduce in un costo numerico ogni volta che mi sposto da un nodo all’altro e l’algoritmo cerca di minimizzare (o massimizzare, a seconda del problema) la somma di questi costi elementari. Le applicazioni, come è noto, sono molteplici: dagli algoritmi di routing per le reti alla costruzione di percorsi più rapidi o meno inquinanti per Google Maps.
Ecco come i protocolli di routing utilizzano la teoria dei grafi:
Rappresentazione della Rete: La topologia di una rete può essere rappresentata come un grafo, dove i nodi rappresentano i dispositivi di rete (come router o switch) e gli archi rappresentano i collegamenti tra di essi. Questa rappresentazione è cruciale per comprendere la struttura della rete.
Nodi e Collegamenti: I nodi del grafo corrispondono ai dispositivi di rete, mentre gli archi del grafo corrispondono ai collegamenti fisici o logici tra questi dispositivi.
Algoritmi di Routing: Gli algoritmi di routing, come quelli utilizzati nei protocolli di routing, operano sul grafo per determinare il percorso ottimale da un punto all’altro nella rete. Due tipi principali di algoritmi di routing basati su grafi sono:
Distance-Vector: Questo tipo di algoritmo assegna un “vettore di distanza” a ciascun nodo, indicando la distanza stimata tra il nodo e ogni altro nodo nella rete. L’algoritmo converge gradualmente verso la soluzione ottimale (la distanza minima o shortest path). Un esempio di questo algoritmo è il Routing Information Protocol (RIP) che assegna un “costo” a ciascun percorso e sceglie il percorso con il costo complessivo più basso. RIP è spesso utilizzato in reti di dimensioni medio-piccole. Il calcolo del percorso in questo caso viene effettuato con l’algoritmo di Ford e Bellman.
Link-State: è un algoritmo più raffinato in quanto i suoi archi sono pesati. Questo tipo di algoritmo assegna uno “stato” a ciascun collegamento nella rete, indicando informazioni come la larghezza di banda e lo stato del collegamento. Gli algoritmi link-state determinano il percorso ottimale sulla base di queste informazioni dettagliate. Un esempio di questo tipo è Open Shortest Path First (OSPF) che assegna pesi ai collegamenti tra i router e calcola il percorso più breve in base a questi pesi. OSPF è più adatto per reti di grandi dimensioni e offre una maggiore flessibilità nella progettazione della rete. l calcolo del percorso in questo caso viene effettuato con l’algoritmo di Dijkstra.
Riassumendo, la teoria dei grafi fornisce un modo potente per modellare e risolvere problemi di routing nelle reti. I protocolli di routing utilizzano gli algoritmi basati su grafi per determinare in modo efficiente i percorsi ottimali attraverso le complesse topologie di rete.
Un Interior Gateway Protocol (IGP) calcola dunque i percorsi all’interno di un singolo AS. L’IGP consente ai nodi di reti diverse all’interno di un AS di scambiarsi dati. L’IGP consente inoltre l’inoltro dei dati attraverso un AS dall’ingresso all’uscita, quando l’AS fornisce servizi di transito.
Un Exterior Gateway Protocol (EGP) consente ai router all’interno di un AS di scegliere il miglior punto di uscita dall’AS per i dati che stanno tentando di instradare.
L’EGP e gli IGP in esecuzione all’interno di ciascun AS collaborano per instradare i dati su Internet. L’EGP determina gli AS che i dati devono attraversare per raggiungere la propria destinazione, e l’IGP determina il percorso all’interno di ciascun AS che i dati devono seguire per andare dal punto di ingresso (o punto di origine) al punto di uscita (o la destinazione finale).
Protocolli esterni (EGP)
Lo scambio dei pacchetti da un AS ad un altro avviene utilizzando il protocollo BGP.
Border Gateway Protocol
Gli AS annunciano la loro politica di routing ad altri AS e router tramite il Border Gateway Protocol (BGP).
Finora abbiamo visto come i pacchetti vengano girati all’interno della rete di un singolo AS, ma come passano da un AS all’altro? BGP è il protocollo per l’instradamento dei pacchetti di dati tra AS. Senza queste informazioni di instradamento, il funzionamento di Internet su larga scala diventerebbe presto poco pratico: i pacchetti di dati andrebbero persi o impiegherebbero troppo tempo per raggiungere la loro destinazione.
Ciascun AS utilizza BGP per annunciare di quali indirizzi IP è responsabile e a quali altri AS si connette. I router BGP prendono tutte queste informazioni dagli AS di tutto il mondo e le inseriscono in database chiamati tabelle di routing per determinare i percorsi più veloci da AS ad AS. Quando arrivano i pacchetti, i router BGP fanno riferimento alle loro tabelle di instradamento per determinare a quale AS dovrà andare successivamente il pacchetto.
Il protocollo whois ci fornisce alcune informazioni sui collegamenti tra AS.
Ogni AS può consorziarsi con altri AS per gestire più efficientemente il traffico dati. Queste informazioni vengono visualizzate in due sezioni dell’ouput del comando che sono import ed export. Nel contesto dell’output del comando “whois” per un ASN (Autonomous System Number) – vedi la trascrizione del comando più avanti -, le sezioni “import” ed “export” si riferiscono alle relazioni di peering (di “parità”) tra sistemi autonomi. Un sistema autonomo può avere accordi di peering con altri sistemi autonomi per facilitare lo scambio diretto di traffico senza dover passare attraverso terzi.
Ecco cosa significano solitamente le sezioni “import” ed “export”:
Import (Importazione): elenca i prefissi IP (range di indirizzi IP) che il sistema autonomo corrente riceve dai sistemi autonomi con cui ha un accordo di peering. Questi prefissi sono quelli che il sistema autonomo corrente “importa” dalla rete dei suoi peer. In altre parole, indica quali reti l’ASN corrente è disposto a accettare direttamente dai suoi partner di peering: “Io, AS3209, sono a disposizione per far transitare i pacchetti provenienti da AS6762 e AS1913″.
Export (Esportazione): elenca i prefissi IP che il sistema autonomo corrente annuncia e rende disponibili per essere raggiunti da altri sistemi autonomi con cui ha un accordo di peering: “i pacchetti destinati a AS1913 li faccio transitare – o li consegno – io, AS3209!”. Questi prefissi sono quelli che il sistema autonomo corrente “esporta” verso la rete dei suoi peer. In altre parole, indica quali reti il sistema autonomo corrente è disposto a rendere disponibili ai suoi partner di peering. Queste informazioni sono cruciali per la configurazione e la gestione del routing nei sistemi autonomi. Gli operatori di rete utilizzano queste informazioni per definire come il traffico dovrebbe fluire attraverso la rete, in base agli accordi di peering stabiliti. In genere, questi accordi sono basati su principi di reciprocità, dove due sistemi autonomi concordano di scambiare traffico direttamente per migliorare l’efficienza del routing e ridurre i costi di transito.
marco@poleni:~$ whois AS3269
% This is the RIPE Database query service.
% The objects are in RPSL format.
%
% The RIPE Database is subject to Terms and Conditions.
% See https://apps.db.ripe.net/docs/HTML-Terms-And-Conditions
% Note: this output has been filtered.
% To receive output for a database update, use the "-B" flag.
% Information related to 'AS3209 - AS3353'
as-block: AS3209 - AS3353
descr: RIPE NCC ASN block
remarks: These AS Numbers are assigned to network operators in the RIPE NCC service region.
mnt-by: RIPE-NCC-HM-MNT
created: 2018-11-22T15:27:19Z
last-modified: 2018-11-22T15:27:19Z
source: RIPE
% Information related to 'AS3269'
% Abuse contact for 'AS3269' is 'abuse@business.telecomitalia.it'
aut-num: AS3269
as-name: ASN-IBSNAZ
org: ORG-IA34-RIPE
import: from AS6762 action pref=100; accept ANY
import: from AS1913 action pref=100; accept AS1913
import: from AS2162 action pref=100; accept AS2162
import: from AS2164 action pref=100; accept AS2164
import: from AS4589 action pref=100; accept AS4589
import: from AS5395 action pref=100; accept AS5395
...
export: to AS1913 announce ANY
export: to AS2162 announce ANY
export: to AS2164 announce ANY
export: to AS5395 announce ANY
export: to AS5502 announce ANY
export: to AS5609 announce ANY
export: to AS6665 announce ANY
export: to AS6840 announce ANY
export: to AS6875 announce ANY
export: to AS8265 announce ANY
export: to AS8463 announce ANY
export: to AS8660 announce ANY
export: to AS8754 announce ANY
export: to AS8822 announce ANY
export: to AS8884 announce ANY
export: to AS8911 announce ANY
export: to AS8978 announce ANY
export: to AS8980 announce ANY
...
Il ruolo di BGP è cruciale allo stesso modo del protocollo DNS e il suo funzionamento è molto simile, quello di una database distribuito. Con così tanti AS nel mondo, infatti, i router BGP aggiornano costantemente le loro tabelle di routing. Quando le reti vanno offline, nuove reti vengono online e gli AS espandono o contraggono il loro spazio di indirizzi IP, tutte queste informazioni devono essere annunciate tramite BGP in modo che i router BGP possano modificare le loro tabelle di instradamento.
Protocolli interni (IGP)
IS-IS Protocol
Il protocollo IS-IS (Intermediate System – Intermediate System) fa parte di una famiglia di protocolli di routing IP ed è un protocollo IGP (Interior Gateway Protocol) per Internet, utilizzato per distribuire le informazioni di routing IP attraverso un singolo sistema autonomo (AS) in una rete IP.
IS-IS è un protocollo di routing dello stato del collegamento (link-state), il che significa che i router scambiano informazioni sulla topologia con i vicini più prossimi. Le informazioni sulla topologia vengono diffuse in tutto l’AS, in modo che ogni router all’interno dell’AS abbia un quadro completo della topologia dell’AS. Questa immagine viene quindi utilizzata per calcolare i percorsi end-to-end attraverso l’AS, normalmente utilizzando una variante dell’algoritmo Dijkstra. Pertanto, in un protocollo di routing dello stato del collegamento, l’indirizzo dell’hop successivo a cui vengono inoltrati i dati viene determinato scegliendo il miglior percorso end-to-end verso la destinazione finale.
OSPF
Anche OSPF è un protocollo di tipo IGP.
Ogni router OSPF distribuisce informazioni sul proprio stato locale (interfacce utilizzabili, vicini raggiungibili e costo di utilizzo di ciascuna interfaccia) ad altri router pubblicando un messaggio LSA (Link State Advertisement). D’altra parte, ogni router utilizza i messaggi ricevuti per costruire un database identico che descrive la topologia dell’AS.
Da questo database, ogni router calcola la propria tabella di instradamento utilizzando un algoritmo Shortest Path First (SPF) o Dijkstra. Questa tabella di routing contiene tutte le destinazioni conosciute dal protocollo di routing, associate all’indirizzo IP dell’hop successivo e all’interfaccia in uscita.
RIP
RIP è un semplice protocollo di routing vettoriale. In un protocollo di routing vettoriale, i router scambiano informazioni sulla raggiungibilità della rete con i vicini più prossimi. In altre parole, i router comunicano tra loro gli insiemi di destinazioni (“prefissi di indirizzo”) che possono raggiungere e l’indirizzo del salto successivo a cui inviare i dati per raggiungere tali destinazioni. Ciò contrasta con gli IGP link-state; i protocolli di vettorizzazione si scambiano percorsi tra loro, mentre i router dello stato dei collegamenti scambiano informazioni sulla topologia e calcolano i propri percorsi localmente.
Chiariamo alcuni termini relativi al routing IP
Elenco nel seguito alcuni termini usati in precedenza per spiegarli più approfonditamente.
Cos’è una policy (o politica) di routing per un AS?
Una policy di routing è l’unione di due elenchi:
un elenco dello spazio degli indirizzi IP controllato dall’AS (quindi gli indirizzi all’interno della rete dell’AS),
un elenco degli altri AS a cui si connette.
Queste informazioni sono necessarie per instradare i pacchetti alle reti corrette. Gli AS annunciano queste informazioni su Internet utilizzando il Border Gateway Protocol (BGP).
Cos’è uno spazio di indirizzi?
Un gruppo o un intervallo specificato di indirizzi IP è denominato “spazio degli indirizzi IP”. Ciascun AS controlla una certa quantità di spazio di indirizzi IP. (Un gruppo di indirizzi IP può anche essere chiamato “blocco” di indirizzi IP.)
Immaginiamo per un instante che tutti i numeri di telefono del mondo siano elencati in ordine numerico in un mega elenco, che due aziende di telecomunicazioni (la Phone Company A e la Phone Company B) gestiscano l’intero traffico telefonico globale. Supponiamo inolter che a ciascuna compagnia telefonica sia assegnato un intervallo di numeri di telefono:
i numeri controllati dalla Phone Co. A da 000-0000 a 599-9999 e
i numeri controllati dalla Phone Co. B da 600-0000 a 999- 9999.
Se Alice è connessa alla rete telefonica tramite Phone Co. A e chiama Michelle (connessa anch’essa a Phone Co. A) al 555-2424, la sua chiamata verrà instradata a Michelle tramite Phone Co. A.
Se chiama Jenny (connessa invece a Phone Co. B) al 867-5309, la sua chiamata verrà instradata a Jenny tramite Phone Co. B.
Questo è più o meno il modo in cui funziona lo spazio degli indirizzi IP.
Supponiamo che ACME (A Company Making Everything) gestisca un AS e controlli un intervallo di indirizzi IP che include l’indirizzo 192.0.2.253, che è assegnato per esempio ad server web. Se un computer dall’altra parte del mondo invia un pacchetto a 192.0.2.253, questo pacchetto raggiungerà prima o poi l’AS controllato da ACME. Se invece, sempre dal computer dall’altra parte del mondo, vengono inviati pacchetti a 198.51.100.255, questi andranno a un AS diverso (sebbene possano transitare, lungo il loro percorso, per l’AS di ACME).
Cosa sono i prefissi IP?
Quando gli ingegneri di rete comunicano quali indirizzi IP sono controllati da determinati AS, lo fanno parlando dei “prefissi” degli indirizzi IP posseduti da ciascun AS.
Un prefisso di indirizzo IP è un intervallo di indirizzi IP. A causa del modo in cui vengono scritti gli indirizzi IP, i prefissi degli indirizzi IP sono espressi in questo modo: 192.0.2.0/24.
Attenzione però! Questo prefisso rappresenta gli indirizzi IP da 192.0.2.0 a 192.0.2.255, non da 192.0.2.0 a 192.0.2.24. La “/24” indica la lunghezza del prefisso in termini di bit. In questo caso, “/24” significa che i primi 24 bit dei 32 rappresentano la parte di rete dell’indirizzo IP, mentre i rimanenti 8 bit rappresentano la parte di host. Potete rivedere alcuni di questi concetti qui.
L’output del comando ip route
Il comando “ip route” è utilizzato nei sistemi operativi basati su Linux per visualizzare e manipolare la tabella di routing del kernel (lo smistamento di pacchetti tcp/ip è infatti un compito svolto a basso livello direttamente dal kernel del Sistema Operativo). L’output di questo comando fornisce informazioni dettagliate sulla configurazione della tabella di routing del sistema. Ecco un esempio di come potrebbe apparire l’output:
default via 192.168.1.1 dev eth0 proto static
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100
10.0.0.0/8 via 10.0.0.1 dev tun0
Di seguito è spiegato il significato di ciascuna riga dell’output:
Riga predefinita (default route):
default via 192.168.1.1 dev eth0 proto static
Indica che tutti i pacchetti destinati a indirizzi non inclusi nelle altre voci della tabella di routing (default) verranno instradati attraverso l’interfaccia di rete eth0 verso il gateway con l’indirizzo IP 192.168.1.1. Il protocollo è static, il che significa che questa voce è stata configurata staticamente.
Riga di rete locale (local network):
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100
Specifica che la rete con l’indirizzo 192.168.1.0 e maschera di sottorete 255.255.255.0 è raggiungibile tramite l’interfaccia di rete eth0. L’indirizzo IP locale dell’interfaccia eth0 è 192.168.1.100. “scope link” significa che significa che il pacchetto viene semplicemente rilasciato sul collegamento (link) e inviato direttamente all’interfaccia poiché la destinazione è nella sottorete e “ascolterà” il pacchetto – quindi non è necessario alcun gateway. In altre parole, significa che la rete è valida e raggiungibile tramite questo dispositivo (eth0).
Riga specifica (specific route):
10.0.0.0/8 via 10.0.0.1 dev tun0
Indica che la rete con l’indirizzo 10.0.0.0 e maschera di sottorete 255.0.0.0 è raggiungibile attraverso l’interfaccia di rete tun0 e deve passare attraverso il gateway con l’indirizzo IP 10.0.0.1.
Un abuona risorsa per una descrizione completa del comando ip è in [2]
Ho trovato questa bella immagine realizzata da Nassim sul forum ServerFault.com:
Creare un nuovo branch nel repository Git viene naturale se pensiamo che qualsiasi cosa facciamo al codice possa sporcare il branch master (o quello in cui stiamo lavorando) .
Per manetenere il branch attivo pulito possiamo quindi creare una nuova derivazione dove possiamo fare quello che vogliamo senza interferire con il lavoro degli altri sviluppatori. Come lavorassimo nella nostra piccola sandbox.
Git: creare branch per ogni microattività
Creare un nuovo branch e iniziare a lavorare
Per creare un nuovo branch e spostarti su di esso in Git, puoi utilizzare il comando git checkout -b. Ecco come puoi farlo:
git checkout -b nome_del_tuo_nuovo_branch
Questo comando combina due azioni (grazie all’opzione -b): crea un nuovo branch e si sposta su di esso. Sostituisci “nome_del_tuo_nuovo_branch” con il nome che desideri assegnare al tuo nuovo branch.
Ad esempio, se vuoi creare un branch chiamato “mio-nuovo-branch”, esegui il seguente comando:
git checkout -b mio-nuovo-branch
In alternativa, puoi eseguire i due comandi separatamente, se preferisci:
git branch nome_del_tuo_nuovo_branch # Crea il nuovo branch
git checkout nome_del_tuo_nuovo_branch # Sposta su di esso
Da notare che se stai usando una versione di Git più recente (2.23 o successiva), puoi anche utilizzare il comando git switch per creare e spostarti su un nuovo branch:
git switch -c nome_del_tuo_nuovo_branch
Questo comando fa essenzialmente la stessa cosa del primo esempio con git checkout -b.
Dopo aver creato il tuo nuovo branch, puoi iniziare a lavorare su di esso e apportare le modifiche necessarie.
Riportare le modifiche al branch master
Per effettuare il merge di un branch nel branch master in Git, segui questi passaggi:
Assicurati di trovarti nel branch master:
git checkout master
Poi esegui il merge con il tuo branch appena creato (sostituisci “nome_del_tuo_nuovo_branch” con il nome del tuo branch):
git merge nome_del_tuo_nuovo_branch
Se non ci sono conflitti durante il merge, Git eseguirà il merge automaticamente. Tuttavia, se ci sono conflitti, dovrai risolverli manualmente prima di completare il merge.
Dopo aver eseguito il merge, puoi eliminare il branch che hai creato (se lo desideri):
git branch -d nome_del_tuo_nuovo_branch
Se il branch che vuoi eliminare contiene delle modifiche che non sono state ancora unite, Git potrebbe impedirti di eliminarlo. In tal caso, puoi forzare l’eliminazione con:
git branch -D nome_del_tuo_nuovo_branch
Questo elimina il branch anche se ci sono modifiche non ancora unite.
Ricorda che è sempre buona pratica effettuare il merge dei cambiamenti più recenti da origin nel tuo branch prima di eseguire il merge del tuo branch in master. Puoi farlo con:
git checkout master
git pull origin master # Aggiorna master con le modifiche più recenti dal repository remoto
git checkout nome_del_tuo_nuovo_branch
git merge master # Esegue il merge delle modifiche di master nel tuo branch
Questo aiuta a ridurre la probabilità di conflitti e assicura che il tuo branch sia aggiornato con le ultime modifiche di master prima di essere unito.
Possiamo fare un po’ di spazio eliminando pacchetti snap obsoleti.
L’utility Disk Analyzer mi indica come cartella più voluminosa come prima tra le cartelle a dimensione variabile – collocate sotto la directory /var – la directory /var/lib/snapd/snaps):
eccetera. Qui vengono conservati anche pacchhetti superati, per esempio tra chromium_2704.snap e chromium_2695.snap possiamo conservare solo il più recente (2704).
I pacchetti possono pesare anche alcune centinaia di megabytes per cui è opportuno buttare via quello che non serve più.
Più che una challenge, questo è un’approfondimento su una peculiarità di Python: la mutabilità nei tipi di variabili.
In Python i tipi di dato si dividono in mutabili e immutabili.
Immutabile non significa che non si può cambiare, come suggerirebbe la parola (a mio modestissimo parere la scelta del termine è molto infelice), significa invece che posso cambiare il dato e che in realtà il compilatore, nel sottobosco, lascerà immutata la variabile precedentemente definita e creerà un’altra variabile con il nuovo valore!
Breve iter per exempla
Vediamo una rassegna con esempi per alcuni tipi di dato.
Variabili
Le variabili sono immutabili. Per verificarlo stampiamo l’indirizzo della locazione di memoria che contiene la variabile.
a = 1
print("a=", a)
print("address=", id(a))
a = 2
print("a=", a)
print("address=", id(a))
Come si vede, assegnando un nuovo valore alla stessa variabile, in realtà Python ne ha creata un’altra e se mi riferisco alla variabile “a” il puntatore ad essa sarà l’ultimo ad essere stato definito.
La variabile precedente non viene cambiata (questo è il senso di immutabile) e va direttamente a fare parte del garbage.
Quindi: per cambiare valore ad una variabile, Python la ridefinisce.
Anche se modifico il valore di una variabile tramite un’operazione, il runtime occupa una seconda locazione di memoria:
Qui la a che viene ridefinita è in effetti un’altra variabile rispetto a quella contenuta nella lista q che, a sua volta, è diversa dalla prima a che avevo definito:
Come si vede l’indirizzo dell’oggetto (l’istanza della classe) non cambia ma, all’interno della classe, le sue proprietà sono “variabili” e sono quindi immutabili, tant’è che se ne cambio il valore, cambia anche l’identificativo.
Attenzione a non confondersi, perché l’indirizzo di una variabile di un tipo immutabile cambia, mentre l’indirizzo di una variabile del tipo mutabile non cambia 🙂
Tuple
Le tuple sono simili alle liste: a differenza di queste si definiscono con le parentesi tonde e, diversamente dagli altri oggetti, sono immutabili:
Attenzione che c’è un’altra differenza sostanziale con le liste: non posso manipolare i singoli elementi della tupla, allo stesso modo di quanto accade con le stringhe:
Output:
Errore! 'tuple' object does not support item assignment
s = "ciao"
try:
s[0] = "m"
except TypeError as e:
print("Errore!", e)
Uno pensa che il programma stampi miao invece di ciao ma si sbaglia:
Output:
Errore! 'str' object does not support item assignment
Attenzione: l’utilizzo delle parentesi tonde per definire una tupla espone Python ad una pericolosa ambiguità: come faccio a definire una tupla con un solo elemento senza confondere la notazione con quella di una funzione?
Risposta: una tupla con un solo elemento (un singoletto) si scrive con largomento e la virgola:
>>> t=(1,)
>>> t
(1,)
Tuple packing
Le tuple sono formidabili perché consentono cose molto performanti come questa:
>>> a, b, c = 1, ['a', 0], 3.14
>>> a
1
>>> b
['a', 0]
>>> c
3.14
>>>
Alla fine rimangono solo le variabili, la tupla viene distrutta subito dopo l’assegnazione. Questo consente di fare questa operazione molto elegante:
>>> a, c = 2, 3.14
>>> a, c
(2, 3.14)
>>> a, c = c, a
>>> a, c
(3.14, 2)
Il swap di variabili è stato fatto senza utilizzare una terza variabile, come si fa di solito.
Attenzione perché questo non è mai scritto chiaramente: sono mutabili nel senso che posso modificare un singolo elemento. Se invece ridefinisco l’intera lista, anch’essa si comporta come un oggetto immutabile:
Gli oggetti immutabili sono quelli i cui valori non possono essere modificati dopo la creazione.
Esempi di tipi di dati immutabili in Python includono tuple, stringhe e interi.
Quando si modifica un oggetto immutabile, in realtà si crea un nuovo oggetto con il valore modificato.
Mutabilità:
Gli oggetti mutabili sono quelli i cui valori possono essere modificati dopo la creazione.
Esempi di tipi di dati mutabili in Python includono liste, dizionari e insiemi.
La modifica di un oggetto mutabile influisce direttamente sull’oggetto stesso, senza crearne uno nuovo.
In modo abbastanza elementare si potrebbe dire che le variabili contengono riferimenti agli oggetti, mentre gli oggetti vivono in posizioni ben definite della memoria [2].
La ratio dietro a questa partizione.
Ma qual è la ragione che sta dietro alla mutabilità delle variabili di Python? Perché alcuni tipi di dato sono mutabili e altri no?
La ragione per avere oggetti mutabili e immutabili in Python è legata a diverse considerazioni di progettazione e prestazioni. In particolare mi sono chiesto perché l’utilizzo di tipi immutabili sia considerato più efficiente e in effetti non è esattamente così:
Assegnazione diretta: Gli oggetti immutabili possono essere assegnati direttamente in memoria, poiché il loro stato non cambia. Questo elimina la necessità di allocare e deallocare memoria dinamicamente, rendendo il processo più veloce.
Condivisione sicura: Poiché gli oggetti immutabili non possono essere modificati dopo la creazione, possono essere condivisi in modo sicuro tra diverse parti del codice senza preoccuparsi delle modifiche accidentali da parte di altre parti. In particolare sono thread-safe. Questo riduce il rischio di condizioni di conflitto e semplifica la gestione della concorrenza.
Hashing efficiente: Gli oggetti immutabili sono hashabili, il che significa che possono essere utilizzati come chiavi in strutture dati come dizionari e insiemi. Questo è possibile perché l’hash di un oggetto immutabile sarà costante durante il suo ciclo di vita.
Ottimizzazioni del compilatore: La natura immutabile dei dati consente al compilatore di eseguire ottimizzazioni più aggressive. Ad esempio, il compilatore può decidere di memorizzare una singola copia di un valore immutabile utilizzato in più parti del codice anziché allocarne una copia separata per ciascuna occorrenza.
Semplifica il debug: Gli oggetti immutabili semplificano il processo di debug perché il loro stato non può essere modificato. Questo rende più facile ragionare sul comportamento del programma in fasi diverse dell’esecuzione.
Tuttavia, gli oggetti immutabili hanno anche degli svantaggi, come ad esempio il costo di creare nuovi oggetti ogni volta che si vuole modificare il valore di una variabile. Questo può portare a un overhead di memoria e a una maggiore pressione sul garbage collector [3] (per una spiegazione sul funzionamento del garbage collector si può fare rifermiento ad un mio articolo ,sempre in questo blog; l’articolo spiega come funziona il GC in Java, ma il concetto è simile anche per Python). Inoltre, gli oggetti immutabili possono essere meno flessibili e intuitivi da usare rispetto agli oggetti mutabili, soprattutto quando si lavora con strutture dati complesse.
In sintesi, la scelta tra mutabilità e immutabilità dipende dalle esigenze specifiche del programma. Python offre entrambe le opzioni per fornire ai programmatori flessibilità e controllo sulla gestione dei dati.
Spariti tutti i dubbi sulle proprietà di mutabilità e la differenza tra tuple e liste in Python? 😉
Ma allora già che ci siamo, dai… aggiungiamo la challenge. Non ha molto a che fare con l’argomento tratttato. Diciamo che studiando questa challenge poi sono approdato al problema della mutabilità, per questo lo presento qua.
Challenge di oggi
La funzione round trasforma un numero a virgola mobile in un intero. È curioso analizzarne il comportamento della funzione nei punti discriminanti come i seminteri: arrotondo per eccesso o per difetto?
Esempio:
print("round(5.5) = ", round(5.5))
Output:
round(5.5) = 6
Quindi mi aspetto che round(6.5)=7. Controlliamo:
print("round(6.5) = ", round(6.5))
Output:
round(6.5) = 6
Com’è possibile!!?!
Risposta
Il rounding operato dalla funzione built-in di Python si chiama arrotondamento di Banker: si tratta di un algoritmo per arrotondare le quantità a numeri interi, in cui i seminteri vengono arrotondati all’intero pari più vicino. Pertanto, 0,5 viene arrotondato per difetto a 0; 1,5 arrotonda a 2. Un algoritmo simile può essere costruito per arrotondare ad altri insiemi oltre agli interi (in particolare, insiemi che hanno un intervallo costante tra membri adiacenti) [3].
Riferimenti
Christian Hill, Learning Scientific Programming with Python, 2020, Cambridge University Press
Leodanis Pozo Ramos, Python’s Mutable vs Immutable Types: What’s the Difference?, 2023, Real Python
Benvenuti nella raccolta di “Python Challenges”, un viaggio attraverso la risoluzione di problemi con un certo grado di difficoltà utilizzando il potente linguaggio di programmazione Python. In questo articolo, esploreremo una serie di sfide stimolanti, ciascuna progettata per mettere alla prova le vostre abilità e ampliare la vostra comprensione della programmazione.
L’Arte di superare le Python Challenges
La risoluzione di problemi è l’essenza della programmazione. Ciò che rende Python così straordinario è la sua flessibilità e facilità d’uso, il che lo rende ideale per affrontare una vasta gamma di sfide computazionali. Durante il nostro percorso, affronteremo problemi di diversa natura, dai calcoli matematici avanzati all’analisi di dati complessi.
Struttura degli Esempi
Ogni esempio sarà presentato con un problema specifico e seguito da una soluzione dettagliata scritta in Python. Per rendere l’esperienza più istruttiva, useremo approcci e tecniche comuni, spiegando passo dopo passo il ragionamento dietro a ciascuna soluzione.
Destinatari
Questo articolo è pensato per programmatori di tutti i livelli. Se sei un principiante, troverai esempi di problemi che ti sfideranno ma allo stesso tempo ti aiuteranno a comprendere i concetti fondamentali. Se sei un programmatore esperto, sarai stimolato da sfide più avanzate che metteranno alla prova la tua abilità nel trovare soluzioni efficienti.
Pronti per la Sfida?
Preparatevi per affrontare le sfide che vi presenteremo. Ogni problema è un’opportunità di apprendimento, un modo per affinare le vostre capacità di pensiero computazionale e diventare un programmatore più esperto.
Senza ulteriori indugi, iniziamo il nostro viaggio attraverso gli “Python Challenges”!
La prova di oggi
Da un esercizio di proficiency:
Write a function add_n that takes a single numeric argument n, and returns a function. The returned function should take a vector v as an argument and return a new vector with the value for n added to each element of vector v. For example, add_n(10)([1, 5, 3]) should return [11, 15, 13].
Ho risolto questo problema definendo una funzione all’interno di un’altra funzione (ma magari c’è anche un altro modo):
def add_n(n):
def sum_scalar(v):
w = []
for i in range(0, len(v)):
w.append(n + v[i])
return w
return sum_scalar
Poi la funzione viene invocata nel modo che segue: prima viene definito un puntatore alla funzione passando il primo parametro, dopodiché si chiama il puntatore passando il secondo parametro:
v = [1, 5, 3]
y = add_n(10)
print("The value of a + v is", y(v))
Output:
$ python self_assessment.py
The value of a + v is [11, 15, 13]
Fig. 1 – Agostini, Krausz, L’Hullier insigniti del premio Nobel per la Fisica 2023
L’Ottica sembra diventata la regina delle discipline all’interno della Fisica: già nel 2022 erano stati premiati con Nobel tre fisici (Aspect, Clauser e Zeilinger) per i lavori sui fotoni e il loro contributo allo sviluppo dell’Informazione Quantistica: la produzione di fotoni entangled viene fatta con i laser. Quest’anno si parla sempre di laser da un punto di vista più “meccanico”, per così dire: sono stati premiati Pierre Agostini (Ohio State University, Columbus, USA), Ferenc Krauss (Max Planck Institute of Quantum Optics, Garching, Germany; Ludwig-Maximilians-Universität München, Munich, Germany) e Anne l’Hullier (Lund University, Lund, Sweden) per i loro lavori sulla produzione di impulsi laser ultrabrevi.
Quello di cui voglio parlarvi qui non è esattamente il premio Nobel per la Fisica 2023 ma qualcosa che ha a che vedere con questo premio. La maggior parte delle informazioni che uso in questo articolo le ho scritte in una tesina per il corso di Quantum Information che ho seguito nell’ambito del dottorato di Ricerca in Ingegneria delle Telecomuncazioni tenuto nell’A.A. 2015-2015 dai proff. Paolo Villoresi e Giuseppe Vallone.
Poi concluderò con un cenno all’argomendo degli impulsi ultrabrevi ad attosecondo che sono l’oggetto del premio Nobel 2023 per la Fisica.
La motivazione per esteso del premio ai tre fisici che è stata data dalla Reale Accademia delle Scienze di Svezia è la seguente:
For experimental methods that generate attosecond pulses of light for the study of electron dynamics in matter
Dunque il premio è per l’invenzione di metodi sperimentali che generano impulsi di luce di durata dell’ordine dell’attosecondo e poi è citato l’impiego di questa tecnica: quella di osservare la dinamica degli elettroni nella materia.
Ora, la traiettoria vera e propria degli elettroni intesa come descrizione della curva nello spazio delle fasi (posizione, quantità di moto o impulso) non la possiamo vedere: in quanto particelle quantistiche, le loro variabili dinamiche come posizione e impulso (dette variabili coniugate) non possono essere note simultanemente con precisione arbitraria per il noto principio di indeterminazione di Heisenberg: il prodotto delle incertezze delle loro misure è maggiore o uguale ad una quantità piccola:
\Delta p \Delta x \geq \frac{\hbar}{2}
dove \Delta p è l’incertezza sulla misura dell’impulso (che è proporzionale alla velocità) e \Delta x è l’incertezza sulla posizione. \hbar(“acca tagliato”) è la costante di Dirac, un numero piccolissimo, ed è pari alla costante di Planckh – che vedremo dopo – divisa per 2 \pi. Per questo la constante di Dirac è detta anche costante di Planck ridotta. La relazione è di proporzionalità inversa, per cui se ho una piccola incertezza sulla posizione ho grande incertezza sulla velocità e viceversa.
Però possiamo conoscere con precisione una delle due variabili e la tecnica degli impulsi ultrabrevi ci aiuta in questo.
Quello che volevo raccontare in questo articolo è il modo che ho imparato per produrre impulsi ultrabrevi: si potrebbe pensare di realizzare un impulso ultra breve interrompendo il raggio laser con un otturatore meccanico o elettronico, del tipo utilizzato nelle fotocamere digitali o negli smartphone.
Nulla di tutto questo.
La risoluzione temporale con otturatori elettronici arriva al massimo all’ordine del microsecondo (1 \mu s = 10^{-6} s = 0,000001 s = 1 milionesimo di secondo). Quelli meccanici arrivano a malapena al millesimo di secondo.
Io ho visto funzionare sistemi di produzione di impulsi dell’ordine del femtosecondo; il Nobel è stato vinto per una tecnica che ha permesso di abbassare di ulteriori tre ordini di grandezza la durata di questi impulsi e raggiungere gli attosecondi.
Quest’anno è stato molto divertente vedere testate giornalistiche attribuire il premio agli scienziati per la scoperta o l’invenzione dell’attosecondo. L’attosecondo è solo un sottomultiplo del secondo, non è un’invenzione. Il premio è invece per lo sviluppo della tecnica che consente di produrre impulsi della durata degli attosecondi. Quindi prima di inoltrarci nel terreno della tecnica degli impulsi ultrabrevi rivediamo questa nomenclatura.
La durata degli impulsi: i nomi degli ordini di grandezza.
Fermiamoci un attimo a rivedere questi prefissi standard definiti nel Sistema Internazionale di Misura ISO per indicare le frazioni dell’unità.
sottomultipli
prefisso
simbolo
potenza
multipli
prefisso
simbolo
potenza
millesimo
milli
m
10^{-3}
migliaia
kilo
k
10^3
milionesimo
micro
\mu
10^{-6}
milioni
Mega
M
10^6
miliardesimo
nano
n
10^{-9}
miliardi
Giga
G
10^9
millesimo di miliardesimo
pico
p
10^{-12}
migliaia di miliardi
Tera
T
10^{12}
milionesimo di miliardesimo
femto
f
10^{-15}
milioni di miliardi
Peta
P
10^{15}
miliardesimo di miliardesimo
atto
a
10^{-18}
miliardi di miliardi
Exa
E
10^{18}
Tabella dei multipli, e sottomultipli dell’unità, con potenza di dieci, prefisso e simbolo.
Ne esisterebbero altri quattro (due per i multipli , Zetta e Yotta, e due per i sottomultipli, zepto e yocto, (parliamo sempre di multipli di potenze di 10^{\pm 3}) ma sono così esotici che tralascio.
Scorrendo la tabella, ci rendiamo conto che gli ordini di grandezza più in basso sono molto al di fuori del nostro senso comune. A immaginare un chilometro, un Gigabyte o un microsecondo forse ci arriviamo. Gli altri prefissi descrivono invece quantità troppo grandi o troppo piccole, che probabilmente sfuggono alla nostra immaginazione.
Ma una proporzione può esserci d’aiuto.
Il numero di femtosecondi in un secondo è 10^{15}. Ci sono perciò più femtosecondi in un secondo, che giorni solari in tutta la storia dell’universo dal Big Bang a oggi (l’età dell’Universo in giorni è pari a circa 12 \times 10^{12} mentre un secondo contiene 10^{15} femtosecondi).
D’altra parte, il numero di attosecondi contenuti in un secondo è 10^{18}. Ci sono più attosecondi in un secondo, che secondi in tutta l’età dell’Universo (che sono circa 4 \times 10^{17}).
Come vengono prodotti impulsi dell’ordine del femtosecondo
L’argomento è la durata estremamente breve di questi impulsi. La capacità di generare impulsi laser così brevi è fondamentale per molte applicazioni scientifiche e tecnologiche avanzate.
Questi impulsi laser sono così corti che possono essere utilizzati per esplorare e studiare eventi molto veloci o su scale piccolissime. Ad esempio, vengono usati per studiare cosa succede quando le particelle microscopiche si muovono o interagiscono tra loro.
Gli impulsi laser ultrabrevi sono brevissimi flash di luce concentrata. Per capire meglio, immaginate una torcia elettrica che emette un lampo di luce molto breve, tanto breve che dura solo una frazione di secondo. Gli impulsi laser ultrabrevi sono simili, ma la loro luce è estremamente concentrata e dura solo per un tempo infinitesimale.
Una delle tecniche usata per produrre impulsi al femtosecondo l’ho studiata con il prof. Paolo Villoresi nel 2015 ai Laboratori LUXOR dell’Istituto di Fotonica e Nanotecnologie (IFN) del CNR di via Trasea a Padova, e si chiama mode locking. È utile prima una introduzione a questi argomenti.
Laser
Il laser è una speciale lampada in cui una sorgente convenzionale (una lampada normale) è racchiusa in una cavità tra due specchi parabolici (cavità di Fabry-Perot).
Fig. 2 – Cavità di Fabry-Perot con mezzo attivo e sistema di pompa
Le varie frequenze contenute nella luce prodotta dalla lampada si riflettono avanti e indietro sugli specchi, ma solo le lunghezze d’onda che sono sottomultiple della lunghezza della cavità sopravvivono costituendo onde stazionarie: è lo stesso principio di funzionamento delle corde di una chitarra: si impone solo un’onda stazionaria tra ponticello e capotasto – o il dito del chitarrista – più i suoi sottomultpli – le armoniche).
Fig. 3 – Onde stazionarie sulle corde producono il suono della chitarra (ref: https://mathone.it)
Poi c’è un componente fondamentale che distingue un laser da una semplice cavità risonante: quest’onda stazionaria investe uno spessore di materiale attivo – che può essere solido, liquido o gas – posto al centro della cavità, un materiale che amplifica in un modo molto selettivo – che vedremo – una determinata gamma di frequenze e smorza tutte le altre, per cui i modi – le frequenze – che sopravvivono sono molto pochi ma vengono amplificati tantissimo. A seconda del materiale attivo abbiamo vari tipi di colori:
laser a rubino, che emette sui 694.3 nm (rosso)
laser Nd:YAG (una miscela contenente l’1% di Neodimio e Granato di Ittrio e Alluminio): emette due armoniche, rispettivamente 1064 nm (infrarosso), 532 nm (verde)
laser a eccimeri, 157 nm (ultravioletto)
ma ce ne sono moltissimi altri. Per esempio nei lettori di compact disc i laser sono realizzati con un diodo a semiconduttore.
Aggiungo anche che i laser possono essere realizzati in un’amplissima gamma di potenze, dal diodo laser che spara impulsi dentro ad una fibra ottica ai laser per tagliare le lamiere.
Amplificatori di luce
Vediamo ora il principio secondo cui viene amplificata la luce.
Il modello atomico che possiamo prendere come riferimento è l’atomo di Bohr (quello di Bohr è oramai un vecchio modello superato dal modello a orbitali ma per quello di cui parliamo qui funziona benissimo lo stesso), un modello con
un nucleo centrale – che non entra nel gioco
ed elettroni – questi invece sono i protagonisti – disposti in orbite circolari ad energia quantizzata. Cioè gli elettroni non possono stare dove vogliono ma devono occupare stati con numeri quantici ben definiti, il principale dei quali è l’energia che non può avere un valore qualsiasi ma può assumere solo valori discreti. Il numero quantico dell’energia determina il raggio dell’orbita.
I fotoni che compongono la luce vengono prodotti dal “rilassamento” degli elettroni all’interno dell’atomo: quando passano da uno stato ad energia superiore ad uno di energia inferiore (in questo senso è da intendere il relax), riasciano un quanto di luce di frequenza proporzionale alla differenza di energia dei due livelli.
\nu = \frac{E_{sup} - E_{inf}}{h}
Il coefficiente di proporzionalità è detto costante di Planck e vale circa 6,63 \times 10^{-34} J \cdot s.
Questo fenomeno si chiama emissione. Se avviene in modo naturale si dice emissione spontanea.
Al contrario, l’assorbimento di un quanto di luce fa saltare l’elettrone da un orbitale meno energetico ad uno più energetico.
Il laser sfrutta questo meccanismo di assorbimento (durante la fase di pompa) ed emissione e lo realizza in modo continuo.
Il mezzo attivo aggiunge alla radiazione di pompa, con i suoi atomi, radiazione della stessa frequenza e fase dell’onda di pompa attraverso l’emissione stimolata di radiazione, grazie a elettroni che in una prima fase vengono pompati (si dice propri così nel gergo) a livelli energetici superiori assorbendo l’energia della lampada (che in questo contesto viene chiamata pompa) e poi ricadono nel loro livello energetico fondamentale, emettendo fotoni dello stesso colore (frequenza) e della stessa fase. Questo fenomeno dell’emissione stimolata della radiazione è stato studiato da Albert Einstein (eh sì, si è occupato di un sacco di cose oltre alla Relatività) che ha scritto le equazioni che si usano tutt’ora per progettare i laser: si tratta di quella che oggi viene chiamata teoria semiclassica dell’assorbimento della radiazione che formulò nel suo articolo del 1917 intitolato “Zur Quantentheorie der Strahlung” (Sulla teoria quantistica della radiazione), noto anche come “On the Quantum Theory of Radiation”.
LASER è l’acronimo per Light Amplification by Stimulated Emission of Radiation.
Da queste caratteristiche proviene il fatto che il laser è una sorgente praticamente quasimonocromatica e quasirettilinea (nel senso che il fascio non si allarga come avviene con i fanali dell’automobile e rimane pressoché rettilineo; in realtà è un fascio la cui divergenza si può controllare molto bene ed è detto fascio gaussiano). E il meccanismo di emissione stimolata di radiazione luminosa del mezzo attivo fa sì che le onde siano anche in fase per cui il laser si dice costituire una sorgente di radiazione coerente: i fotoni vengono emessi in fase come un’orchestra d’archi in cui gli archetti si muovono su e giù tutti insieme.
Tra gli effetti che caratterizzano una sorgente coerente rispetto alla luce di una lampadina o di un normale LED, citiamo la brillanza (il fatto che anche se molto sottile il fascio ha una grande intensità) e il rumore di puntinatura (speckle noise) che è quel riflesso di piccolissimi puntini brillanti dovuti all’interferenza di onde coerenti che raggiungono i nostri occhi quando un fascio laser colpisce un corpo come un muro o i granelli di polvere nell’aria.
Fig. 4: Speckle Noise o rumore di puntinatura
Tecnica del mode locking e impulsi di durata dei femtosecondi
Gli impulsi si ottengono facendo funzionare il laser in modo intermittente. Questa tecnica consente la produzione di treni di impulsi ultrabrevi, cioè della durata dell’ordine del pico o del femtosecondo. Durate cosı̀ brevi sono molto al di là delle possibilità dell’elettronica convenzionale per produrre commutazioni del guadagno o delle perdite nella cavità, che sono altre due tra le tecniche per ottenere laser impulsati.
Un laser normalmente oscilla su diversi modi longitudinali le cui frequenze sono separate da una spaziatura tipica del risuonatore di Fabry-Perot:
\nu_F = \frac{1}{T_F} = \frac{c}{2d}
d essendo la distanza tra gli specchi del risuonatore, T_F il periodo di attraversamento della luce della distanza complessiva avanti e indietro della cavità, quindi 2d.
Pensate che questo è esattamente il modo con il quale si determina anche la frequenza a cui oscilla una corda di chitarra: più corta la corda, più alto il suono (nel senso della frequenza, non del volume).
Questi modi di solito oscillano indipendentemente, ma per mezzo di un intervento esterno è possibile introdurre un accoppiamento, agganciando le fasi dei singoli modi.
In generale la sovrapposizione di N modi di frequenza multipla della frequenza centrale ν0 :
\nu_q = \nu_0 + q \nu_F \;\;\;(1)
(con q numero intero: non usiamo i soliti indici i, j, h, k perché sono simboli che in questo contesto hanno tutti un significato particolare) dà origine ad un campo:
dove i fattori A_q sono dei numeri complessi che caratterizzano il modulo e la fase di ogni modo, z è l’ascissa misurata lungo l’asse della cavità risonante.
Il modulo |A_q| è funzione della curva di guadagno del mezzo e delle perdite, mentre la fase arg A_q è casuale, a meno che non interveniamo per agganciare queste fasi tra di loro
Supponendo che i moduli dei modi siano tutti uguali e in fase, si ottiene, usando la (1) e raccogliendo l’esponenziale con \nu_0 :
L’intensità è rappresentata, in funzione del tempo, nella fig. 2 in cui si vede il treno di impulsi e anche quanto essi possano essere resi brevi. Questa durata nei laser reali può arrivare anche a 10 fs. La spaziatura temporale tra gli impulsi è T_F = 2d/c mentre la durata di un impulso è pari a T_F/N. Quindi agganciando un gran numero di modi (N → ∞) si può rendere questa durata dell’impulso molto piccola.
Fig. 5 – Treno d’impulsi risultanti dalla sovrapposizione di modi con fase agganciata (elaborazione mia)
Quando ho studiato queste cose, la necessità di produrre impulsi ultrabrevi e molto intensi era quella di scatenare un fenomeno che si chiama Spontaneous Parametric Down-Conversion (SPDC) che consiste nel creare in un cristallo un’onda secondaria in aggiunta a quella incidente sfruttando la non linearità del cristallo, che corrisponde alla creazione di due fotoni entangled che servono per gli esperimenti di misura della violazione della diseguaglianza di Bell. Per questo esperimento erano necessari tre laser in cascata:
un laser a semiconduttore che emette sulla lunghezza d’onda di 808 nm (viola), il quale pompa
un laser a neodimio Nd-YAG (a 4 livelli) che emette sulla lunghezza d’onda 1064 nm, del quale si seleziona la seconda armonica (532 nm), con la quale si pompa
un laser Titanio-zaffiro Ti3+:Al2O3 che viene fatto funzionare in mode locking nuovamente sulla lunghezza d’onda di 808 nm
e solo con la potenza raggiunta dal terzo stadio si poteva generare il fenomeno dell’SPDC nella lamina di cristallo birifrangente (ad esempio un cristallo di calcite come quello di Figura 6).
Un cristallo birifrangente di calcite (Wikimedia commons: APN MJM)
I laser a femtosecondo trovano oggi grande impiego in chirurgia oftalmica grazie alla loro versatilità e controllo di precisione sulla dimensione dello spot (il diametro del fascio che colpisce il tessuto) e sulla quantità di energia (che è il prodotto della potenza per il tempo) necessaria per colpire i tessuti. È il bisturi più preciso mai realizzato e può operare sulla retina senza la necessità di aprire il bulbo oculare.
Sempre più difficile: generare impulsi di durata dell’attosecondo
La generazione di impulsi così brevi è realizzata unendo due tecniche:
la generazione di armoniche di ordine elevato (HHG, High Harmonics Generation) e
l’aggancio di fase già visto (mode locking).
In questa tecnologia viene costruito un laser con un mezzo attivo gassoso in cui la lampada di pompa è un altro laser che in questo caso produce treni di impulsi a femtosecondo: l’interazione di questi impulsi giganti con il mezzo attivo provoca la generazione di armoniche di ordine elevato, i cui ordini più alti vanno da decine a mille volte la frequenza centrale. La larghezza di questa banda – così ampia – è il trucco per poter generare impulsi brevi, per un teorema di Analisi Matematica che dimostra che più breve è un impulso, più è ampia la banda di frequenze del suo spettro (matematicamente, della sua trasformata di Fourier).
Ma come è generato questo impulso elementare? Ogni singolo impulso è generato dagli elettroni che una volta espulsi dall’atomo grazie al laser di pompa, vengono ricatturati dagli atomi del mezzo attivo. Essendo questo salto di energia (dallo stato libero allo stato legato) particolarmente grande, i fotoni emessi alla ricattura hanno una frequenza molto alta, dell’ordine dei raggi X (quindi molto sopra i laser a ultravioletti che abbiamo visto).
Questi impulsi (burst) ad attosecondi vengono quindi agganciati in fase in una regione spettrale sufficientemente ampia. Questo consente di ottenere impulsi giganti di durata dell’attosecondo.
Ci sono altri modi di ottenere impulsi dell’ordine dell’attosecondo diversi dalla tecnica HHG e un esempio è l’impiego di laser a elettroni liberi.
Come si può vedere queste invenzioni presuppongono una sempre più profonda conoscenza del modo in cui la materia si comporta.
Come vengono usati gli impulsi ad attosecondo?
Con un calcolo neanche troppo complicato si può calcolare che il tempo di transizione di un elettrone tra uno stato fondamentale ad uno stato eccitato è dell’ordine degli attosecondi. Quindi generatori di impulsi di attosecondi si prestano ad osservare con un risoluzione temporale senza precedenti le evoluzioni degli elettroni, sia durante una transizione energetica in un atomo, come detto, ma anche in situazioni più generali, come il ruolo del movimento elettronico negli stati eccitati molecolari (ad esempio nei processi di trasferimento di carica) oppure ancora il comportamento degli stati elettronici legati (detti eccitoni) nei materiali 2D come il grafene.
Ad esempio questo video è la ricostruzione 3D del “respiro” dell’atomo di idrogeno al rallentatore, un processo in cui lo stato dell’atomo oscilla tra l’orbitale 1s e l’orbitale 2p che dura qualche centinaio di attosecondi, reso possibile dagli snapshot presi con la tecnica degli impulsi ultrabrevi.
(Source: Wikimedia Commons)
Bibliografia
B.E.A. Saleh, M.C. Teich, Fundamentals of Photonics, Second Edition 2007 Wiley Interscience.
V V Strelkov, V T Platonenko, A F Sterzhantov and M Yu Ryabikin, Attosecond electromagnetic pulses: generation, measurement, and application. Generation of high-order harmonics of an intense laser field for attosecond pulse production (2016) IOP Science.
G. Chui, A Potential New and Easy Way to Make Attosecond Laser Pulses: Focus a Laser on Ordinary Glass, (2017) SLAC National Accelerator Laboratory
Ho preso parte alla visita guidata dei laboratori dell’INFN di Legnaro (Padova), organizzata dalla Fondazione Ingegneri di Padova che si è svolta martedì 11 luglio 2023 ed è stata un’occasione per mettere il naso in alcune delle macchine che mi hanno sempre affascinato: gli acceleratori di particelle.
Ho avuto, in passato, l’occasione per vedere da vicino macchine simili, anche se di dimensioni molto, ma molto maggiori, nelle due visite che ho fatto al CERN di Ginevra nel 1993 e nel 2018 (in cui ho visto, rispettivamente, il LEP e l’LHC).
Qui non solo le dimensioni sono più contenute ma sono anche diversi la tipologia e gli scopi di queste macchine. Tuttavia per me il continuo raffronto tra queste due realtà è risultato inevitabile.
Ad illustrare le attività e la strumentazione dei laboratori sono stati tre tecnici, l’ing. Stefania Canella e i dott. Giorgio Keppel e Oscar Azzolini, scienziati dei materiali.
Il progetto SPES
Come ha detto nella presentazione il dott. Keppel, i LNL sono un’azienda che eroga un prodotto: fasci di ioni stabili che sono a disposizione 24/7 per chiunque abbia interesse a testare strumenti, macchine o a effettuare studi nell’ambito della fisica nucleare. L’ambito di applicazione è dunque la fisica dei nuclei e le energie prodotte da questi fasci raggiungono al massimo 1.5 GeV, uno scenario di applicazioni completamente diverso da quello del CERN, dove si accede a scale di distanza molto più piccole, con energie molto più elevate.
La facility che abbiamo visitato prende il nome di SPES (Selective Production of Exotic Species) e si occupa di produrre fasci di ioni a diverse energie per diversi tipi di applicazioni, dall’ingegneria dei materiali alla medicina nucleare. Questa facility è fondata sull’utilizzo di alcune macchine acceleratrici. Con il gruppo a cui mi sono aggregato ne ho viste due.
Acceleratori
Gli acceleratori presenti ai LNL sono di tipo lineare (LINAC), ne abbiamo visitati due:
l’acceleratore di ioni TANDEM basato su un generatore elettrostatico di Van de Graaf
l’acceleratore di ioni ALPI (Acceleratore Lineare Per Ioni) basato sugli acceleratori lineari a radio frequenza.
Esiste anche un acceleratore circolare, il Cyclotron B70, che però accelera protoni (come il CERN). Questo non è stato oggetto della visita (almeno non del mio gruppo).
Ripassino
Gli acceleratori di particelle sono macchine che accelerano particelle 🙂 Il moto rettilineo uniformemente accelerato di particelle cariche si imprime con i campi elettrici. Infatti una carica q immersa in un campo elettrostatico di intensità \mathbf{E} subisce una forza pari a \mathbf{F} = q\mathbf{E} e, se m è la sua massa, subirà l’accelerazione \mathbf{a} = q/m\mathbf{E} . Supponendo che il campo sia omogeneo e uniforme diretto in una sola direzione, se d è la distanza tra due elettrodi che si trovano sottoposti ad una differenza di potenziale V, l’energia acquisita dalla carica nel percorrere questa distanza sarà pari a qV. L’unità di misura sarebbe joule, ma quando si ha a che fare con cariche piccolissime, dell’ordine della carica di un elettrone (circa 1,6 \cdot 10^{-19}C), è più comodo esprimerla in elettron volt eV: l’energia che acquista un elettrone sottoposto alla ddp di 1 V.
Non si accelerano linearmente particelle cariche con i campi magnetici ma si può tuttavia imprimere loro con questi campi un’accelerazione centripeta e far compiere loro traiettorie circolari (o curvilinee in generale, nel caso di campi non uniformi), in virtù della forza di Lorentz\mathbf{F}_L = q\mathbf{v} \times \mathbf{B} , dove \mathbf{v} è la velocità relativa al campo magnetico \mathbf{B} (gli ingegneri preferiscono chiamarlo induzione magnetica).
Generatore di Van de Graaf
Il generatore di Van de Graaff è un accumulatore elettrostatico, una macchina che trasporta particelle cariche per mezzo di una cinghia rotativa, che preleva per frizione cariche da un elettrodo e le trasporta in un altro elettrodo dove vengono accumulate, creando tra questi due elettrodi un campo elettrico. Se l’intensità del campo elettrico supera il valore di 30 kV/cm si possono vedere le scariche dovute alla rottura del dielettrico (l’aria).
Schema di funzionamento del generatore di Van de Graaff. (Wikimedia)
Storicamente gli accumulatori elettrostatici si sono diffusi nel XVIII secolo come macchine per divertimento. Erano molto popolari gli scherzi del bacio di Venere o della scossa sulle posate da tavola. Si era imparato a strofinare una superfice di vetro con un panno di lana e appoggiare questo panno su una superficie metallica. Sembrava che un misterioso fluido si depositasse sull’elettrodo. Ben presto vennero costruiti dei dischi rotanti di vetro con un dispositivo che lo strofinava portava la carica su un elettrodo metallico. Si tratta della macchina di Wimhurst e questo è uno degli esemplari esposti al Museo Giovanni Poleni di Padova.
Macchina di Wimhurst (foto mia)
Acceleratore TANDEM
Il TANDEM è stato prodotto a metà anni 80 negli USA dall’azienda fondata dallo stesso Robert Van de Graaff (USA, 1901-1967), la High Voltage Engineering Corporation, e installato presso i LNL.
Il suo funzionamento è fondamentalmente basato su un generatore di Van de Graaff.
Acceleratore Lineare TANDEM di HVEC (foto mia)
Questo acceleratore (chiamato affettuosamente Moby Dick per la sua stazza e per il colore – era bianco e nel corso del tempo è diventato grigio) oltre al nastro e gli elettrodi del generatore di Van de Graaff, è costituito da una colonna coassiale immersa in un sarcofago (che è quello che si vede nell’immagine). Il sarcofago è riempito di esafluoruro di zolfo (SF6, un gas serra per cui viene rigorosamente sigillato) in pressione a 7 bar; all’interno della colonna che costituisce una gabbia di Faraday corre la tubazione a vuoto contenente il fascio, che viene accelerato dal campo elettrico creato dal generatore.
Colonna all’interno del sarcofago (foto mia)
Degli ioni debolmente carichi negativamente (-e), provenienti da una fornace, si affacciano al tubo dell’acceleratore e vengono accelerati con una tensione di 14,5 MV; a metà colonna gli ioni incontrano loro il lungo percorso un sottile foglio di carbonio (stripper) che strappa alcuni elettroni per cui gli ioni, ora carichi positivamente, si affacciano alla seconda metà del tubo dove però incontrano un campo elettrico inverso che li accelera ancor più nella stessa direzione con una forza moltiplicata per il numero di carica. Alla fine dell’acceleratore l’energia del fascio è distribuita su uno spettro piuttosto ampio in quanto la carica degli ioni può andare da -e a -20e, ma è molto superiore all’energia che hanno a metà strada (>> 14,5 MeV).
Generatore di Van de Graaff (foto mia)
Distribuzione del fascio e circuito del vuoto
Il fascio viene poi diretto lungo una conduttura in cui è praticato un vuoto spinto (10^{-10}\textrm{ bar}).
Il vuoto è necessario per non compreomettere la qualità direzionale de fascio e per non perdere energia in collisioni inutili con particelle e molecole residue. Il grado di vuoto dipende dalla purezza che si vuole raggiungere nella produzione e trasporto del fascio. Vuoti così spinti si realizzano con tecniche criogeniche più che con l’utilizzo di pompe.
L’impianto del vuoto riguarda tutta la linea di accelerazione e distribuzione ed è controllato da dispositivi elettronici dedicati.
distribuzione degli ioni accelerati che escono da TANDEM (foto mia)
Focusing (focheggiamento) del fascio
Il fascio tende a divergere dalla direzione desiderata per cui occorre ricomporlo con due coppie di magneti (quadrupolo) che agiscono in due direzioni ortogonali tra loro e a loro volta ortogonali alla direzione del fascio, per consentire la convergenza.
Quadrupolo focalizzatore di fascio (foto mia)
Bending (curvatura) e selezione dei fasci
Alla fine della stanza un magnete curva il fascio per indirizzarlo verso la camera degli esperimenti,
Bender: curva il fascio di ioni (foto mia)
dove un ulteriore spettrometro di massa devia i fasci in base alla massa verso target prestabiliti.
Spettrometro di massa (devia gli ioni con un raggio di curvatura diverso a seconda del rapporto carica/massa) (foto mia)
Il fascio prodotto da TANDEM viene poi utilizzato direttamente negli esperimenti e in parte viene deviato come fascio di ingresso per l’acceleratore ALPI.
Acceleratore ALPI
L’acceleratore ALPI (Acceleratore Lineare Per Ioni) è molto più complesso e sfrutta una diversa tecnica di accelerazione che è quella delle cavità a superconduttore a radiofrequenza.
Acceleratori a RF
Sono degli array di cavità (drift tubes) in cui vengono iniettati degli ioni iso numero di carica, i quali vengono accelerati da un campo elettrico alternato. Questo tipo di cavità che illustro adesso è detta a mezz’onda e tra breve vediamo perché. Supponiamo che entri uno ione negativo nel primo tubo lungo la direzione +\hat{\mathbf{e}}_x; il campo abbia verso contrario alla direzione dello ione: essendo questo negativo, esso verrà ulteriormente accelerato:
La semionda deve mantenersi negativa per tutto il tempo impiegato dalla carica ad attraversare il tubo. Alla fine lo ione accelerato entra nel secondo tubo che prima aveva una tensione positiva, adesso ce l’ha negativa e il campo è ancora accelerante e così via. Ogni tubo è interessato da una semionda, nel senso che lo ione si trova accelerato per tutta la lunghezza dalla stessa semionda del segnale, da cui il nome “cavità a mezz’onda”. Siccome il tempo di percorrenza diminuisce nel secondo tubo, questo dovrà essere leggermente più lungo del precedente. Per velocità relativistiche questa differenza tra un tubo e il successivo tende a zero, ma per gli esperimenti in LNL la velocità v è tale che il fattore \beta = v^2/c^2 è in genere < 1.
Principio di funzionamento degli acceleratori lineari a radiofrequenza (immagine dalle dispense della prof. Valdata, unipg.it)
Le cavità acceleranti sono costruite in rame purissimo e vengono fatte funzionare a bassisima temperatura per consentire alle pareti interne delle cavita, che sono ricoperte di niobio (Nb), di funzionare in regime di superconduzione. Per questo motivo le cavità risonanti sono immerse in un criostato che consente al Niobio di lavorare ad una temperatura di 4,0 K che è al disotto del sua sua temperatura critica ( o di transizione) che è pari a 9,2 K.
Il regime di superconduttività consente di far funzionare i magneti senza dissipazione di potenza e di ottenere campi più intensi. Il surplus di energia necessario per far funzionare i criostati dà comunque luogo ad un consumo energetico inferiore rispetto al funzionamento a temperatura ambiente. Questa tecnica è usata anche per i magneti del CERN di Ginevra.
La forma delle cavità è come quella di figura
Cavità RF (foto mia)
L’interno di quelle ampolle è ricoperto di niobio. In realtà la forma dei moduli è diversa, si tratta di cilindri che lungo un asse orizzontale, ortogonale all’asse del cilindro consentono il passaggio del fascio e lungo l’asse del cilindro consentono l’applicazione del campo elettrico, quindi il passaggio degli elettrodi:
Modulo di cavità RF (foto mia)
Il cilindro contiene l’ellissoide e il foro trasversale (nella parte inferiore) per far passare il fascio ed è coassiale all’asse di rotazione dell’elissoide. Il foro coassiale con il cilindro invece serve per applicare il campo elettrico. Anche il funzionamento elettrico è leggermente diverso perché funzionano a quarto d’onda, perciò vengono detti QWR (Quarter Wave Resonator). In pratica il campo è postivo per due moduli e l’intensità massima del campo elettrico si ha nella transizione tra un modulo e il successivo.
Viene formato un array di 4 cavità immerse in bagno criostatico di elio liquido e ciascuno con una frequenza di lavoro progressivamente crescente: il primo gruppo lavora a 80 MHz, l’ultimo a 160 MHz (altro modo duale di configurare le cavità: invece di farle più lunghe le fanno lavorare ad una frequenza maggiore).
ALPI è un array di molti di questi moduli e lo scopo è di portare l’energia degli ioni uscenti a 1,4 GeV.
ALPI riceve il fascio da TANDEM, lungo la pipe mostrata in questo video in cui si vede la pipe fuoriuscire dal muro provenendo da TANDEM e attraversare lo stabilimento con tre focalizzatori di fascio e immettersi nell’edificio in cemento armato all’interno del quale è costruito ALPI:
Pipe da TANDEM al linac ALPI (Video mio)
ma riceve fascio anche da un altro acceleratore di nome PIAVE (hanno scelto tutti nomi nostrani, ma l’acronimo è Positive Ion Accelerator for VEry low velocity ions).
Tuning di ALPI
L’ing. Canella ha sottolineato il fatto che questa macchina è molto complessa da mettere in funzione. Le operazioni di fine tuning iniziali sono lunghe e laboriose e necessitano di un know how eccezionale. Accendere ALPI può richedere due settimane di lavoro, uno dei task più lunghi è proprio la sintonizzazione delle cavità risonanti: si parte con una cavità alla volta e si deve raggiungere un accordo ottimale di tutta la catena per massimizzare l’energia finale del fascio di ioni. Il pieno funzionamento viene supervisionato in remoto dalle sale di controllo tramite una complessa rerte di dispositivi di acquisizione e attuatori e la rete informatica che consente il controllo.
Software di controllo della facility SPES (foto mia)
Il software viene sviluppato in parte all’interno dei laboratori, ma molta parte è già disponibile dai fornitori dell’hardware di controllo.
Sicurezza degli impianti
Quando le macchine sono in funzione la radioattività è a livello di attenzione e tutti gli operatori devono trovarsi all’esterno della fascia di sicurezza (i muri perimetrali in cemento armato dei locali che ospitano le macchine sono spessi quasi due metri). La messa in funzione delle macchine segue un dettagliato e rigoroso piano di sicurezza che si avvale di procedure di ronda atte a verificare che tutto il personale sia fuori dall’area operativa e di attuatori e sensori che assicurano che i cancelli siano chiusi e il personale fuori dall’area interressata da radiazioni prima dell’accensione.
Impiego degli acceleratori
Gli acceleratori del progetto SPES vengono impiegati in campi di spettro veramente amplissimo, ne cito solo alcuni:
raccolta di radionuclidi per imaging diagnostico (PET) e terapia oncologica
generazione di neutroni per impieghi di ingegneria dei materiali
Al corso di Complementi di Elettronica Applicata, un corso del quinto anno tenuto dal prof. Gaetano Malesani, forse era il 1992, oltre a studiare tante belle cose come le PLL o gli alimentatori switching, il prof. Malesani dispensava perle di saggezza tipo “Non pensate che quando lavorerete ci sarà qualcuno ad insegnarvi ciò che dovete fare. Chi sa i trucchi del mestiere o non ha tempo o non ha voglia di spiegarveli e/o di documentarli e soprattutto se li tiene per sé”. È stata esattamente la mia esperienza, non in tutti i casi, ma in buona parte sì.
Al corso, poi, era rischiesta l’elaborazione di un progetto, nel nostro gruppetto di amici avevamo in mente di costruire un barcode scanner, ti ricordi Mario se eravamo in gruppo assieme? Forse ti eri già laureato. C’era anche Adriano “il Fufi” che mi chiamava “ingegnere dea Nasa”. Avevo anche preso contatti con la Datalogic di Calderara di Reno (c’è ancora) spiegando cosa ci apprestavamo a fare, per avere eventuale assistenza.
Senonché il prof ad un certo punto ci dice: “Ragazzi, siete troppi gruppi e il laboratorio è limitato, dobbiamo aggregarvi”.
Praticamente i nuovi accoliti non vollero saperne di un progetto così ambizioso, bisognava fare il meno possibile per passare l’esame. Dopo un po’ che non trovavamo un accordo, Malesani ci dice: “Allora ve lo assegno io il progetto: perché non costruite un oscillatore a ponte di Wien?” e ci diede delle specifiche assurde per quanto riguarda campo di frequenza coperto e distorsione armonica. Eravamo, noi del gruppetto inziale, abbstanza delusi, ci sembrava un ribasso notevole sulle nostre aspettative. Ma lui lesse lo sconforto nei nostri volti e aggiunse: “Non pensate che si tratti di una punizione: Hewlett e Packard hanno iniziato così, costruendo oscillatori a ponte di Wien, circuiti che emettevano fischi terrificanti, per un cliente di tutto rispetto: la Walt Disney”.
Alle fine ci siamo inventati una retroazione dell’oscillatore con un JFET, tipo i VCO che si usano nei sintetizzatori analogici, che rendeva il sistema performante ad una gamma di frequenze ancora più grande e con un distorsione armonica molto al disotto del limite imposto.
Poi alla fine scrissi da solo buona parte della relazione soffermandomi in modo particolare sull’analisi della retroazione e scoprii, spiegandola all’esame, che avevo impiegato senza accorgermene il metodo della funzione descrittiva che stavo studiando per la tesi sul caos deterministico. Ho preso 30 quella volta ed era sotto Natale.
La primava dopo, ricordo bene ero a piedi lungo il Piovego, un paio di studenti che facevano parte del gruppo e che non si erano mai fatti vedere, mi prendono in disparte e mi dicono “Ma chi cazzo ha scritto la relazione? non si capisce niente c’è solo un’analisi inutile della retroazione!”. Ho risposto che per me era la cosa più interessante del lavoro. E ho capito già allora come si fa a fare strada nel mondo del lavoro: usare i lavoro degli altri, prendersene gli eventuali meriti e sparare merda su chi ha lavorato.
È stato di sicuro il corso in cui ho imparato più cose, grazie prof. Malesani!
Mi sono trovato con due versione di Skype, una installata con apt e l’altra con snap. Non ricordavo di avere fatto questa cosa, probabilmente ho installato la seconda perché era comparso l’avviso che da quella versione era supportato ChatGPT.
In ogni caso ho deciso di eliminare la più obsoleta, quella installata con apt, che era alla versione 8.98 e il cui eseguibile era sotto /usr/share/skypeforlinux/.
Con una lista dei processi ho visto i due programmi che girano indipendentemente:
Visualizzando le rispettive versioni dalle due GUI, vedo che una è la 8.98 e una è la 8.99 ma non so quale di quei due processi corrisponda alla 8.98. Quindi chiudo la versione più vecchia e l’unico processo che sopravvive è il 10694, e la correlazione è fatta.
Come detto, la versione più vecchia l’ho installata con apt, la più recente con snap. Comunque dal programma di disinstallazione è possibile specificare la versione da rimuovere:
$ sudo apt remove skypeforlinux=8.98*
[sudo] password di marcob:
Lettura elenco dei pacchetti... Fatto
Generazione albero delle dipendenze... Fatto
Lettura informazioni sullo stato... Fatto
Versione "8.98.0.402" (. stable:stable [amd64]) selezionata per "skypeforlinux"
I seguenti pacchetti saranno RIMOSSI:
skypeforlinux
0 aggiornati, 0 installati, 1 da rimuovere e 23 non aggiornati.
Dopo quest'operazione, verranno liberati 330 MB di spazio su disco.
Continuare? [S/n] S
(Lettura del database... 529434 file e directory attualmente installati.)
Rimozione di skypeforlinux (8.98.0.402)...
...
$
Utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Lo facciamo per migliorare l'esperienza di navigazione e per mostrare annunci personalizzati. Il consenso a queste tecnologie ci consentirà di elaborare dati quali il comportamento di navigazione o gli ID univoci su questo sito. Il mancato consenso o la revoca del consenso possono influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.

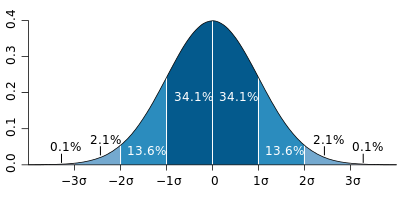
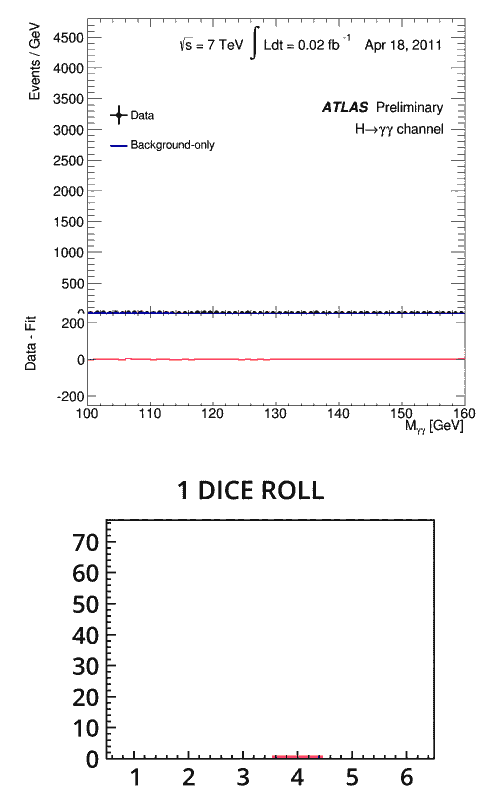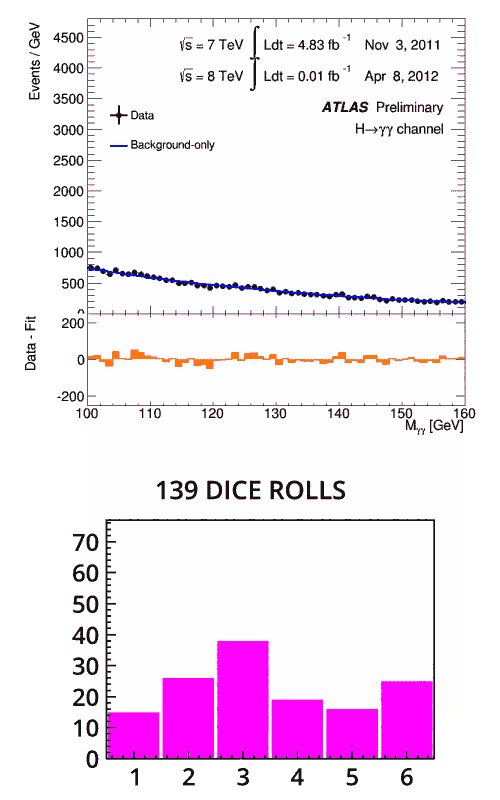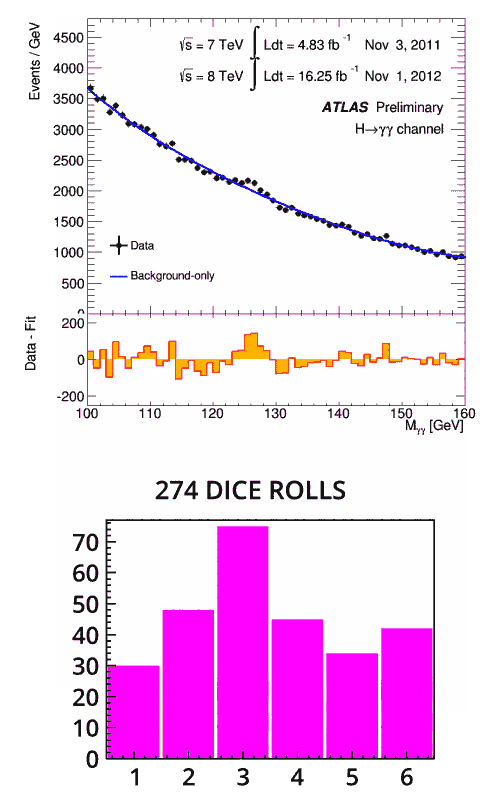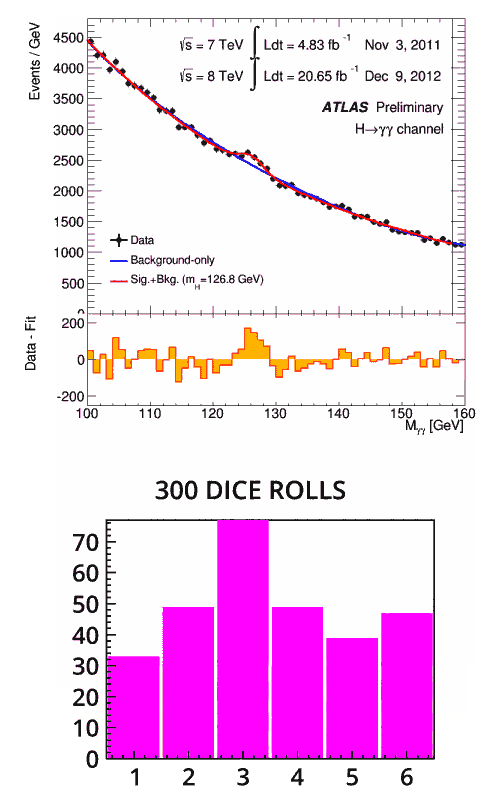

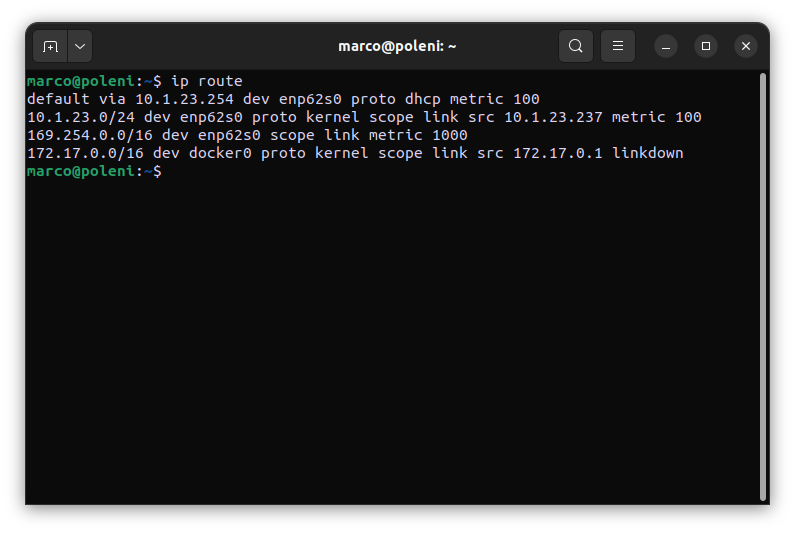


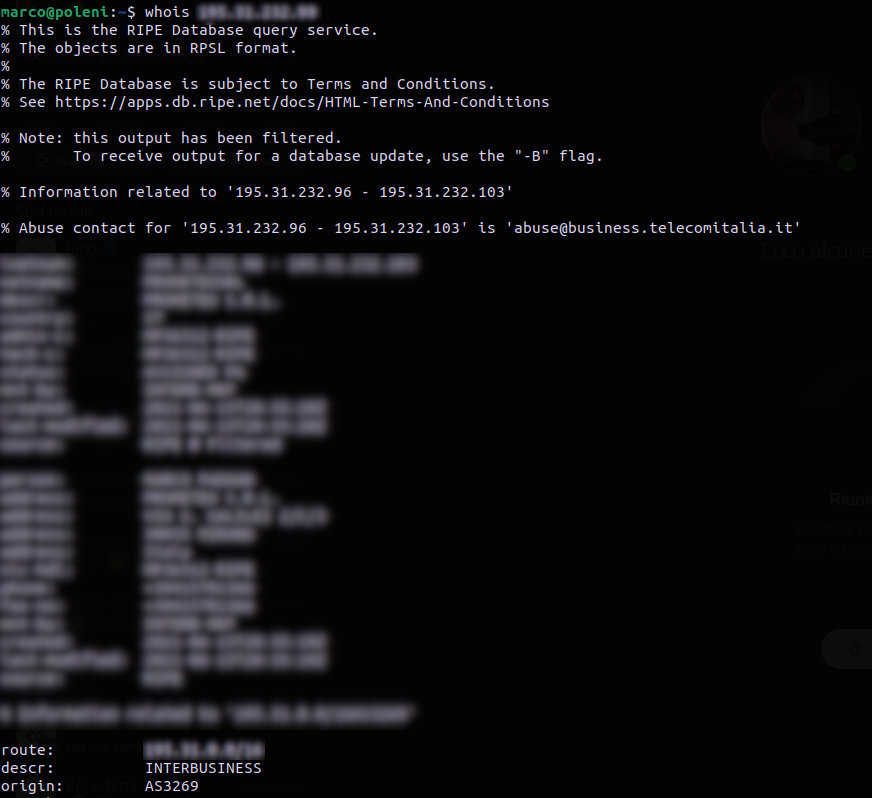
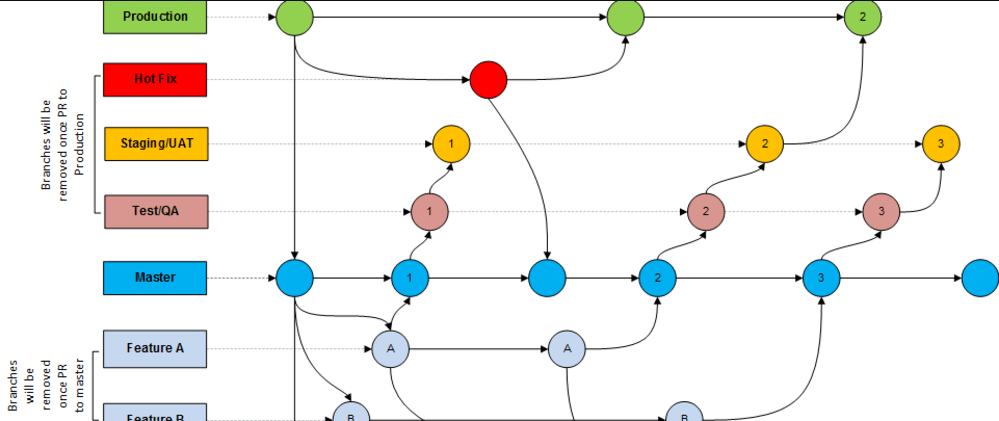


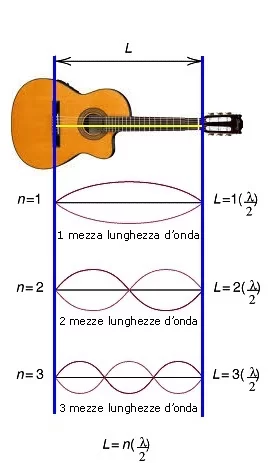

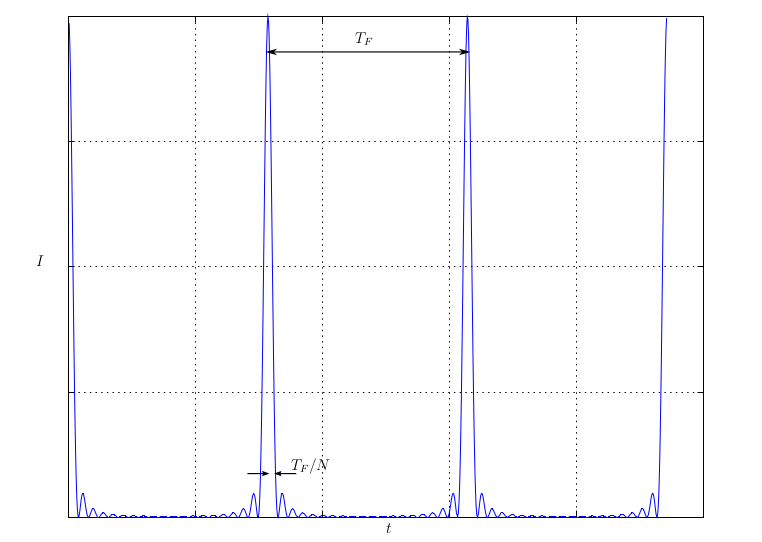

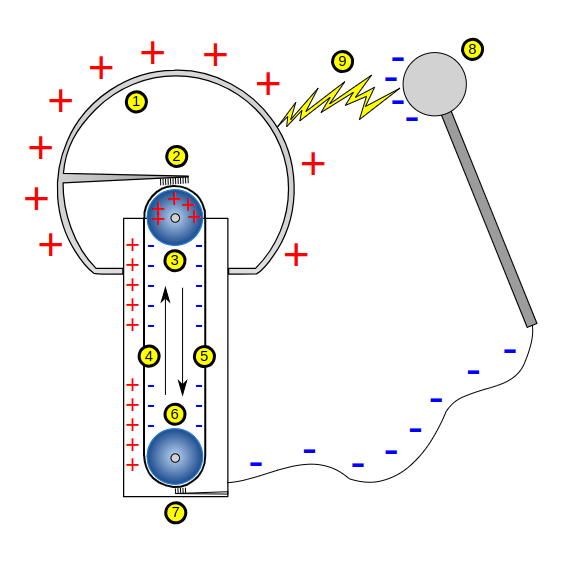













Commenti recenti