Mi sono imbattuto in un comportamento piuttosto curioso utilizzando DBeaver con un server MySQL locale. All’avvio di DBeaver, il tentativo di connessione falliva con il messaggio: La cosa sorprendente era che bastava aprire un terminale …
Per anni avevo sentito ripetere che Docker è una virtualizzazione leggera. È una frase comoda per iniziare, ma in realtà è fuorviante. L’ho capito nel modo migliore: cercando di capire perché MySQL si comportasse in …
Aprendo Thunderbird mi è comparso un avviso che invitava a intervenire entro il 21 luglio 2026 per continuare a ricevere gli aggiornamenti ESR (Extended Support Release). Partiamo con le istruzioni operative per chi sa già …
Negli ultimi tempi termini come LLM, embedding e database vettoriali sono usciti rapidamente dall’ambito della ricerca e sono diventati argomenti quasi quotidiani. Sono mattoncini coi quali possiamo costruire sistemi capaci di interrogare grandi collezioni di …
Ho condotto un esperimento di scrittura di software per analizzare i risultati di una esportazione delle mie conversazioni con ChatGPT. Ma ho deciso di aiutarmi nell’analisi con un Large Language Model che sicuramente sa fare molto bene questo lavoro e in più con un LLM in locale, per vedere come funziona.
Il 12 marzo 2019, l’evento Web@30 del CERN ha dato il via alle celebrazioni in tutto il mondo. Sir Tim Berners.Lee, Robet Caillau e altri pionieri ed esperti del Web hanno condiviso la loro visione sulle sfide e le opportunità portate dal Web. L’evento è stato aperto dal Direttore Generale del CERN Fabiola Gianotti ed è stato organizzato dal CERN in collaborazione con le due organizzazioni fondate da Berners-Lee: la World World Wide Web Foundation e il World Wide Web Consortium (W3C).
Utilizzo di tanto nj tanto un virtualizzatore per poter operare su sistemi Windows. Il software originariamente sviluppato da Sun Microsystem è ormai da anni passato sotto Oracle e fornisce delle macchine virtuali sulle quali si installa una versione di Windows (io attualmente utilizzo una Windows 7 da 64 bit).
Il problema è sorto quando al normale avvio OracleVM Virtualbox, il software mi ha avvisato del rilascio della versione 5.2.22. Lo stesso avviso mi compariva nel gestore pacchetti (Aggiornamenti Software) di Ubuntu. Ho provato prima ad installare la nuova versione dal package manager e ho ottenuto un problema “Software da sorgenti non fidate”. Problema analogo se scaricavo ed eseguivo da solo il .deb.
Il problema è dovuto al cambio della chiave crittografica per collegarsi al repository della Oracle (virtualbox.org che non è tra i repository ufficiali fidati di Ubuntu). Per scaricare la nuova chiave:
La chiave viene aggiunta al repository delle chiavi crittografiche: ripetendo l’installazione da “Aggiornamenti software” la nuova versione di OracleVM Virtualbox viene finalmente installata.
Il comando apt-key è usato per gestire la lista delle chiavi usate da apt (Advanced Package Tool, il gestore pacchetti delle distribuzioni Debian e derivate) per autenticare i pacchetti. I pacchetti che sono stati autenticati usando queste chiavi vengono considerati fidati.
Ho sviluppato un piccola applicazione Android e la voglio testare sul mio dispositivo.
da dispositivo: Abilitare il debug USB (Impostazioni > Opzioni Sviluppatore > Debug USB -> ON)
da computer: da linea di comando digitare
$ adb devices
List of devices attached
QLF7N16406002695 device
Se Ubuntu non dovesse mostrare il device, dovete istruire l’OS aggiungendo il vostro utente al gruppo plugdev
sudo usermod -aG plugdev $LOGNAME
e poi bisogna aggiungere le udev rules per la ricognizione del dispositivo Android alla porta usb
apt-get install android-sdk-platform-tools-common
udev è il sottosistema di Linux che gestisce gli eventi generati dalle periferiche: esso si accorge quando tentate per esempio di collegare una pendrive USB o una scheda di rete.
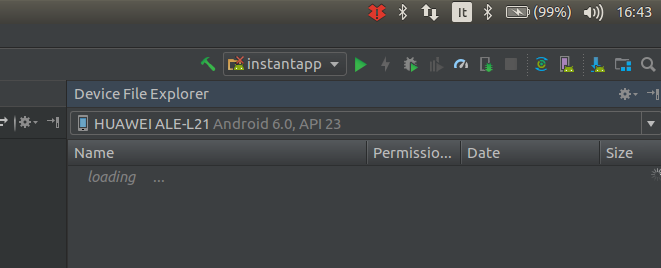
Quindi in basso a dx attivare la tab Device File Explorer come in figura
Android e IntelliJ IDEA – elenco dei dispositivi collegati a USB
In alto a destra compare la tab del dispositivo con tutto il contenuto del file system:
Android e IntelliJ IDEA – Il dispositivo viene correttamente visulizzato nella lista dei device
Per installare adb
$ sudo apt-get install adb
Risorse web Android
Per installare Android Studio, seguire questo sito. Oppure, se siete utilizzatori di IntelliJ IDEA, il modulo Android è già compreso.
Sulla configurazione del device di test, questo sito.
Affinché le date e il tempo dell’applicazione Laravel siano sincronizzate con l’orologio del server occorre agire sui file di configurazione dell’applicazione. Ovviamente questo non è detto sia ciò che si desidera perché per esempio vogliamo che sia un jet lag tra il server e l’applicazione. In ogni caso, il file da modificare è uno soltanto: config/app,php:
Laravel consente di proteggere con semplicità le applicazioni dagli attacchi cross site (CSRF – Cross Site Request Forgery). I CSRF sono un tipo di sfruttamento malevolo dei programmi web in cui comandi non autorizzati vengono eseguiti al posto di un utente autenticato.
Attenzione: In particolare questi attacchi si possono verificare anche se non c’è alcuno strato di protezione con autenticazione tra il browser e il modulo HTML.
Laravel realizza nel modo che segue la protezione: esso genera automaticamente una stringa cosiddetta “gettone” (token) CFRS per ogni sessione attiva (quindi per ogni browser aperto sull’applicazione). Questo gettone viene usato per verificare che l’utente che ha fatto la richiesta sia lo stesso che ha acceduto all’inizio all’applicazione. Non serve che ci sia un’autenticazione, funziona anche per una sessione non autenticata in cui semplicemente il server invia un cookie di sessione al primo accesso anche senza necessariamente legarlo da un utente fisico nel database.
Ogni volta che si definisce una form HTML nell’applicazione, dovrebbe essere incluso un token CSFR in un campo nascosto (hidden) cosicché il middleware di protezione possa validare la richiesta. Per generarlo con Blade è facile: basta usare la direttiva @csrf per generare il campo:
Il metodo incluso nel gruppo middleware (si veda il metodo /app/Http/Middleware/VerifyCsfrToken.php) verificherà automaticamente che l’input proveniente dalla richiesta corrisponda al token salvato nella sessione.
Se non si agisce in questo modo, Laravel semplicemente blocca l’applicazione sollevando un errore HTTP 419:
Lo strumento delle migrazioni di Laravel è molto comodo per definire le tabelle di uno schema ma anche per le conseguenti ricadute positive sull’ORM Eloquent ai fini di produrre query con le join già fatte.
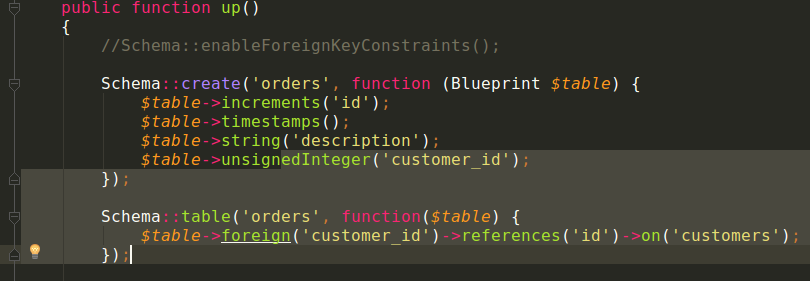
Mi riferisco al fatto che è possibile definire i vincoli di chiave esterna (foreign key). Solo che la definizione è un po’ “tricky”. Prendiamo questo esempio: due tabelle customers e orders con una relazione di chiave esterna da customers a orders:
Definizione della tabella customers, un solo attributo chiave, implicitamente definito con increments()C’è un attributo di riferimento a customer_id
Se faccio girare lo script di migrazione, che si incarica di creare gli oggetti nello schema del DB ottengo un errore:
Illuminate\Database\QueryException : SQLSTATE[42000]: Syntax error or access violation: 1075 Incorrect table definition; there can be only one auto column and it must be defined as a key
L’errore è abbstanza grave: abbiamo tentato di creare due chiavi: la prima con il campo id la seconda con il campo customer_id.
All’inizio credevo che fosse un problema della definizione del constraint, e così l’ho scorporato in una seconda invocazione separata: Schema::table eccetera. Invece il problema era com’è stato definito il campo, infatti ho lo stesso errore anche togliendo la definizione del contraint. Il problema è la dimensione del campo:
$table->unsignedInteger('customer_id', 10);
Ora lo spiego qui e sembra ovvio, ma trovarlo, come tutti i buoni martorei, richiede tempo: il metodo $table->unsignedInteger() ha un secondo parametro che non è affatto la dimensione del campo, che lui si regola automaticamente, ma è – disgraziatamente…
public function unsignedInteger($column, $autoIncrement = false)
{
return $this->integer($column, $autoIncrement, true);
}
… l’informazione $autoIncrement. Essendo disgrazatamente 10 == true in PHP, il campo così viene dichiarato come autoincrement e quindi come chiave primaria generando l’errore. Invece con questa dichiarazione:
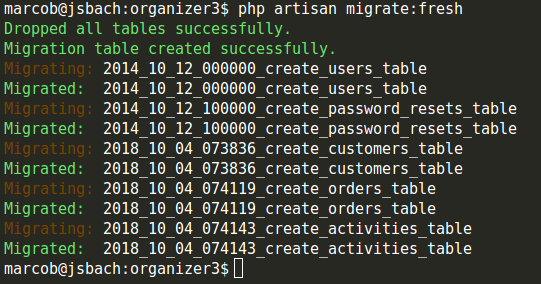
La migrazione termina correttamente
In origine, in ogni caso, c’era la mia errata invocazione del metodo.
Il premio Nobel per la Fisica 2018 è stato assegnato a lavori sulle pinze laser, – ad Arthur Ashkin, una tecnologia che consente di spostare in modo estremamente preciso oggetti microscopici come i virus utilizzando la pressione elettromagnetica della luce – e sugli impulsi ultrabrevi (Mourou e Strickland). Con questa tecnica si ottengono impulsi della durata di un femtosecondo (10-15 secondi).
Per avere una idea di quanto breve sia il femtosecondo si pensi che in 1 secondo ci stanno tanti fs quanto il numero di secondi nell’età dell’universo (circa 1018):
1 s : 1 fs = Età dell’universo : 1 s
Il laser a femtosecondo, così chiamato in breve, viene utilizzato nella chirurgia dell’occhio, per la sua capacità di dosare in modo precisissimo l’energia degli impulsi.
Oggi mi sono trovato davanti un problema sconosciuto: ho aperto una finestra (nella fattispecie, l’applet Java di MirthConnect) e ho poi normalmente commutato su un’altra finestra da quel momento non vedevo più la finestra Java nell’elenco dei task che vengono visualizzati con ALT-TAB:
La finestra in foreground non c’è nell’elenco dei task.
Se minimizzo la finestra di Mirthconnect non riesco più a recuperarla… Come posso fare ad accedervi nuovamente? il Linux ci sono due bei strumenti:
wmctrlinteract with a EWMH/NetWM compatible X Window Manager: consente di fare cose meravigliose per automatizzare il desktop tramite script bash, ma in questo caso voglio solo vedere l’elenco delle finestre attive:
Come si può notare le finestre attive sono più di quelle mostrate con ALT-TAB; in particolare ho evidenziato le due finestra scomparse: mi serve accedere ad una di queste due (l’ultima)
C’è poi un secondo tool molto potente:
xdotoolfake keyboard/mouse input, window management, and more: questa utility simula l’uso della tastiera e di movimenti del mouse prodotti con uno script bash! Nel mio caso mi serve solo per sapere quale finestra è associata al processo che vedo essere quello sotto il quale gira il client Mirtchconnect
Utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Lo facciamo per migliorare l'esperienza di navigazione e per mostrare annunci personalizzati. Il consenso a queste tecnologie ci consentirà di elaborare dati quali il comportamento di navigazione o gli ID univoci su questo sito. Il mancato consenso o la revoca del consenso possono influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.









Commenti recenti