Mi sono imbattuto in un comportamento piuttosto curioso utilizzando DBeaver con un server MySQL locale. All’avvio di DBeaver, il tentativo di connessione falliva con il messaggio: La cosa sorprendente era che bastava aprire un terminale …
Per anni avevo sentito ripetere che Docker è una virtualizzazione leggera. È una frase comoda per iniziare, ma in realtà è fuorviante. L’ho capito nel modo migliore: cercando di capire perché MySQL si comportasse in …
Aprendo Thunderbird mi è comparso un avviso che invitava a intervenire entro il 21 luglio 2026 per continuare a ricevere gli aggiornamenti ESR (Extended Support Release). Partiamo con le istruzioni operative per chi sa già …
Negli ultimi tempi termini come LLM, embedding e database vettoriali sono usciti rapidamente dall’ambito della ricerca e sono diventati argomenti quasi quotidiani. Sono mattoncini coi quali possiamo costruire sistemi capaci di interrogare grandi collezioni di …
Ho condotto un esperimento di scrittura di software per analizzare i risultati di una esportazione delle mie conversazioni con ChatGPT. Ma ho deciso di aiutarmi nell’analisi con un Large Language Model che sicuramente sa fare molto bene questo lavoro e in più con un LLM in locale, per vedere come funziona.
Qui di seguito scrivo una breve guida passo passo per caricare su Bitbucket un repository Git e utilizzarlo come copia di riferimento nello sviluppo. Bitbucket consente di ospitare repository remoti privati con alcune limitazioni.
Git: creare il repository in locale
Come primo passaggio occorre inzializzare il repository git in locale:
Qui è neceessario individuare il nome che git ha attribuito al branch principale per poterlo replicare in remoto:
$ git branch
* master
La versione di Git che ho a bordo è
$ git --version
git version 2.30.2
Bitbucket: creare il repository in remoto
Dopodiché bisogna creare un nuovo repository su Bitbucket, un repository vuoto in cui il branch principale divrà chiamarsi master (Bitbucket da’ l’opzione di chiamare come si vuole il branch principale, ma è bene fare molta attenzione su questo punto!).
Il progetto Laravel contiene già i file Readme.md e .gitignore quindi non è necessario generarli lato Bitbucket.
In “impostazioni avanzate” della maschera di creazione del repository Bitbucket possiamo scegliere il linguaggio con cui stiamo sviluppando, i questo caso PHP.
Quindi colleghiamo il repo locale con quello remoto con il comando:
Qui si è scelto di chiare “origin” il repository remoto come si fa spesso. Ma lo possiamo chiamare come vogliamo. Ora si può sparare sù il repository:
$ git push -u origin master
Se il risultato è il seguente:
sign_and_send_pubkey: signing failed for RSA "/home/marcob/.ssh/id_rsa" from agent: agent refused operation
git@bitbucket.org: Permission denied (publickey).
fatal: Impossibile leggere dal repository remoto.
Assicurati di disporre dei privilegi d'accesso corretti
e che il repository esista.
c’è un problema con l’autenticazione con SSH. Vedere questo articolo per risolvere il problema.
In sostanza occorre avviare l’agente ssh (se lo si deve fare ogni volta, è preferibile aggiungerlo negli script di avvio di Linux).
Infatti il risultato dopo l’esportazione delle variabili di ambiente di ssh-agent è il seguente
$ git push -u origin master
Enter passphrase for key '/home/marcob/.ssh/id_rsa':
Enumerazione degli oggetti in corso: 109, fatto.
Conteggio degli oggetti in corso: 100% (109/109), fatto.
Compressione delta in corso, uso fino a 4 thread
Compressione oggetti in corso: 100% (92/92), fatto.
Scrittura degli oggetti in corso: 100% (109/109), 226.50 KiB | 4.36 MiB/s, fatto.
109 oggetti totali (7 delta), 0 riutilizzati (0 delta), 0 riutilizzati nel file pack
remote: Resolving deltas: 100% (7/7), done.
To bitbucket.org:mxaos/complex.git
* [new branch] master -> master
Branch 'master' impostato per tracciare il branch remoto 'master' da 'origin'.
La situzione in remoto ora è la seguente
Git: caricare un nuovo repository su Bitbucket da progetto locale
Ho un nuovo repository su Bitbucket. Ho generato una chiave con ssh-keygen e ho caricato la chiave pubblica su Bitbucket.
Tuttavia il comando seguente mi va in errore:
$ git pull remote master
sign_and_send_pubkey: signing failed for RSA "/home/marcob/.ssh/id_rsa" from agent: agent refused operation
git@bitbucket.org: Permission denied (publickey).
fatal: Impossibile leggere dal repository remoto.
Assicurati di disporre dei privilegi d'accesso corretti
e che il repository esista.
Il problema è che, dopo aver generato la chiave, mi sono dimenticato di aggiungerla al keyring utlizzato dall’agent ssh. Quindi è necessario lanciare questo comando:
$ ssh-add
Enter passphrase for /home/marcob/.ssh/id_rsa:
Identity added: /home/marcob/.ssh/id_rsa (marcob@jsbach)
Alla fine si può verificare che la chiave è stata aggiunta
Due parole sulla autenticazione a chiave pubblica SSH
Posso effettuare un’autenticazione su un server remoto con questi ingredienti:
Un repository locale in cui risiede una coppia di chiavi RSA (generate con l’utility ssh-keygen)
Un agente locale (ssh-agent) che gestisce le coppie RSA generate in locale
Un server in cui gira un demone OpenSSH
Un agente remoto che colloquia con l’agente locale
Inoltre, il protocollo SSH implementa l’inoltro dell’agente, un meccanismo per cui un client SSH consente a un server SSH di utilizzare l’agente ssh locale sul server a cui l’utente accede, come se fosse locale.
Quando l’utente contatta il client SSH sul server, il client tenterà di contattare l’agente implementato dal server e il server inoltra la richiesta al client che ha originariamente contattato il server, che la inoltra ulteriormente all’agente locale. In questo modo, ssh-agent e agent forwarding implementano il single sign-on che può progredire in modo transitivo.
Comunque: se oggi funziona e dopo un po’ non funziona più, è perché dev’essere riavviato l’ssh-agent.
SSH agent
ssh-agent è in sostanza un portachiavi. Un programma per contenere chiavi private usate per l’autenticazione a chiave pubblica.
Attraverso l’uso di variabili d’ambiente, l’agente può essere individuato da ssh e utilizzato automaticamente per l’autenticazione durante la registrazione in altre macchine.
L’avvio del portachiavi con inizializzazione delle variabili di ambiente viene fatta con il comando
$ eval `ssh-agent -s`
Per esempio le variabili possono assumere valori come questi:
Qui le variabili inizializzate sono due: SSH_AUTH_SOCK e SSH_AGENT_PID.
SSH può accedere al portachiavi utilizzando queste due informazioni.
Se l’agente vi chiede nuovamente la passphrase
Vuol dire che non avete aggiunto la chiave al keyring; anzi, probabilmente non è colpa vostra: lo avete fatto ma l’accesso al portachiavi è come sempre a tempo: dopo un po’ di tempo dovete riaprirlo a mano. Potete però decidere per quanto tenerlo aperto con questo comando:
$ ssh-add -t 1h30m
per esempio così rimane aperto per un’ora e mezza. Ricordatevi comunque che è bene che il portachiavi si chiuda dopo un po’.
Prima dell’apertura del portachiavi questa è la risposta del server Git da cui voglio scaricare gli aggiornamenti:
$ git pull origin master
sign_and_send_pubkey: signing failed for RSA "/home/marcob/.ssh/id_rsa" from agent: agent refused operation
git@bitbucket.org: Permission denied (publickey).
fatal: Impossibile leggere dal repository remoto.
Assicurati di disporre dei privilegi d'accesso corretti
e che il repository esista.
Quindi riapro il portachiavi:
$ eval `ssh-agent -s`
Agent pid 170012
Ora se provo a ridare il comando non avrò più l’errore ma mi verrà chesta la passphrase della mia chiave privata:
$ git pull origin master
Enter passphrase for key '/home/marcob/.ssh/id_rsa':
Se voglio anche non dover ridigitare la password, aggiungo la mia chiave privata al portachiavi (devo però digitare la passphrase almeno questa volta)
$ ssh-add
Enter passphrase for /home/marcob/.ssh/id_rsa:
Identity added: /home/marcob/.ssh/id_rsa (marcob@jsbach)
Per le successive invocazioni con il Git server remoto non mi verrà più chiesta la password (fino allo scadere del timeout del portachiavi):
$ git pull origin master
Da bitbucket.org:mxaos/logisticmapper
* branch master -> FETCH_HEAD
Già aggiornato.
Routes: credo che il modo più semplice di imparare come funziona il framework MVC Laravel sia quello di partire con le rotte. Rotte proprio come le linee ideali seguite da una nave.
Almeno questa è la mia esperienza.
Cosa sono le rotte (routes)?
Cosa sono le rotte? In inglese routes, sono gli URI (Uniform Resource Identifier), i link che vengono generati dall’applicazione, quelli che compaiono sulla barra degli indirizzi del browser:
Routes: sono gli URI nella barra degli indirizzi
Il principale URI generato dall’applicazione è la home page, nel mio esempio:
http://www.complex.local/
È un’applicazione di esempio locale per la quale ho configurato un virtual host Apache.
Per vedere come viene servita questa rotta (che in sostanza è risorsa di più alto livello, la radice e si indica con /) bisogna fare riferimento al file <APP>/routes/web.php.
Attenzione: sto usando la versione 8.73.1 di Laravel e, rispetto al passato, l’organizzazione delle cartelle è leggermente cambiata. Con <APP> intendo la cartella radice dell’applicazione (nel mio caso il nome della cartella è /complex. Al suo interno c’è tutta l’organizzazione delle cartelle di Laravel, tra cui una che si chiama /app (che non è <APP>, bensì la prima sottocartella di questa, in ordine alfabetico). Nella cartella /app c’è la maggior parte del materiale che utilizzeremo (i model e i controller per esempio). Un’altra cartella importante è la cartella /database dove troveremo tutte le migrazioni. Infine , nella cartella /resources/views ci sono le viste e, nella separata cartella /routes, le rotte.
Ebbene, ecco il contenuto del file <APP>/routes/web.php:
<?php
use Illuminate\Support\Facades\Route;
/*
|--------------------------------------------------------------------------
| Web Routes
|--------------------------------------------------------------------------
|
| Here is where you can register web routes for your application. These
| routes are loaded by the RouteServiceProvider within a group which
| contains the "web" middleware group. Now create something great!
|
*/
Route::get('/', function () {
return view('welcome');
});
Questo programma utilizza la classe di Laravel Route e in particolare il suo metodo get(), che è definito con una closure che non è altro che una funzione definita sul posto, detta più propriamente funzione anonima perché è senza nome. Questa closure ritorna la funzione view() a cui passo l’argomento 'welcome'.
Nota: view() è una funzione, non un metodo. Infatti non è definita all’interno di una classe ma all’interno di un file, helpers.php, situato sotto <APP>/vendor/laravel/framework/src/Illuminate/Foundation.
Il primo importante parametro del metodo get() è proprio la rotta da servire. In questo caso la ‘/’, la home page.
Il secondo parametro altrettanto importante è cosa deve fare Laravel quando dal browser arriva la richiesta di servire la rotta indicata. In questo caso ciò che deve fare Laravel è scritto dentro alla closure, e deve ritornare la view di nome ‘welcome’.
Cos’è questa view 'welcome'? È un file PHP scritto in Blade che si trova sotto <APP>/resources/views/welcome.blade.php. Quindi ogni volta che di decide il nome di una nuova view deve essere necessariamente associata ad un nuovo file all’interno della cartella <APP>/resources/views/.
Per esempio, se dobbiamo servire una rotta return view('edit'); ci dovrà essere un form HTML scritto dentro al file <APP>/resources/views/edit.blade.php.
Quindi in generale:
Route::get([URL], function () {
return view([view file name]);
});
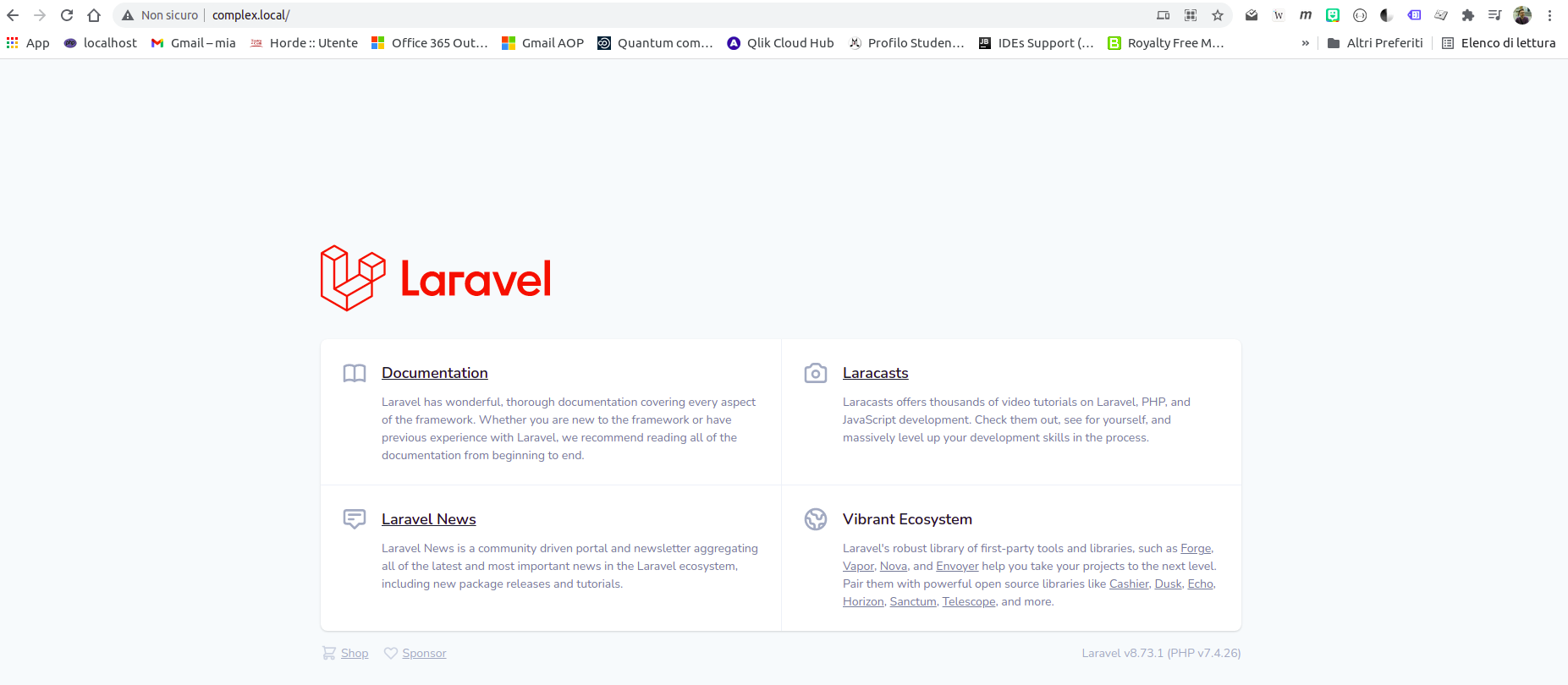
Ora, la view di home generata automaticamente da Laravel è piuttosto complessa:
laravel 8.73.1 standard home
Facciamone una più semplice:
$ cd resources/views/
$ cp welcome.blade.php welcome.blade.ORIG.php
e modifichiamo a piacere l’orginale (welcome.blade.php):
Ho lasciato un po’ di “codice” html/css per fare vedere lo scheletro della pagina, come vengono caricati gli stili, come si usa il linguaggio di templatingBlade (es. str_replace()) – per vedere come si possano iniettare piccoli frammenti di codice per automatizzare la pagina – e Bootstrap con la definizione delle classi.
Ma proprio il minimo indispensabile.
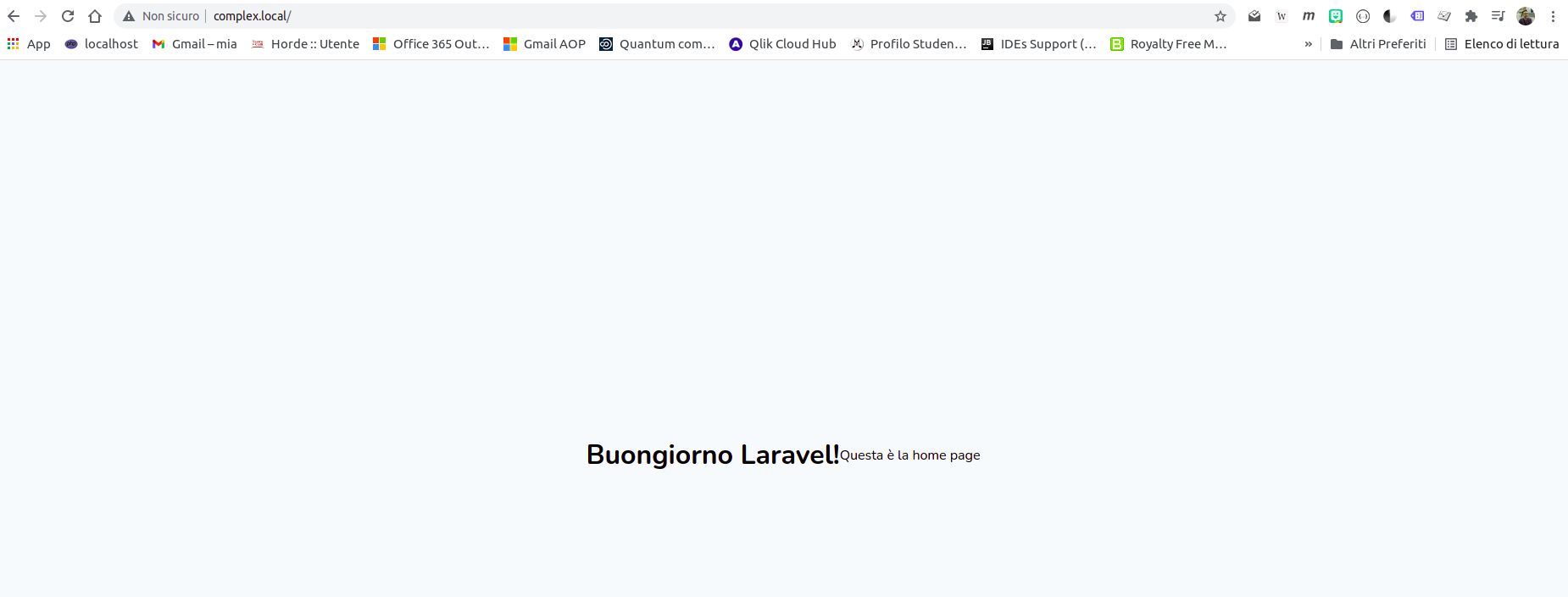
Il cuore della view è:
<h1>Buongiorno Laravel!</h1>
<p>Questa è la home page</p>
Il risultato è un po’ deludente ma siamo risuciti a servire la nostra prima rotta
laravel home modificata
Routes: il metodo statico Route::get()
Ho glissato su un aspetto tecnico piuttosto importante, il frammento di programma che chiama la view è scritto così:
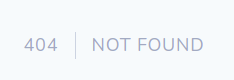
Se non definisco una rotta, non la posso chiamare dal browser. Per esempio se provo ad invocare
http://www.complex.local/esempio
il risultato è un errore 404
Route errore 404
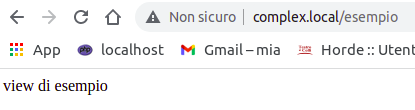
Se però definisco la rotta:
Route::get('/esempio', function () {
return 'view di esempio';
});
la vista che appare è la seguente
Route: view di esempio
Possiamo anche passare parametri nell’URL e intercettarli all’interno dei nostri programmi per farne ciò che vogliamo. Ad esempio se definiamo questa rotta nel file /routes/web.php:
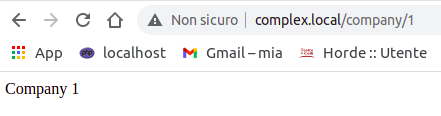
Route::get('/company/{id}', function ($id) {
return 'Company '.$id;
});
Otteniamo
Route per passare un parametro
Posso passare anche più parametri nel modo seguente (attenzione all’ordine in cui li scrivo e li nomino!):
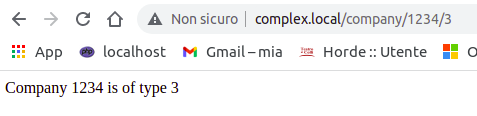
Route::get('/company/{id}/{type_id}', function ($id, $type_id) {
return 'Company '.$id. ' is of type '.$type_id;
});
Il risultato è il seguente
Route per passare più parametri
Questo esempio che segue illustra la possibilità di dare un nome, una etichetta, ad una rotta.
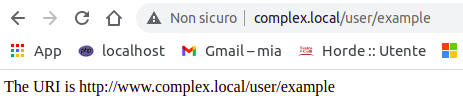
Route::get('/user/example', array('as' => 'user.home', function() {
$uri = route('user.home');
print 'The URI is '.$uri;
}));
Il risultato è questo che per ora ci dice poco:
Route name
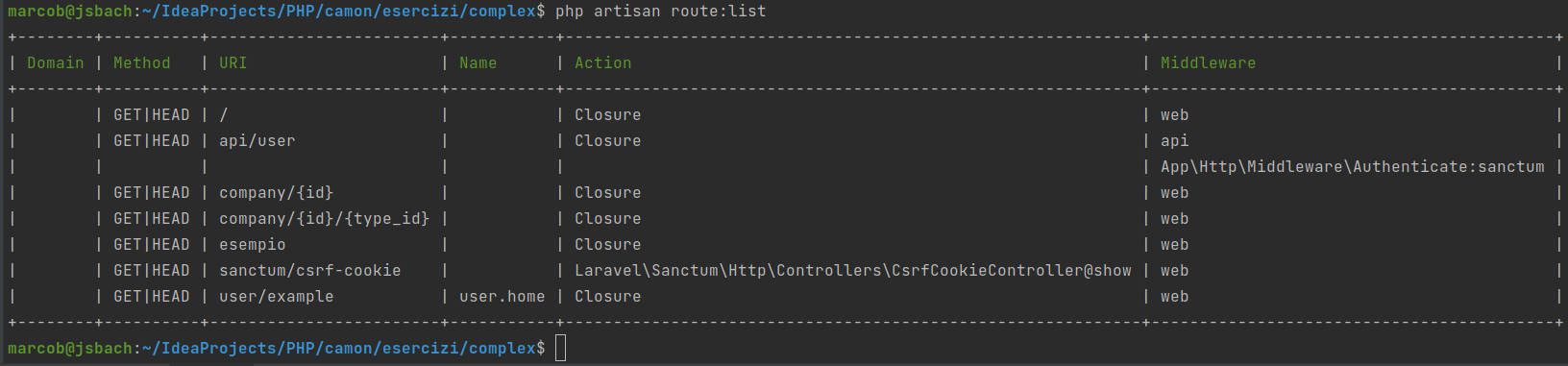
Tutte le rotte che definiamo le possiamo tenere sotto controllo con artisan:
Route: lista delle rotte
L’ultima lista dell’elenco è quella a cui abbiamo anche attriibuto un nome. In pratica lo potremo usare così:
<a href="route('user.home')">User home</a>
e laravel ci porterà a http://www.complex.local/user/example.
Ricordatevi di fare in modo che apache possa scrivere il file <APP>/storage/logs/laravel.log:
$ sudo chmod 777 storage/logs/laravel.log
[sudo] password di marcob:
$
o risulterà un errore.
Ulteriori modi di utilizzare le rotte è chiamando i metodi di un controller invece di una funzione anonima. Ma lo vediamo la prossima puntata.
Laravel primi passi: ispirandomi alle lezioni di Edwin Diaz ripropongo qui un approccio smooth.
Laravel è un framework per applicazioni scritte PHP che implementa un’architettura MVC.
Framework sta per infrastruttura software fatta di file, classi, metodi e proprietà, che aiutano a sviluppare un’applicazione.
È in se stessa un’applicazione, ma sapendola configurare e personalizzare, con essa possiamo fare ciò vogliamo.
Molte operazioni saranno quasi gratis, come le operazioni su un database, ma occorrerà comunque scrivere parecchio per realizzare ciò che vogliamo. Il fatto è che utiizzando il framework siamo costretti a sviluppare in modo ordinato e coerente e possiamo tenere sotto controllo gli errori, testare il software e documentarlo.
Un altro aspetto positivo dell’adozione di un paradigma MVC standard è che potrai essere affiancato da altri programmatori che non dovranno imparare come tu scrivi il software, che è il peggior problema quando si mettono le mani in codice scritto da altri: ognuno ha il suo stile e si fa il suo piccolo framework.
Anche qui ci sarà una curva di apprendimento ma lo standard è molto più robusto, scalabile, testato e documentato del piccolo framework personale
Laravel: architettura MVC
L’arhitettura MVC è un design pattern, cioè un paradigma progettuale, un modo di progettare, in cui il funzionamento di un software viene pensato come composto da tre componenti:
M per Model: il modello è la rappresentazione dei dati all’interno dell’applicazione. I dati risiedono in un database ma, nel contesto di una programmmazione ad oggetti, anche loro all’interno del software, devono venire rappresentati come degli oggetti del linguaggio che si sta usando. Per questo il modello in sostanza è implementato da un’architettura che si chiama ORM, Object Relationship Manager, ed è la parte di Laravel che si occupa di interagire con il database, come dice il nome, mappando il database sugli oggetti PHP. Nella stragrande maggioranza dei casi si può dire che ad ogni tabella del database corrisponde una classe del modello. ORM ce ne sono tanti, ogni linguaggio ha il suo. Per esempio un ORM di Java è Hibernate. L’ORM di PHP adottato da Laravel si chiama Eloquent. Con Eloquent possiamo fare le più semplici interrogazioni e query con join senza ricorrere alla scrittura diretta di istruzioni SQL. Possiamo anche creare e distruggere oggetti database senza ricorre al DDL (il Data Definition Language, per intederci le istruzioni di tipo CREATE TABLE) del DBMS . È comunque abbastanza flessibile da consentire anche di scrivere direttamente in SQL query troppo complicate rimanendo nel framework.
V per View: è la parte visuale dell’applicazione, l’html prodotto dall’applicazione e la gestione dell’interazione con il browser. Il fatto che l’interfaccia debba essere sollevata da interazioni dirette con il database dovrebbe essere chiara a chiunque abbia sperimentato un po’ di programazione old style che mescolava dentro ogni singola pagina: HTML, CSS, PHP, SQL, Javascript… Un vero incubo! Anche per le view esistono plugin per semplificare ulteriormente la produzione: per esempio il framework Blade consente di progettare pagine che acquisiscono dati dal Model attraverso il Controller e fanno operazioni di tipo ciclo o test o semplicemente output delle variabili nell’HTML. Utilizzando anche il tool HTML/CSS Bootstrap possiamo progettare in modo rapido e responsive le nostre pagine senza impazzire con il CSS al cambiare della UI.
C per Controller: devo dire che per me è stato il componente più difficile da imparare ma quando ho capito cos’è, si è semplificato tutto di brutto. Viene definito come il man in the middle, e un po’ di verità c’è. Ma la sostanza è che il controller è l’applicazione. È in assoluto la parte più importante del pattern MVC, quella in cui scarichiamo la maggior parte della nostra creatività. Ciò che vogliamo che l’applicazione faccia, lo definiamo nel controller. È il regista che prende gli attori (model) e li fa recitare nelle scene del set (view). Quindi la maggior parte del codice che scriveremo sarà dentro al controller.
In questo articolo su Laravel popoleremo le tabelle di dati di test con il celebre plugin Faker: creeremo dapprima due tabelle database con una relazione 1 a molti con le migrazioni di Laravel, creeremo il model che le rappresenta, il Controller che le gestisce e le .
Creazione delle migrazioni
Creiamo le migrazioni due migrazioni per queste tabelle collegate da una relazione 1 a molti:
Diagramma E/R per utilizzare Faker
Utilizziamo il comando make:model che ci consente di fare tutto in un colpo: creare la tabella, il model, il controller, e le factory per poter poplare con dati di test le tabelle.
Convenzione: creiamo il modello con il nome al singolare. Eloquent creerà la tabella con il nome al plurale, il Controller con il nome del model, le factories con il nome del model.
Laravel gestisce correttamente anche il fatto che Company è un plurale irregolare nella lingua inglese 🙂
$ php artisan make:model Company -mfscr
Model created successfully.
Factory created successfully.
Created Migration: 2021_11_24_182740_create_companies_table
Seeder created successfully.
Controller created successfully.
Questo comando crea:
un model (m) vuoto di nome Company;
una factory (f) vuota di nome CompanyFactory che ci servirà per definire i tipi di dati di test associare ai record della tabella;
una migrazione con la creazionedella tabella companies;
un seeder (s) per riempire di dati la tabella
un controller (c) di nome CompanyController
un resource (r) che popola il Controller con metodi standard CRUD (index(), create(), show(), edit(), update() e destroy())
Personalizzazione della migrazione
Dobbiamo definire come sarà la tabella:
class CreateCompaniesTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('companies', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->string('website');
$table->string('email')->unique();
$table->float('latitude');
$table->float('longitude');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('companies');
}
}
Facciamo lo stesso per CompanyType:
$ php artisan make:model CompanyType -mfscr
Model created successfully.
Factory created successfully.
Created Migration: 2021_11_24_183431_create_company_types_table
Seeder created successfully.
Controller created successfully.
Sono stati creati i model, i controller con i 4 metodi standard, i factory.
Per ultimo lanciamo il seeder che popola di dati la tabella Company Types. Lo facciamo rispettando la prirità che per rispettare la relazione di chiave esterna ci porta a popolare prima la tabella madre (company_types) e poi la figlia (companies).
Occorre dapprima scrivere cosa vogliamo che faccia il Seeder.
Per CompanyType definiamo innazitutto la factory (che definisce come devono essere popolati i campi)
<?php
// <APP>/database/factories/CompanyTypeFactory.php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
class CompanyTypeFactory extends Factory
{
/**
* Define the model's default state.
*
* @return array
*/
public function definition()
{
return [
'name' => $this->faker->name(),
];
}
}
In questo caso abbiamo unsolo campo per cui utilizziamo un metodo “name” che genererà un nome proprio di persona. Non è questo il caso, ma Faker da la possibilità di generare anche indirizzi random, numeri di telefono, url, email latitudini e longitudini e molto altro ancora.
E poi scriviamo il seeder (definiamo quanti record devono essere creati, in questo caso 3):
<?php
// <APP>/database/seeders/CompanyTypeSeeder.php
namespace Database\Seeders;
use App\Models\CompanyType;
use Illuminate\Database\Seeder;
class CompanyTypeSeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
CompanyType::factory()
->count(3)
->create();
}
}
Infine per Company specifichiamo una chiave esterna fissa a 1
<?php
// <APP>/database/seeders/CompanySeeder.php
namespace Database\Seeders;
use App\Models\Company;
use Illuminate\Database\Seeder;
class CompanySeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
Company::factory()
->count(10)
->create();
}
}
Per lanciare il comando si torna alla console e si scrive:
$ php artisan db:seed --class=CompanySeederSe
Se non specifichiamo la classe, lancerà tutti i seeder che abbiamo scritto.
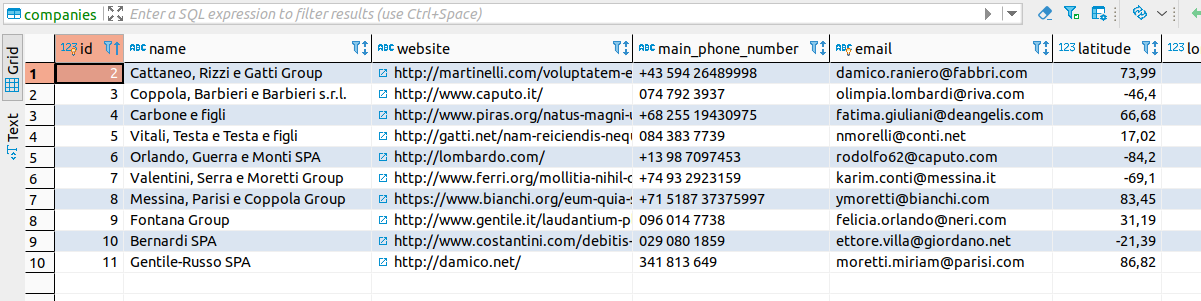
Alla fine questo è il risultato:
Come Faker popola i record della tabella companies
È possibile anche specificare una localizzazione diversa dalla standard inglese, si va nel file di configurazione dell’applicazione <APP>/config/app.php e si modifica così la linea:
Facciamo un po’ di personaggi e interpreti di questo articolo (CSRF = Cross Site Request Forgery = falsa richiesta tra siti):
la vittima: un utente che abitualmente visita e si autentica in
un sito che contiene un difetto per il quale si merita l’appellativo di sitovulnerabile.com;
un attaccante che è molto bravo e conduce
un sitomalevolo.com
Supponiamo che il servizio Web vulnerabile sia quello che consente agli utenti di modificare la loro email utilizzando solo un cookie per l’autenticazione e l’invio di un modulo.
Il sitomalevolo.com sembra innocuo ma ha al suo interno una pagina web con un programma JavaScript che invia di nascosto una richiesta al sitovulnerabile.com con una mail fasulla nel modulo e chiama semplicemente l’URL vulnerabile.
Facciamo un esempio. Il servizio del sitovulnerabile.com consente di modificare l’email dell’utente autenticato attraverso una form HTML: ebbene, l’Attaccante pubblica in sitomalevolo.com un form simile, che invia la stessa informazione al sitovulnerabile.com
Requisito 1: l’attacco avrà successo se e solo se l’utente12345 esiste,
Poi l’Attaccante siede sulla riva del fiume ad attendere che passi la vittima, ovvero l’utente che viene in qualche modo indotto a visitare il sitomalevolo.com. Per esempio l’Attaccante adesca la vittima sottoponendola a SPAM e inviandogli una mail “Grossi premi alla Lotteria Web”; all’interno di questa mail mette un link che punta alla form sopra. Inoltre la form è auto inviante quindi la vittima il sito malevolo non lo vede neanche passare (può farlo se apre gli strumenti per sviluppatori Alt+Shift+I e controlla la scheda Network).
Requisito 2: la vittima dev’essersi precedentemente autenticata sul sito vulnerabile, per poter consegnare al sitovulnerabile.com, quando ritorna dopo l’hop nel sito malevolo, il cookie di sessione.
La richiesta quindi parte dal browser della vittima che attualmente era atterrato sul sito malevolo e invoca il sito vulnerabile chiamando la API di cambio mail e passandogli l’id_utente e il cookie di sessione.
Queste informazioni sono sufficienti a far sì che il sito vulnerabile aggiorni davvero la mail a insaputa dell’utente. Il danno può emergere anche dopo molto tempo, quando l’utente cercherà di entrare nuovamente nel sito vulnerabile (sarebbe meglio dire, a questo punto, sito vulnerato) ma questo gli risponde “User not known”.
Rimedio
Occorre aggiungere una terza informazione che certifica qual è l’origine del dato.
Laravel genera automaticamente un “token” CSRF per ogni sessione utente attiva gestita dall’applicazione. Questo token viene utilizzato per verificare che l’utente autenticato sia la persona che effettua effettivamente le richieste all’applicazione. Poiché questo token è archiviato nella sessione dell’utente e cambia ogni volta che la sessione viene rigenerata, un’applicazione dannosa non è in grado di accedervi.
È possibile accedere al token CSRF della sessione corrente tramite la sessione della richiesta o tramite l’helper csrf_token:
use Illuminate\Http\Request;
Route::get('/token', function (Request $request) {
$token = $request->session()->token();
$token = csrf_token();
// ...
});
L’attaccante non può utilizzare questo metodo perché non gli ritornerebbe alcunché visto che non è autenticato (non ha e non avrà mai il cookie di sessione che invece è nel browser della vittima). E dovrebbe farlo per poter inserire nella form il valore del _csrf.
Ogni volta, infatti, che definisci un modulo HTML “POST”, “PUT”, “PATCH” o “DELETE” nella tua applicazione, dovresti includere un campo CSRF _token nascosto nel modulo in modo che il middleware di protezione CSRF possa convalidare la richiesta. Per comodità, puoi utilizzare la direttiva Blade @csrf per generare il campo di input del token nascosto:
Il middleware App\Http\Middleware\VerifyCsrfToken, incluso per impostazione predefinita nel gruppo middleware Web, verificherà automaticamente che il token nell’input della richiesta corrisponda al token archiviato nella sessione. Quando questi due token corrispondono, sappiamo che l’utente autenticato è quello che ha avviato la richiesta.
In questo articolo porto un esempio di test con Laravel.
Laravel consente di eseguire due tipi di test: Unit per piccoli test su singole funzioni del controller o del model. Feature per testare intere funzionalità dell’applicativo dalla richesta HTTP alla produzione dell’output.
Laravel crea i test in due directory:
<APP>/tests/Feature
<APP>/test/Unit
Per creare un test (di defult si va sulle Features):
$ php artisan make:test UserTest [--unit]
Aggiungiamo --unit solo se vogliamo fare un test di unità (per un singolo metodo per esempio). Il nome del test possiamo sceglierlo come vogliamo, basta che ci ricordi cosa fa. Il nome finisce sempre per “Test”.
Faccio girare i test
$ php artisan test
PASS Tests\Unit\ExampleTest
✓ example
PASS Tests\Feature\ComplexTest
✓ example
PASS Tests\Feature\ExampleTest
✓ example
Tests: 3 passed
Time: 0.16s
Infatti quando creo i test la prima volta, lui aggiunge già un file tests/Feature/ExampleTest.php, io ne ho aggiunto un secondo che fa un test standard di risposta all’URL http://myapp.local/ (ho configurato il virtualhost Apache).
In questo esempio costruirò una classe per la gestione del tipo “numero complesso”, la classe Complex.
In una prima versione definisco il costruttore che crea l’oggetto Complex a partire dalla parte reale e immaginaria e poi scrivo qualche setter e qualche getter per consentire accesso e modifica alle variabili private $real e $imag:
<?php
namespace App;
use PHPUnit\Util\Exception;
class Complex
{
private float $real;
private float $imag;
private float $modulus;
private float $phase;
public function __construct($x, $y)
{
$this->setReal($x);
$this->setImag($y);
$this->setModulus();
$this->setPhase();
}
public function getReal(): float
{
return $this->real;
}
public function getImag(): float
{
return $this->imag;
}
public function getModulus(): float
{
return $this->modulus;
}
public function getPhase(): float
{
return $this->phase;
}
public function setReal($x)
{
$this->real = ($x == null) ? 0 : $x;
}
public function setImag($y)
{
$this->imag = ($y == null) ? 0 : $y;
}
E scrivo alcuni test per mettere alla prova questi medodi: lo faccio nel file <APP>/test/Feature/ComplexTest.php;
class ComplexTest extends TestCase
{
/**
* A basic feature test example.
*
* @return void
*/
public function test_example()
{
$response = $this->get('/');
$response->assertStatus(200);
}
public function test_setReal()
{
$r = 1;
$z = new Complex(null, null);
$z->setReal($r);
$x = $z->getReal();
$this->assertTrue($x == $r);
}
public function test_setImag()
{
$i = 1;
$z = new Complex(null, null);
$z->setImag($i);
$y = $z->getImag();
$this->assertTrue($y == $i);
}
Lo spirito è il seguente: provo il metodo e confronto il risultato con quello che mi aspetto che faccia. Se non lo fa c’è un problema da risolvere. Per fare questo c’è il metodo assertTrue() che testa che una condizione sia vera. Ad esempio nel metodotest_setReal() viene creato un numero complesso nullo (con parte reale e immaginaria nulle) e poi viene impostata la parte reale a 1 con setReal(). Successivamente la leggo con getReal(); mi aspetto che il risultato sia 1. Per questo utilizzo il metodo assertTrue($x == $r).
Scrivo poi i metodi che impostano il modulo e la fase (già dentro al costruttore così le ho a disposizione fin dall’inizio) e con un metodo print() stampo il numero nella rappresenzazione cartesiana z = x + i y.
Per eseguire il test, lancio da riga di comando:
$ php artisan test
PASS Tests\Unit\ExampleTest
✓ example
PASS Tests\Feature\ComplexTest
✓ example
✓ set real
✓ set imag
✓ set modulus
✓ set phase
✓ print
✓ real print
✓ imag print
✓ modulus
✓ phase
PASS Tests\Feature\ExampleTest
✓ example
Tests: 12 passed
Time: 0.14s
$
Se invece qualcosa va storto si vede un output del genere:
$ php artisan test
PASS Tests\Unit\ExampleTest
✓ example
FAIL Tests\Feature\ComplexTest
✓ example
⨯ set real
⨯ set imag
✓ set modulus
✓ set phase
✓ print
✓ real print
✓ imag print
✓ modulus
✓ phase
PASS Tests\Feature\ExampleTest
✓ example
---
• Tests\Feature\ComplexTest > set real
PHPUnit\Util\Exception
Phase undefined
at app/Complex.php:68
64▕ $res = M_PI_2;
65▕ } else if ($this->imag < 0) {
66▕ $res = - M_PI_2;
67▕ } else {
➜ 68▕ throw new Exception('Phase undefined');
69▕ }
70▕ }
71▕
72▕ return $this->phase = $res;
1 app/Complex.php:19
App\Complex::setPhase()
2 tests/Feature/ComplexTest.php:27
App\Complex::__construct()
e abbiamo tutti i dettagli per capire dove dobbiamo correggere.
Automazione dei test
Un aspetto ancora più bello di Laravel è che possiamo automatizzare i test quando vogliamo, ad esempio prima di un commit su Git.
ho incontrato anche questo fastidioso errore mentre tentavo di collegarmi al database con lo user grantato di quel database utilizzando DBeaver:
Unable to load authentication plugin 'caching_sha2_password'.
Ho trovato in un forum questa soluzione, entrando come root
$ mysql -u root -p logisticmapper mysql> ALTER USER 'logmap_user'@'localhost' IDENTIFIED WITH mysql_native_password BY 'xxxxx'; Query OK, 0 rows affected (0,02 sec)
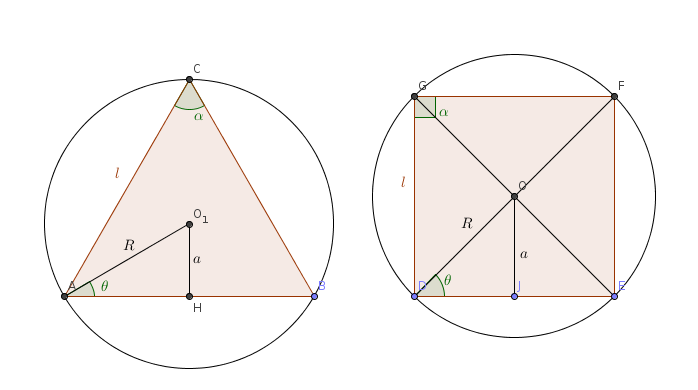
Geometria euclidea: I primi due poligoni della successione che tende al cerchio.
Da tempo immemorabile so,o credevo di sapere, il affto di geometria secondo il quale “il cerchio è un poligono con infiniti lati” ma ho sempre avuto paura, o non ho mai avuto abbastanza voglia, di dimostrarlo.
Una pulsione irresistibile mi ha preso e ho fatto sto benedetto calcolo. Sì, si può calcolare la lunghezza ella circonferenza e l’area del cerchio con un’operazione di passagio al limite.
L’articoletto è in allegato. Molto divertimento, come sempre.
Piccolo tutorial per creare una nuova applicazione Laravel senza l’uso di Docker o Sail.
Installare composer
Composer è uno strumento per la gestione delle dipendenze in PHP. Permette di dichiarare le librerie da cui dipende il tuo progetto e le gestirà per te (installazione o aggiornamento che sia).
Per esempio se utilizzi Faker per popolare di dati di prova il database della tua applicazione, compser ti solleva dal compito di installarea posteriori Faker se non c’è o di aggiornarlo se hai una versione vecchia.
Nella pagina di download c’è lo script PHP da linea di comando per installare Composer. Ovviamente dobbiamo già avere installato una versione di PHP a bordo. Io ho ancora PHP 7.4.16 (cli), mentre attualmente PHP è già alla versione 8.
Dal mio ultimo progetto PHP è passato un po’ di tempo ho questo messaggio:
$ composer create-project laravel/laravel example-app
Warning from https://packagist.org: Support for Composer 1 is deprecated and some packages will not be available. You should upgrade to Composer 2. See https://blog.packagist.com/deprecating-composer-1-support/
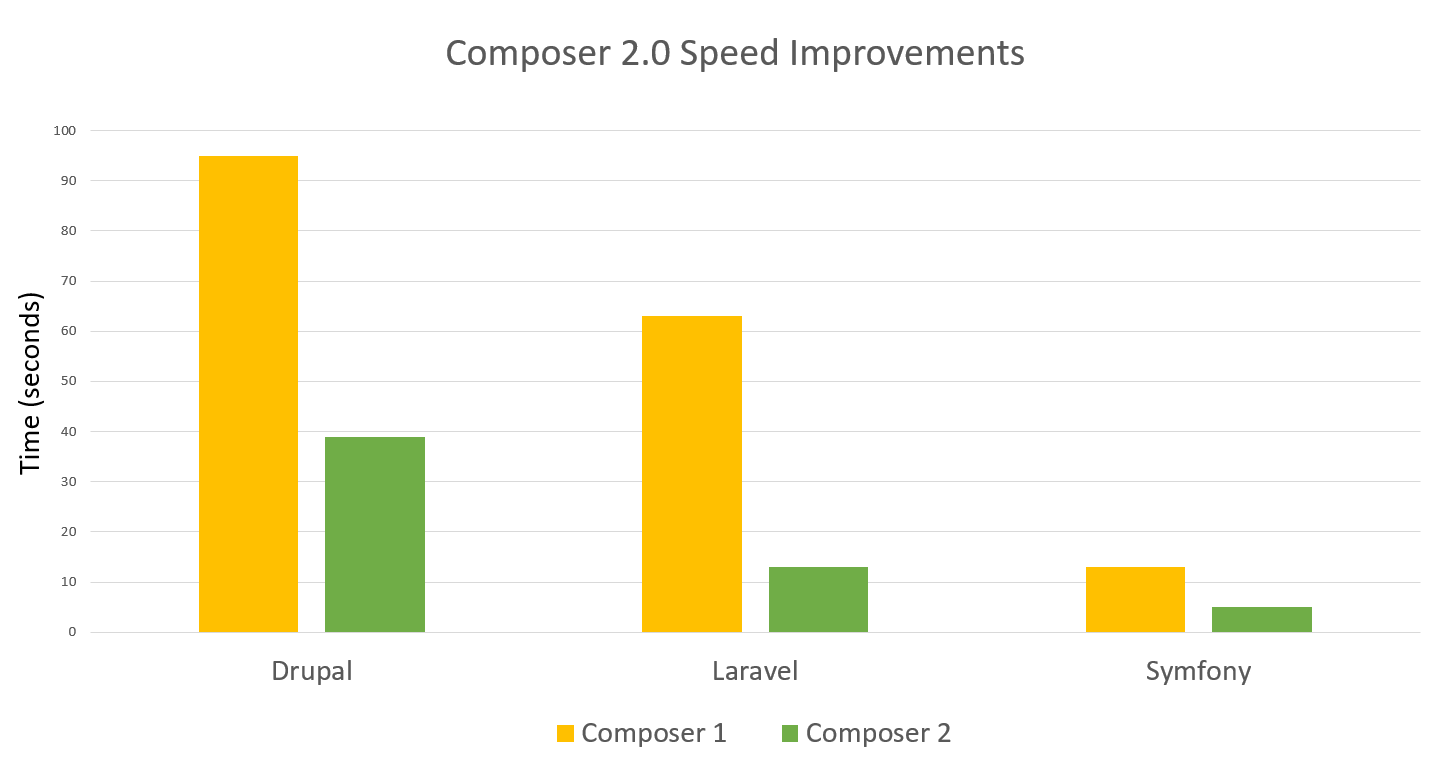
Quindi procedo all’upgrade. Tra l’altro gli improvements raggiunti con l’ultima versione sono davvero notevoli:
Laravel composer 2.0
Per cui si procede all’update.
$ composer self-update
Un paio di inghippi:
[RuntimeException] SHA384 is not supported by your openssl extension, could not verify the phar file integrity
Occorre allora rimuovere le versioni precedenti e installare l’ultima versione di Composer:
Rimozione della versione installata e sostituzione con la nuova:
Utilizzando Composer possiamo creare una nuova applicazione Laravel:
$ composer create-project laravel/laravel logisticmapper
Creating a "laravel/laravel" project at "./logisticmapper"
Installing laravel/laravel (v8.6.5)
- Downloading laravel/laravel (v8.6.5)
- Installing laravel/laravel (v8.6.5): Extracting archive
Created project in /home/marcob/IdeaProjects/PHP/camon/logisticmapper
> @php -r "file_exists('.env') || copy('.env.example', '.env');"
Loading composer repositories with package information
Updating dependencies
Lock file operations: 111 installs, 0 updates, 0 removals
- Locking asm89/stack-cors (v2.0.3)
- Locking brick/math (0.9.3)
- Locking dflydev/dot-access-data (v3.0.1)
...
- Locking webmozart/assert (1.10.0)
Writing lock file
Installing dependencies from lock file (including require-dev)
Package operations: 111 installs, 0 updates, 0 removals
- Downloading doctrine/inflector (2.0.4)
- Downloading symfony/polyfill-ctype (v1.23.0)
- Downloading symfony/polyfill-php80 (v1.23.1)
...
- Downloading phpunit/phpunit (9.5.10)
- Installing doctrine/inflector (2.0.4): Extracting archive
- Installing doctrine/lexer (1.2.1): Extracting archive
- Installing symfony/polyfill-ctype (v1.23.0): Extracting archive
...
- Installing phpunit/phpunit (9.5.10): Extracting archive
70 package suggestions were added by new dependencies, use `composer suggest` to see details.
Generating optimized autoload files
> Illuminate\Foundation\ComposerScripts::postAutoloadDump
> @php artisan package:discover --ansi
Discovered Package: facade/ignition
Discovered Package: fruitcake/laravel-cors
...
Discovered Package: nunomaduro/collision
Package manifest generated successfully.
78 packages you are using are looking for funding.
Use the `composer fund` command to find out more!
> @php artisan vendor:publish --tag=laravel-assets --ansi
No publishable resources for tag [laravel-assets].
Publishing complete.
> @php artisan key:generate --ansi
Application key set successfully.
$ cd logisticmapper
$ ls -l
totale 388
drwxrwxr-x 12 marcob marcob 4096 nov 8 15:21 ./
drwxrwxr-x 3 marcob marcob 4096 nov 8 15:21 ../
drwxrwxr-x 7 marcob marcob 4096 ott 26 17:20 app/
-rwxr-xr-x 1 marcob marcob 1686 ott 26 17:20 artisan*
drwxrwxr-x 3 marcob marcob 4096 ott 26 17:20 bootstrap/
-rw-rw-r-- 1 marcob marcob 1737 ott 26 17:20 composer.json
-rw-rw-r-- 1 marcob marcob 291109 nov 8 15:21 composer.lock
drwxrwxr-x 2 marcob marcob 4096 ott 26 17:20 config/
drwxrwxr-x 5 marcob marcob 4096 ott 26 17:20 database/
-rw-rw-r-- 1 marcob marcob 258 ott 26 17:20 .editorconfig
-rw-rw-r-- 1 marcob marcob 950 nov 8 15:22 .env
-rw-rw-r-- 1 marcob marcob 899 ott 26 17:20 .env.example
-rw-rw-r-- 1 marcob marcob 111 ott 26 17:20 .gitattributes
-rw-rw-r-- 1 marcob marcob 207 ott 26 17:20 .gitignore
-rw-rw-r-- 1 marcob marcob 473 ott 26 17:20 package.json
-rw-rw-r-- 1 marcob marcob 1202 ott 26 17:20 phpunit.xml
drwxrwxr-x 2 marcob marcob 4096 ott 26 17:20 public/
-rw-rw-r-- 1 marcob marcob 3999 ott 26 17:20 README.md
drwxrwxr-x 6 marcob marcob 4096 ott 26 17:20 resources/
drwxrwxr-x 2 marcob marcob 4096 ott 26 17:20 routes/
-rw-rw-r-- 1 marcob marcob 563 ott 26 17:20 server.php
drwxrwxr-x 5 marcob marcob 4096 ott 26 17:20 storage/
-rw-rw-r-- 1 marcob marcob 194 ott 26 17:20 .styleci.yml
drwxrwxr-x 4 marcob marcob 4096 ott 26 17:20 tests/
drwxrwxr-x 44 marcob marcob 4096 nov 8 15:22 vendor/
-rw-rw-r-- 1 marcob marcob 559 ott 26 17:20 webpack.mix.js
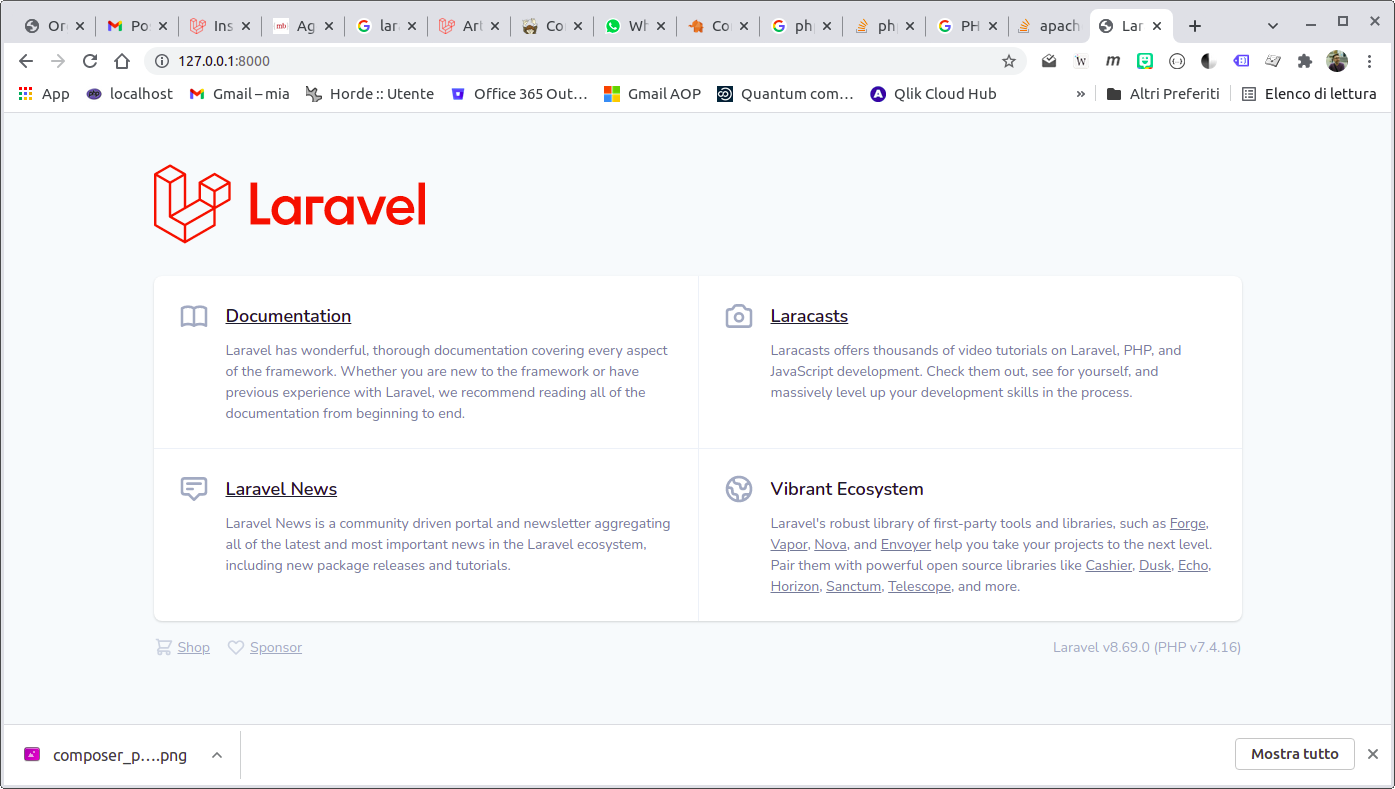
$ php artisan serve
Starting Laravel development server: http://127.0.0.1:8000
[Mon Nov 8 15:27:19 2021] PHP 7.4.16 Development Server (http://127.0.0.1:8000) started
Puntando il browser sull’url visualizzato si ottiene
Laravel nuova applicazione
Artisan è l’interfaccia a riga di comando inclusa in Laravel. Artisan esiste alla radice della tua applicazione come script artisan e fornisce una serie di comandi utili che possono aiutarti mentre crei la tua applicazione. Per visualizzare un elenco di tutti i comandi Artisan disponibili, puoi utilizzare il comando list:
$ php artisan list
Laravel Framework 6.18.8
Usage:
command [options] [arguments]
Options:
-h, --help Display this help message
-q, --quiet Do not output any message
-V, --version Display this application version
--ansi Force ANSI output
--no-ansi Disable ANSI output
-n, --no-interaction Do not ask any interactive question
--env[=ENV] The environment the command should run under
-v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug
Available commands:
clear-compiled Remove the compiled class file
down Put the application into maintenance mode
env Display the current framework environment
help Displays help for a command
inspire Display an inspiring quote
...
E via molte altre righe. È uno script molto ricco di comandi, consente di fare molte cose.
Il comando serve, come visto sopra, permette di utilizzare l’applicazione da http://127.0.0.1:8000.
Possiamo anche creare un VirtualHost Apache attraverso il quale l’applicazione risponda invece ad un indirizzo fittizio del tipo http://example-app.local/.
I VirtualHost sono definiti nella mia installazione di Apache sotto /etc/apache2/sites-available/:
Abbiamo anche specializzato la produzione dei log di accesso/errore di Apache per la nostra applicazione.
Apache va riavviato per rileggere i file di configurazione:
$ sudo service apache2 restart
Dobbiamo anche definire nel DNS, o nel file host locale del computer in cui stiamo sviluppando, una nuova entry per risolvere il nome host in un indirizzo IP; nel secondo caso:
127.0.0.1 example-app.local
Definizione del model
Il modello è una rappresentazione dello spazio dei dati nell’applicazione, che deve regolarne le dipendenze relazionali e le operazioni su di essi (CRUD).
Per implementare un modello abbiamo bisogno dell’ORM (Object Relationship Mapper) che permette di mappare precisamente il modello ad oggetti PHP con lo strato business (dati) realizzato con un DBMS.
L’ORM di Laravel si chama Eloquent ed è molto potente. Per creare una tabella dobbiamo innanzitutto fornire a Laravel le coordinate del database. Creiamo innanzituto il database:
mysql> create database logisticmapper;
Query OK, 1 row affected (0,02 sec)
mysql> create user 'logmap_user'@'localhost' identified by 'l0gm4pus3r';
Query OK, 0 rows affected (0,03 sec)
mysql> GRANT ALL ON logisticmapper.* TO 'logmap_user'@'localhost';
Query OK, 0 rows affected (0,03 sec)
$ php artisan make:migration create_client_table
Created Migration: 2021_11_08_145944_create_client_table
Ora definamo la tabella attraverso Eloquent: il comando precedente è una “migrazione”: significa una operazione di definizione di un oggetto Database e del simultaneo collegamento con lo spazio delle calsse PHP. Editando il file 2021_11_08_145944_create_client_table vediamo al suo interno una classe già predisposta da Laravel che noi dobbiamo implementare aggiungendo i campi, i vincoli e le relazioni che ci servono:
class CreateClientTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('client', function (Blueprint $table) {
$table->id()->autoIncrement();
$table->string('name');
$table->string('website')->nullable();
$table->string('email')->unique();
$table->string('mainPhoneNo');
$table->float('latitude')->nullable();
$table->float('longitude')->nullable();
$table->timestamps();
$table->softDeletes();
$table->index(['name']);
});
}
...
Le calssi elle migrazioni hanno due metodi standard: up() e down(); il primo crea la tabella, il secondo la elimina. Viene invocato uno o l’altro a seconda del comando di migrazione.
Ora, se facciamo girare la migrazione si otterrà l’effetto di creare una tabella nel database:
$ mysql -u logmap_user -p logisticmapper
mysql> desc client;
+-------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(255) | NO | MUL | NULL | |
| website | varchar(255) | YES | | NULL | |
| email | varchar(255) | NO | UNI | NULL | |
| mainPhoneNo | varchar(255) | NO | | NULL | |
| latitude | double(8,2) | YES | | NULL | |
| longitude | double(8,2) | YES | | NULL | |
| created_at | timestamp | YES | | NULL | |
| updated_at | timestamp | YES | | NULL | |
| deleted_at | timestamp | YES | | NULL | |
+-------------+-----------------+------+-----+---------+----------------+
10 rows in set (0,01 sec)
Per eliminarla, si torna indietro col comando rollback:
$ php artisan migrate:rollback
e verrà lanciato il metodo down()
Creazione di una tabella con una relazione
Una seconda tabella potrà avere un vincolo relazionale con la precedente; supponiamo di avere bisogno di una tabella di veicoli che fanno parte del parco automezzi del Cliente:
$ php artisan make:migration create_vehicle_table Created Migration: 2021_11_10_154349_create_vehicle_table
Implementiamo i campi della tabella:
<?php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateVehicleTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('vehicle', function (Blueprint $table) {
$table->id();
$table->string('model');
$table->string('licensePlate');
$table->integer('year');
$table->bigInteger('client_id')->unsigned();
$table->foreign('client_id')->references('id')->on('client');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('vehicle');
}
}
Nota bene: nella definizione dell’identificativo del record, la convenzione con Eloquent è che se dichiariamo un campo id, per Eloquent sarà implicitamente:
integer
not null
auto incrementing
cioè verrò dichiara auto_increment nella definizione in DDL.
È comunque consentito di derogare dalla convenzione quando si vuole (esempio, una chiave che non si chiama id, che non è autoincrement e che non è un numero intero).
In particolare, il metodo $table->foreign() consente di creare la relazione di chiave esterna. lanciamo la mirgrazione:
Nella nuova versione di Laravel, le chiavi primarie sono definite come binginteger unsigned. Qualunque campo che debba riferirsi a questi campi va dichiarato allo stesso modo, biginteger unsigned. Vedi ad esempio l’attributo vehicle.client_id che ospita la chiave esterna di client.id.
Se guardiamo nel database vedremo:
mysql> desc vehicle;
+--------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| model | varchar(255) | NO | | NULL | |
| licensePlate | varchar(255) | NO | | NULL | |
| year | int | NO | | NULL | |
| client_id | bigint unsigned | NO | MUL | NULL | |
| created_at | timestamp | YES | | NULL | |
| updated_at | timestamp | YES | | NULL | |
+--------------+-----------------+------+-----+---------+----------------+
E alla fine la creazione del modello
Artisan creera la classe collegandola alla tabella del database:
$ php artisan make:model Client --migration
Model created successfully.
Created Migration: 2021_11_10_164311_create_clients_table
La nuova classe la troviamo in app/Models/Client.php:
All’inizio è veramente neat:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
class Client extends Model
{
use HasFactory;
}
Utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Lo facciamo per migliorare l'esperienza di navigazione e per mostrare annunci personalizzati. Il consenso a queste tecnologie ci consentirà di elaborare dati quali il comportamento di navigazione o gli ID univoci su questo sito. Il mancato consenso o la revoca del consenso possono influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.











Commenti recenti