

Ho organizzato una visita al CERN di Ginevra venerdì 19 gennaio 2024, per l’Associazione Amici dello Zuccante di cui faccio parte, come ideale prosecuzione di una serie di appuntamenti dedicati alla Fisica.
L’anno scorso abbiamo visitato in due sessioni il Museo di Storia della Fisica Giovanni Poleni, dell’Università di Padova.
Quest’anno, nel periodo di stop per la manutenzione annuale, tutti i maggiori esperimenti erano aperti alle visite del pubblico e l’esperimento CMS (Compact Muon Solenoid) era quello che ci dava una maggiore disponibilità di posti. Ho sentito anche ALICE e ATLAS ma consentivano l’accesso solo a gruppi più esigui.
La visita si è articolata in più incontri: una visita tecnica all’esperimento CMS e una conversazione con la dott.ssa Barbara Rusconi, Financial Controller al CERN, che mi ha spiegato alcuni aspetti del finanziamento delle ricerche e dell’accesso all’istituzione. La visita del CERN si è conclusa al Science Gateway, un nuovo spazio dedicato alle esposizioni, alla didattica e alle conferenze.
La nostra guida all’esperimento CMS, un fisico e informatico che ha lavorato qui diversi anni durante il suo post-dottorato, il dott. Simone Bologna, ci ha illustrato l’esperimento assieme agli aspetti di computer science (che interessano parecchi noi che lavorano nell’informatica e/o l’hanno insegnata) e ha condotto la visita a CMS, spiegandoci più in dettaglio la struttura dell’esperimento.
LHC
Il Large Hadron Collider è un cosiddetto anello di accumulazione, o acceleratore, una infrastruttura che serve a spingere fasci di particelle quasi alla velocità della luce per essere poi impiegati in esperimenti di collisione, collisioni che avvengono fuori dall’anello, all’interno di macchine molto complesse dette detectors o rivelatori. Un rivelatore all’incirca coincide con un esperimento. CMS è uno di questi.
Point 5
Il sito al di sotto del quale si trova in profondità il detector CMS (denominato Point 5, vicino al paese di Cessy, Francia) ha una storia sbalorditiva. Gli scavi iniziarono, dopo l’approvazione del progetto da parte del CERN, nel 1999 e subirono immediatamente un colpo d’arresto: fu infatti rinvenuta dagli escavatori una casa di epoca romana, completa di vasellame, piastrelle e monete, che richiese un po’ di tempo agli archeologi per lo studio, la repertazione e la traslazione in altra area.
Dopodiché lo scavo subì un secondo arresto: ad un certo punto i carotaggi davano la presenza di una falda acquifera, un vero e proprio fiume sotterraneo che si rivelò profondo da 10 a 20 metri.

Per poter proseguire con lo scavo, la squadra ha dovuto prima congelare il terreno attorno ai due pozzi (si vedono nella foto: dovevano ospitare il pozzo per calare le apparecchiature e l’ascensore) per fungere da barriera per l’acqua. Praticando poi dei fori attorno alla circonferenza di ciascun albero e pompando la salamoia, raffreddata a -25°C, l’acqua si congelò andando a costituire una parete di ghiaccio di 3 metri. Ma l’acqua proveniente da Cessy si muoveva più velocemente del previsto e, in combinazione con l’effetto di incanalamento dell’acqua tra i due pozzi, la pressione aumentò fino a penetrare nelle pareti.
Si cominciò quindi a iniettare nei fori una sostanza ancora più fredda: l’azoto liquido, a una temperatura inferiore a -195°C, tecnica che finalmente risolse il problema. Con l’impiego dell’azoto liquido gli ingegneri formarono un muro di ghiaccio attorno ai pozzi che era sufficientemente solido da consentire alle squadre di continuare a perforare il terreno per continuare l’escavo del pozzo.
I problemi non erano finiti: la destinazione finale del sarcofago dell’esperimento si trovava in un volume di terriccio friabile (molassa) nel quale non era possibile costruire una caverna.
Poiché anche l’ambiente a 100 metri sotto la superficie è pieno d’acqua, le fasi finali hanno riguardato l’impermeabilizzazione, l’installazione di sistemi di drenaggio e la verniciatura della caverna, poiché altrimenti l’acqua potrebbe trasformare la roccia tenera in fango. “Una volta che tutto era a posto, abbiamo potuto sigillare la caverna con l’impermeabilizzazione e inserire un muro permanente di cemento spesso fino a 4 metri, rinforzato con barre d’acciaio” spiega John Osborne, project manager di ingegneria civile CMS. [11]
Questo racconto illustra quanto fondamentale sia l’ingegneria civile in questo tipo di realizzazioni. Indubbiamente… standing ovation per le imprese e le maestranze che hanno realizzato tutto questo!
Compact Muon Solenoid
L’esperimento CMS si trova 100 metri sotto il paese di Cessy (Francia): lo abbiamo raggiunto con un pullman privato per riuscire a minimizzare (e di parecchio) i tempi di percorrenza dalla reception Building 33 di Meyrin (Svizzera), dove c’è anche il Science Gateway di cui vi parlerò più avanti.

Molto brevemente, i detector o rivelatori sono macchine molto complesse all’interno delle quali vengono fatti scontrare frontalmente gruppi (bunch) di protoni e vengono seguite le traiettorie della miriade di particelle che si generano. I bunch provengono da due tubi sotto vuoto che circolano lungo la circonferenza di LHC, nei quali sono stati accelerati in direzioni opposte fino a portarli ad una velocità molto prossima alla velocità della luce (precisamente, il 99,999997 % di c).
Quindi immaginate un infrastruttura, l’acceleratore vero e proprio o anello di accumulazione che è LHC dal quale, on demand l’esperimento preleva due o più bunch in direzioni opposte per essere scontrati dentro al detector. LHC non fa circolare solo protoni. A volte (e l’utilizzatore principale ne è l’esperimento ATLAS) fa circolare ioni di piombo, ideali per produrre li cosiddetto plasma quark-gluone.
Sono le moderne evoluzioni dei primi detector: le camere a nebbia o a bolle; rispetto a queste, essi consentono una maggiore precisione nella misura e l’archiviazione digitale dei parametri che descrivono questi fenomeni (traiettorie, rapporto carica/massa, energia).
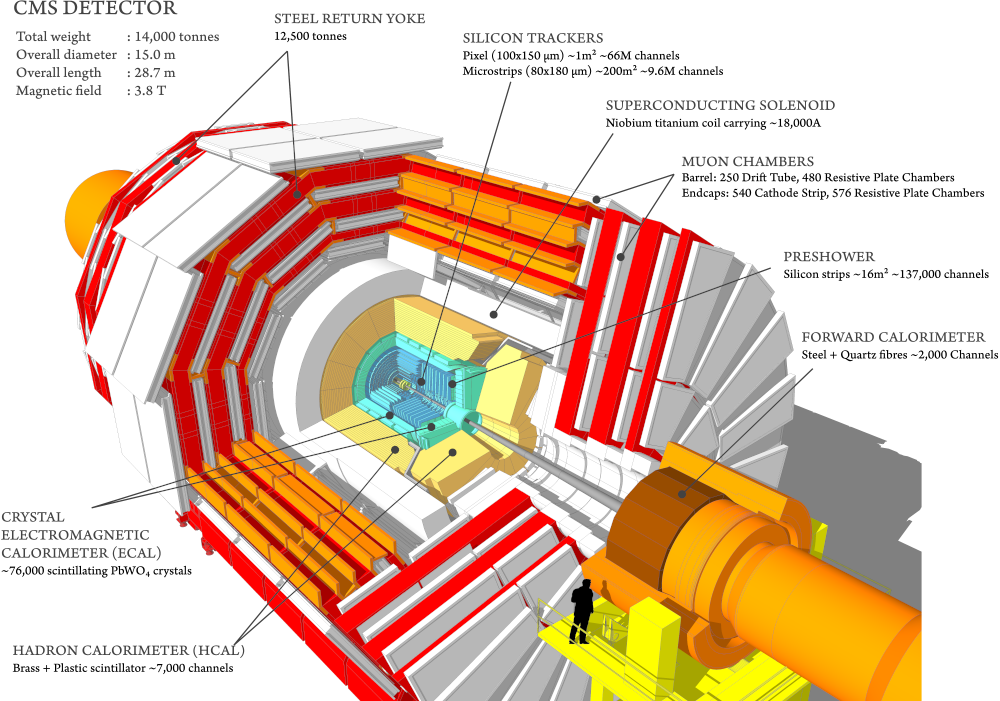
Il rivelatore CMS non è il più grande dei quattro esperimenti maggiori di LHC (con ALICE, ATLAS e LHCb) ma sicuramente il più massiccio (da qui l’aggettivo: Compact), con le sue 14000 T (quasi il doppio della Tour Eiffel), un concentrato di tecnologia con i suoi componenti: tracker, calorimetri EM, calorimetri adronici, magnete solenoidale superconduttore e il calorimetro muonico.
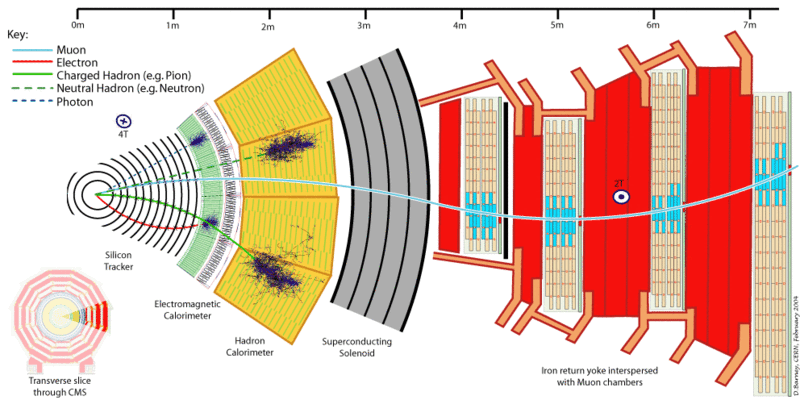
In sostanza il tubicino centrale che porta la corrente di protoni è la sede della collisione (qui dovete immaginare che questo tubo esca dallo schermo – è una sezione trasversale dell’esperimento); spostandoci via via radialmente verso l’esterno abbiamo
- il tracker che è una pila di lamine al silicio, disposte attorno alla camera di collisione, analoghe ai CCD delle fotocamere: questo device consente di ricostruire esattamente (con una precisione di qualche micron) le traiettorie delle particelle EM che possono essere cariche (nel qual caso viene misurato il rapporto q/m) oppure neutre (fotoni);
- i due calorimetri che si incontrando proseguendo verso l’esterno: il calorimetro EM che misura l’energia di elettroni e fotoni e il calorimetro adronico (barioni e mesoni). Va da sé che misurare l’energia di una particella equivale a misurarne la massa.
- Il solenoide superconduttore che genera il campo magnetico di 4 Tesla necessario a incurvare le particelle cariche;
- Nella parte esterna del rivelatore, il cosiddetto “giogo di ritorno” (return yoke) del magnete, che confina il campo magnetico e ferma tutte le particelle rimanenti tranne muoni e neutrini, sono collocate le cosiddette camere muoniche all’interno delle quali si misurano le masse dei muoni (i “cugini” massicci degli elettroni). Questa disposizione, oltre a trovarsi in senso radiale, viene ripetuta in senso longitudinale, secondo l’asse del cilindro, perché durante la collisione le particelle vanno dappertutto, anche parallelamente all’asse del detector.
C’è da dire che così da vicino si ha la misura della complessità di questa macchina, che è terrificante.
Nella prossima foto si vede uno spaccato del rivelatore (che era aperto per manutenzione) in cui si possono notare a destra (in quel grande tubo centrale con rastremazione conica verso sinistra) i calorimetri interni e sulla sinistra (attorno al foro circolare) il solenoide e le camere muoniche radiali:

[Foto: Gemma Zuin]
Una visione spaccata in prospettiva è la seguente (che potete trovare anche nel sito di CMS), nella quale sono indicati precisamente i componenti che ho appena elencato:
CMS Data Collection
I dati da cui si ricavano le traiettorie delle particelle prodotte dall’urto vengono elaborati con un primo livello di filtro (detto trigger) che è lo strato software che si occupa della selezione degli eventi che interessa studiare.
Tuttavia non tutte le particelle prodotte da queste collisioni sono interessanti per cui viene fatta una selezione iniziale per potersi concentrare sulle collisioni “buone”. I protoni che non partecipano alla collisione vengono tuttavia rivelati ma solo per tenere sotto controllo il valore della sezione d’urto [2].
In una pagina della sezione di Fisica mostrerò qual è l’ordine di grandezza del numero di collisioni che realmente hanno luogo quando i bunch di protoni si scontrano.

Quando l’LHC fa collidere i protoni, CMS rileva circa 40 di milioni di collisioni ogni secondo, solo una manciata delle quali sono utili per gli studi di fisica. Gli scontri tra protoni non sono tutti centrali, molti avvengono di striscio, producono poche particelle, magari le meno interessanti per ciò che si sta cercando: per esempio, eventi come quelli che hanno segnalato la presenza del bosone di Higgs, per esempio, sono estremamente rari. Se si dovessero salvare tutti i dati prodotti, si dovrebbe disporre di 40 Petabyte di capacità disco ogni secondo. Un po’ troppo!
Il compito del Trigger CMS è selezionare solo le poche centinaia di migliaia di eventi utili scartando il resto.
Trigger di I livello (L1T)
Il primo livello del trigger a due fasi, noto come trigger di livello 1 (o L1T), seleziona un massimo di centomila eventi al secondo dei quali puoi viene eseguita una seconda selezione più dettagliata da parte del secondo livello, noto come trigger di alto livello. [8]
Pertanto questa selezione, che richiede tempi di elaborazione velocissimi, può essere eseguita solo da dispositivi FPGA che consentono velocità di elaborazione non raggiungibili con i processori tradizionali
Il sistema L1T è progettato per raccogliere le informazioni dai calorimetri CMS e dagli spettrometri per muoni, è un sistema completamente sincronizzato montato a bordo del rivelatore stesso – per non sprecare tempo in trasmissione – che fornisce la sua decisione se mantenere il dataset acquisto o scartarlo in soli 3,8 μs dopo che si è verificata la collisione delle particelle al centro del CMS.
High-Level Trigger (LHT)
Una seconda fase di selezione accurata viene eseguita da un trigger software chiamato High-Level Trigger (HLT), che è implementato in una farm di 30.000 core che si trova in superficie. [7]
HLT, alla fine, dei 40 milioni di eventi ne salva all’incirca un migliaio.
La nostra guida Simone Bologna ha lavorato proprio alla realizzazione di questi due livelli di trigger durante il suo post-doc.

Ultime note: CMS è uno di due esprimenti del CERN (l’altro è ATLAS) che hanno annunciato a luglio 2014 la scoperta del bosone di Higgs.
Inoltre, la tecnologia creata al CERN per rivelare i muoni ha trovato applicazioni altrove: una radiografia muonica della piramide di Cheope ha consentito di individuare una stanza sconosciuta al suo interno.
L’INFN di Napoli ha avviato uno studio del sistema di bocche di cratere all’interno del Vesuvio utilizzanod sempre la tecnlogia di imaging muonica.
Come il CERN mette a disposizione la sua tecnologia per chiunque abbia una buona idea da sviluppare.
La piacevole chiacchierata con la dott.ssa Barbara Rusconi, Financial Controller and Analyst presso il Financial and Administration Processes Department del CERN mi ha fatto conoscere una persona piacevolissima, entusiasta del suo lavoro e della missione del CERN.
La sua attività prevede molti tipi di task tra i quali: aiutare i progetti a trovare finanziamenti, stendere i business plan, reperire le risorse umane e tecnologiche per poter raggiungere gli obiettivi del progetto.
E’ un lavoro molto impegnativo che richiede grande conoscenza dei meccanismi di finanziamento pubblico e privato, del tipo di attività che si svolge lì dentro e capacità di regia e di relazione.
Mi ha spiegato come il CERN si sia dato diversi compiti: quello di portare avanti una ricerca di alta qualità a livello mondiale, mettere a disposizione un set completo di macchine acceleratrici a servizio della ricerca nelle alte energie in un modo sostenibile, unire persone provenienti da tutto il mondo per ampliare le frontiere della scienza e della tecnologia, a beneficio di tutti; formare nuove generazioni di fisici, ingegneri e tecnici e coinvolgere tutti i cittadini nella ricerca e nei valori della scienza. In particolare, c’è la missione di mettere a disposizione le competenze sviluppate al suo interno in aiuto a chiunque abbia una buona idea da sviluppare: un apparato, un software, un metodo di misura.
Il CERN ha un apposito organismo che si preoccupa di trasferire le competenze CERN al mondo esterno: il Gruppo KT (Knowledge Transfer Group) il quale mira a collaborare con esperti in scienza, tecnologia e industria al fine di creare opportunità per il trasferimento della tecnologia e del know-how del CERN. L’obiettivo finale è accelerare l’innovazione e massimizzare l’impatto positivo globale del CERN sulla società. Ciò avviene promuovendo e trasferendo il capitale tecnologico e umano sviluppato al CERN.
Le possibilità di applicazione riguardano la medicina, le applicazioni aerospaziali, Industria 4.0, sicurezza, tecnologie emergenti e molto altro ancora.
Per fare partire una collaborazione si può sottoporre l’idea al KT group con una semplice mail. [9]

Arrivederci Barbara, è stato veramente un piacere incontrarti!
Il Science Gateway
Nel 2022 è stato inaugurato un nuovo spazio destinato alle esposizioni, alla divulgazione delle Fisica e agli eventi aperti al pubblico come le conferenze, che è stato chiamato Science Gateway.

Esso si dispone parallelamente all’Explanade des Particules, con i due spazi espositivi paralleli al corso e una galleria trasparente che li collega transitando sopra la strada e collega così anche i due lati del CERN.
Progettato da Renzo Piano, il nuovo complesso comprende cinque strutture cilindriche che ospitano mostre e laboratori e un auditorium da 900 posti. Ci trovate anche il ristorante Big Bang e un negozio in cui potete acquistare i souvenir.
Con piacevole sorpresa – come detto, il Science Gateway offre anche uno spazio destinato a mostre ed esposizioni d’arte – ho incontrato nuovamente questa installazione Chroma III dell’artista sudcoreano Yunchul Kim, che avevo visto nel 2022 alla Biennale di Venezia:

Le sezioni del Science Gateway comprendono anche l’Atelier Didattico, Our Universe, Quantum World.
Nella sezione Quantum world una serie di installazioni immersive (in cui ci si può aggirare) spiegano le pazzesche proprietà delle particelle elementari come la funzione d’onda, l’entanglement, la dualità onda particella, l’esperimento della doppia fenditura.
In Our Universe svengono raccontati i 13 miliardi di anni del nostro Universo e quello che di strano si porta dentro, come la Materia e l’Energia Oscura o l’asimmetria tra materia e antimateria, misteri che sono tuttora irrisolti.
Nell’Atelier didattico si può giocare ad accelerare una biglia di acciaio per mezzo di campi magnetici prodotti da bobine che possiamo comandare agendo su un pulsante, oppure si può giocare a calcio con i protoni per riuscire a scontarli e produrre particelle elementari, ciò che avviene nei detector come CMS che abbiamo visitato fino al suo interno.

Qui per esempio Gemma e io siamo riusciti a produrre una collisione, ma non è stato semplice 🙂

Tutti i partecipanti sono rimasti soddisfatti ed entusiasti della visita! Voglio anche ringraziare tutti coloro che mi hanno aiutato nell’organizzazione, con il supporto logistico.

Arrivederci alla prossima esperienza!










Commenti recenti